CV-学习笔记
一.简介
1.什么是机器学习

![]() 代表:模型的参数
代表:模型的参数
![]() 代表:输入(图片/音频等)
代表:输入(图片/音频等)
2. 深度学习是一个综合技术
(1)卷积:conv 池化:pool 全连接:fully-connected layers
(2)relu激活函数
(3)新的网络层(DWConv, SPConv, Group Convolution)和结构(Skip Connection, Dense Connection)
(4)防止过拟合技术(Dropout,image Augmentation)
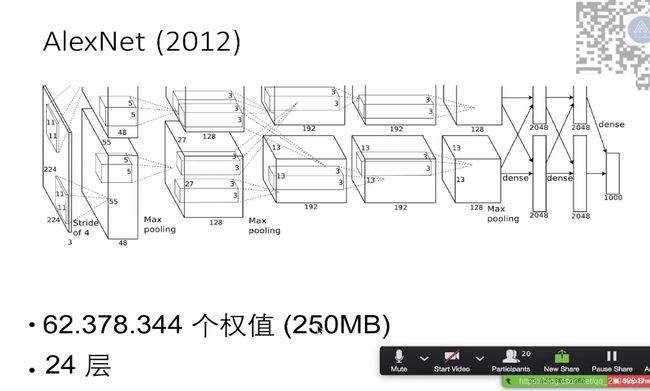
3.AlexNet网络结构
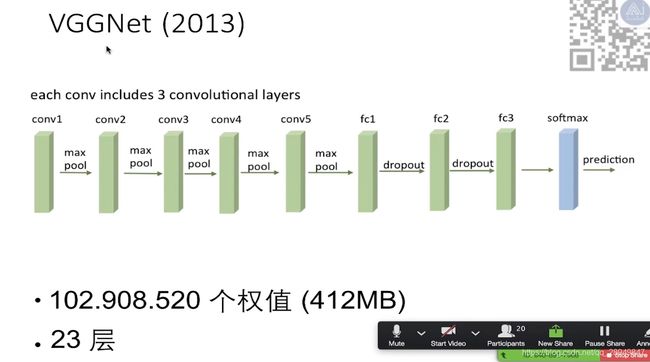
4. VGGNet网络结构
5. GoogLeNet网络结构

googLenet中大量使用了inception结构
6. inception 网络结构

 代表输入
代表输入
inception中大量使用了1*1的卷积,1*1卷积的作用:把输入层的通道做缩放,可以减少计算量.
eg: 输入 3*3*100 通过 1*1卷积后变为 3*3*10的,可以大量减少计算量,这也是为什么googLeNet模型只有28兆的原因.
7. resnet网络结构

8. 环境版本
tensorflow:1.8.0
keras:2.1.5
pytorch:0.4.1
numpy中文手册: https://www.numpy.org.cn/article/advanced/numpy_exercises_for_data_analysis.html
keras手册:https://github.com/yuan776/deep-learning-with-python-cn/blob/master/SUMMARY.md
pytorch 不分gpu和cpu版本,安装一个就行
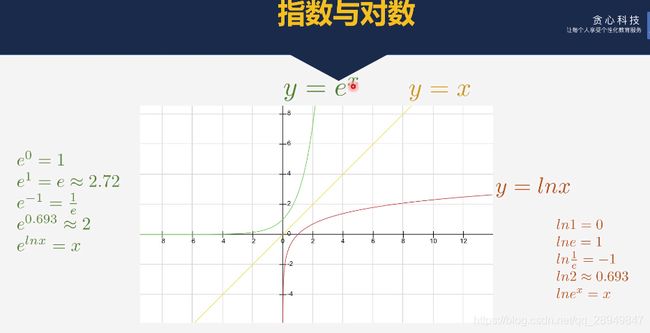
9. 指数函数
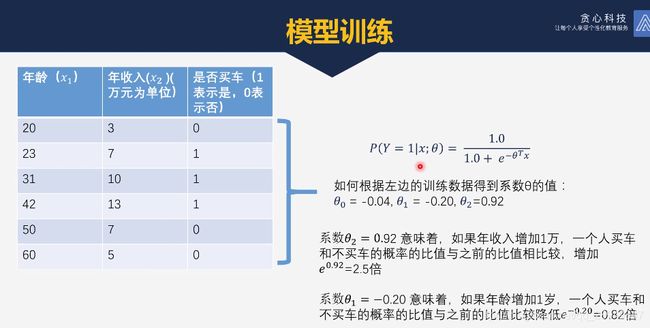
10. 逻辑回归示例:

上面的thea0,thea1, thea2是经过训练得到的.
解答代码:
from sklearn import linear_model
x = [[20, 3],
[23, 7],
[31, 10],
[42, 13],
[50, 7],
[60, 5]]
y = [0,
1,
1,
1,
0,
0]
# 构建逻辑回归模型
lr = linear_model.LogisticRegression()
# 训练逻辑回归模型
lr.fit(x, y)
# 预测28岁,年收入8万的是否买车
testx = [[28, 8]]
label = lr.predict(testx)
print('预测的类别为:', label)
label_value = lr.predict_proba(testx)
print('预测的类别的概率:', label_value)
# 输出:
# 预测的类别为: [1]
# 预测的类别的概率: [[0.15084679 0.84915321]]
11. 求导公式

12.梯度下降法
1. 求偏导

2. 梯度
梯度是一个向量,不是一个数, 偏导是一个数.把所有的偏导数放到一个向量里,就是梯度,如下:

3. 批处理梯度下降

一个batch,求平均,然后进行学习率更新.
优缺点:

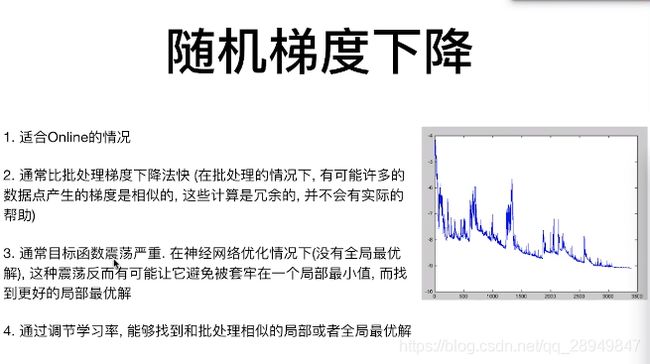
4. 随机梯度下降

每一个data,都进行梯度更新
优缺点:
5. 迷你批处理梯度下降
优缺点:

6. 传统梯度下降的问题


特征的值:是什么???

13. 垃圾短信项目
import pandas as pd
from sklearn import linear_model
# 把短信文本变为列向量
from sklearn.feature_extraction.text import TfidfVectorizer
df = pd.read_csv('./***.txt', delimiter='\t', header=None)
# 文本的第一列是label,后面是短信内容
y, X_train = df[0], df[1]
vectorizer = TfidfVectorizer()
# 把短信文本变为列向量
X = vectorizer.fit_transform(X_train)
lr = linear_model.LogisticRegression()
lr.fit(X, y)
# 给定两个短信,测试这两个短信是否为垃圾短信
testX = vectorizer.transform(['URGENT? Your mobile No. 1234 was awarded a Prize.'
'Hey honey, whats up?'])
predictions = lr.predict(testX)
print(predictions)
13. 激活函数

网络精简图:

14. softmax

softmax值溢出:

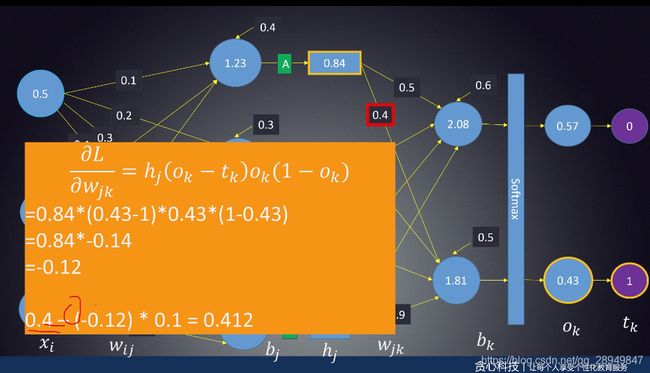
15. BP误差反向传播
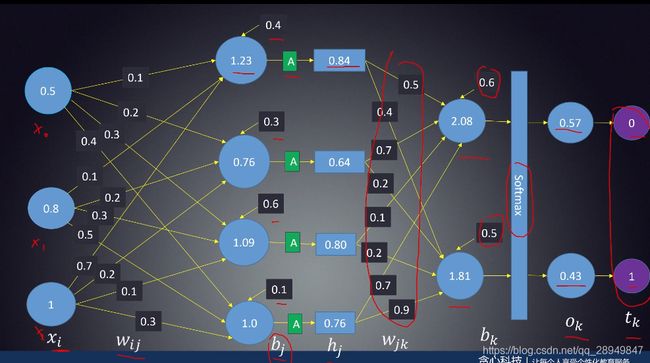


说明:
减小后的权值为0.488,减小前为0.5

16.损失函数
定义: 在深度学习中,损失函数是用来衡量一组参数的质量的函数,衡量的方式是比较网络输出和真实输出的差异
命名:
1. 损失函数:loss function
2. 价值函数:cost function
3. 目标函数:objective function
4. 误差函数:error function
注意:
损失函数是在训练时进行使用,不是测试数据时使用
特性:

17. 回归问题中常用的损失函数
绝对误差函数Absolute value , L1-norm:

不能区分正负,因为取得是绝对值;在0点处不可导
outliers:就是实际中出现了跟训练集相差很大的数据,对最后的结果影响不大
方差函数: Squareerror, Euclidean loss, L2-norm:

18. 分类中常用的损失函数:
分类(猫狗/垃圾邮件):hinge loss ,

(1) softmax作用:
将输出转换为0 - 1 之间的概率,所有类别概率和为1
(2)独热编码

(3)Cross-entropy loss交叉熵

说明:
k:表示类别数
y:表示label的对应
lk:表示上面 output里的数
S(lk):表示probabillity层的数

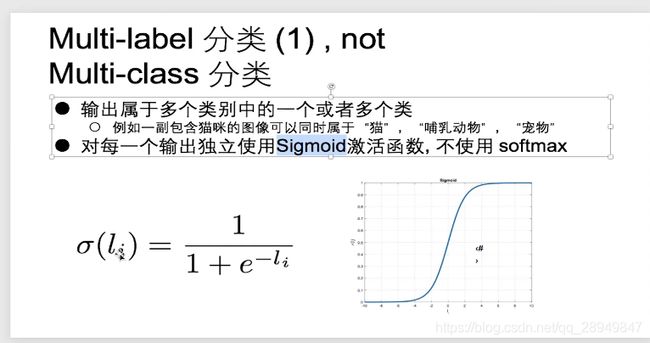
19. Multi-label分类 not Multi-class分类

20. 正则化

21. 梯度消失
问题分析:
梯度下降法依靠理解系数的微小变化对输出的影响来学习网络的系数的值.
如果一个系数微小变化对网络的输出没有影响或者影响很小,那么就无法知晓如何优化这个系数,或者优化很慢.造成训练困难.
使用梯度下降法训练神经网络,如果激活函数具备将输出值的范围相对于输入的值大幅压缩,那么就会出现梯度消亡.
eg:双曲正切函数(tanh)将负无穷 到 正无穷的输入压缩到-1 到 +1 之间,除开在输入为 -6 到 +6之间的值,其他输入的值对应的梯度都非常小,接近0.

蓝线:tanh函数
红线:tanh函数的导数
(2)梯度消亡解决方案

(2)relu激活函数

绿色:求导线
问题:为什么不选用 f(x)= x???,非得把小于0的置0呢?

22. 过拟合
(1) 过拟合解决方案
- dropout
- L2正则化
- L1正则化
- MaxNorm
23. L2正则化

24. L1正则化

25. MaxNorm最大范数约束

26. 神经元系数初始化
bias(偏置系数):初始化为0
普通系数:初始化为
其中N为神经元的输入向量的元素个数