用于图像语义分割的GAU与PPM
简单记录一下用于图像语义分割的2个模块
1. GAU(Global Attention Upsample, 全局注意力上采样模块)
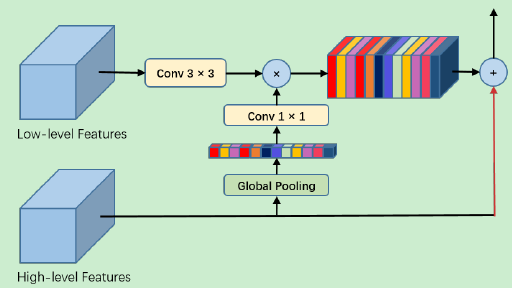
全局注意力上采样模块 (GAU)通过全局池化将高层特征作为低层特征的加权计算的指导,提取高层次特征的全局上下文信息。
实现如下所示:
对低层次特征执行3×3的卷积操作,同时减少CNN特征图的通道数;
从高层次特征经过全局平均池化生成的全局上下文信息依次经过 1×1 卷积、批量归一化 (batch normalization) 和非线性变换操作 (nonlinearity),然后再与低层次特征相乘;
最后,高层次特征与加权后的低层次特征相加并进行逐步的上采样过程;
GAU模块不仅能够更有效地适应不同尺度下的特征映射,还能以简单的方式为低层次的特征映射提供指导信息。
基于keras的代码实现:
# GAU(Global Attention Upsample, 全局注意力上采样模块)
# 低层特征图low_fm进行3*3卷积
# 高层特征图high_fm进行GAP、1*1,再与低层特征图进行相乘操作、批归一化、非线性激活
# 将上述得到的低层特征图与高层特征图进行相加融合
def GAU(low_fm, high_fm, filters):
n, h, w, c = low_fm.get_shape().as_list()
# 3*3
low_fm = Conv2D(filters=filters, kernel_size=3, strides=1, padding='same',
use_bias=False, dilation_rate=(1, 1))(low_fm)
# GAP
high_fm_up = GlobalAveragePooling2D()(high_fm)
# 1*1
high_fm_up = Reshape(target_shape=[1, 1, int(high_fm_up.shape[-1])])(high_fm_up)
high_fm_up = tf.image.resize_bilinear(image=high_fm_up, size=[h, w], align_corners=True,
name='resize_bilinear')
high_fm_up = Conv2D(filters=filters, kernel_size=1, strides=1, padding='same',
use_bias=False, dilation_rate=(1, 1))(high_fm_up)
# 融合
x = Multiply()([low_fm, high_fm_up])
x = BatchNormlization()(x)
x = Activation('relu')(x)
# 输出
high_fm = tf.image.resize_bilinear(image=high_fm, size=[h, w], align_corners=True,
name='bilinear')
out = Add()([x, high_fm])
return out
2. PPM(Pyramid pooling module, 金字塔池化模块)
PPM目的是为了聚合不同特征层的上下文信息,以提高网络获取全局信息的能力,在不同的尺度下以保留全局信息使用不同多尺度的pooling操作,比起普通的pooling操作更能保留全局上下文信息;
具体做法为:在原始特征图上使用不同尺度的池化,得到多个不同尺寸的特征图,再在通道维度上拼接这些特征图 (包含原始特征图),最终输出一个糅合了多种尺度的复合特征图,从而达到兼顾全局语义信息与局部细节信息的目的;
示意图如下所示:
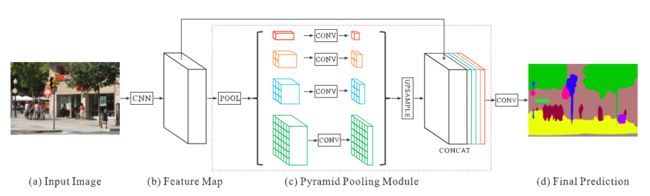
(a)图为单幅原始输入图像;
(b)图为通过CNN提取的原始特征图;CNN模块可以根据需要自行选择,论文中给出的该特征图尺寸为6*6;
(c)图为PPM模块:对(b)特征图进行不同尺度的池化操作,得到多个不同尺寸的特征图,然后对得到的特征图进行上采样操作,恢复至原始特征图大小,最后在通道维度上进行拼接,得到最终的融合了多种尺度的复合特征图;
例如图中为4个不同的池化操作,分别为红、橙、蓝和绿来表示:
红:使用6×6的池化,输出尺寸为1×1,再通过双线性插值上采样至6×6;
橙:使用3×3的池化,输出尺寸为2×2,再通过双线性插值上采样至6×6;
蓝:使用2×2的池化,输出尺寸为3×3,再通过双线性插值上采样至6×6;
绿:使用1×1的池化,输出尺寸为6×6 。
(d)图为最终预测结果, 通过1*1卷积调整通道,以实现像素级别的分类。
基于keras的代码实现:
以下代码用于语义分割,其中模型网络使用的是ghostnet作为主干网络实现;
其中的双线性插值上采样可参考GAU模块的代码,以下代码需要根据实际需要进行更改;
# PPM(Pyramid pooling module, 金字塔池化模块)
# bin_size=[]为池化尺寸, 根据需要自行选择
def PPM(inputs, bin_sizes=[5, 9, 13]):
n, h, w, c = inputs.get_shape().sa_list()
# 1*1降维
inputs = Conv2D(filters=c // 4, kernel_size=1, strides=1, padding='same',
use_bias=False, dilation_rate=(1, 1))(inputs)
inputs = BatchNormlization()(inputs)
inputs = Activation('relu')(inputs)
concat_list = [inputs]
# 池化
for bin_size in bin_sizes:
x = AvgPool2D(pool_size=[bin_size, bin_size], strides=(1, 1), padding='same')(inputs)
concat_list.append(x)
net = Concatenate(axis=-1)(concat_list)
net = Conv2D(filters=c, kernel_size=1, strides=1, padding='same',
use_bias=False, dilation_rate=(1, 1))(net)
net = BatchNormlization()(net)
net = Activation('relu')(net)
return net