【Transformer学习笔记】DETR:将transformer引入目标检测领域
之前我们有讲过如何将transformer引入CV领域,想去看看的同学可以点击这里:
【Transformer学习笔记】VIT解析
VIT论文中最后的实验解决的是一个多分类任务。那么transformer的结构能不能用来解决目前cv领域大热的目标检测问题呢?
DETR,DEtecion TRsformer就是为了回答这个问题而诞生的。而且它的做法并不是只是直接用transformer结构将传统目标检测网络中的backbone给替换了,它还提出了一种基于set prediction的目标检测新思路。
原论文地址:End-to-End Object Detection with Transformers
传统的目标检测思路
在传统的目标检测方法中,主要可以分为one-stage和two-stage两种。
目标检测中主要解决两个问题:找到物体位置和对物体进行分类。
在锚框的作用就是筛选出ROI(感兴趣区域,也就是可能包含物体的区域)。
在现有的大部分目标检测房中共同的思想就是根据一些统计得到先验知识,生成一系列大小位置预先设定好的的初始化锚框。如下图:
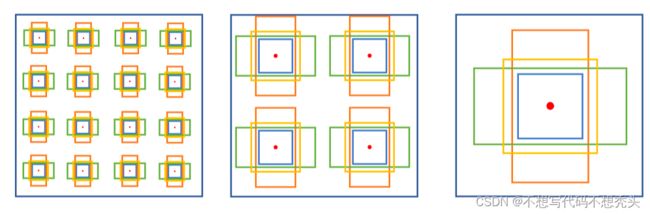
这些初始化锚框数量动辄成百上千,而最后一张图片中的需要检测的目标数量基本不会上百,所以使得如NMS(非极大抑制)等消除多余锚框的后处理方法变为了必须的组件。
另外,这种方法中还存在一个问题,就是把一部分高于置信度预知的锚框作为正样本,剩下的作为负样本,经常会产生负样本数量远远多于正样本的情况,影响训练效果。
Set Prediction
在正式介绍DETR的结构前,我想先花点篇幅介绍一下它的一个非稠密锚框的生成方式。
在DETR中,采用了一种新的非手动预先生成锚框的方式。如前面所说,其实一张图中也许总共的目标数量并不会大于100个,DETR的做法就是预先准备100个可以随着网络一起学习的queries,每个query负责预测一个物体的长宽还有中心点的坐标。最后每个query将对应生成一个anchor box,使用一个四元组表示,四元组中的长宽,xy坐标都是相对于图片长宽进行归一化的后的数值。
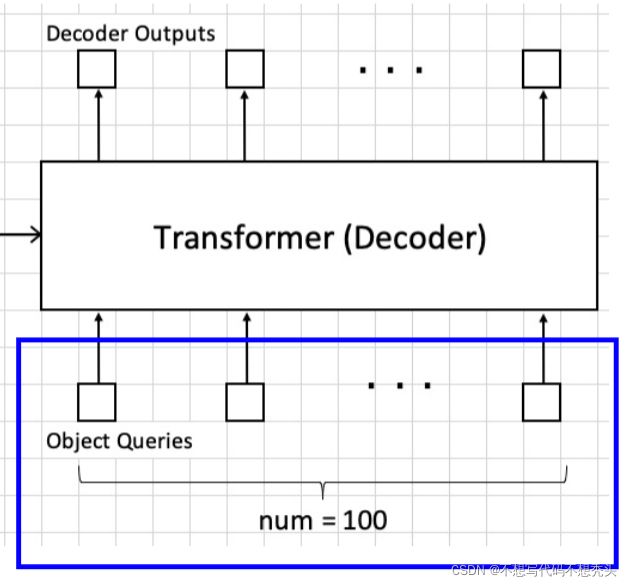
实际情况下图片中的ground truth,也就是目标的个数并不总是和queries的数量相等。因此最后anchor box中分类的数量实际上还增加了一个背景类,当ground truth数量少于queries的数量时,那么有一部分的anchor box的类别就是【背景】。
那么如果物体数量大于100个咋办?emm那就把预先准备的queries数量增大就好了嘛。
DETR结构解析

值得一提的是detr它并不是一个纯粹的transformer结构网络。
之前在讲VIT的时候有提到过,对图像进行全局transformer的时候能够关注全局视野,但是也会带来一些的缺陷,比如无法保留图像的尺度不变形和平移不变形,还有局部特征提取能力没有那么强等等。
但是目标检测任务中,局部特征细节是十分重要的。DETR的做法就是还是使用resnet来进行特征提取,之后才算是正式进入了transformer的结构中。
和VIT只有编码器的结构不同,DETR中既有编码器又有解码器,编码器可以理解为将输入的特征图(注意,输入的是已经经过resnet处理的特征图)进行编码,而解码器是将queries和编码器编码的特征进行交互融合,最后得到的输出经过检测头后输出对应anchor box。
编码器
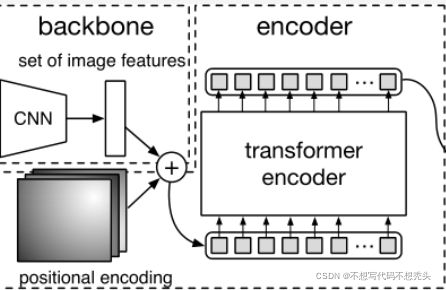
当一张图片输入detr中,最先经过的是resnet网络,当然此处的resnet中的最后的池化层和全连接层被去除了,所以输出是一个长宽比输入图片小,维度比输入图片高的抽象特征图。
依然,对于提取到的大小为 ( W , H , C ) (W,H,C) (W,H,C)的特征图,我们需要对特征图每个位置加上特征编码。特征编码的方式有很多,但是最终的目的都是让输入的特征具有相对位置信息。
剩下的就是我们熟悉的transformer老套路了。首先是我们喜闻乐见的embedding了,经过embedding以后,输出的新特征图大小为 ( W , H , e m b e d _ d i m ) (W,H,embed\_dim) (W,H,embed_dim)。特征图中每个 ( i , j , : ) (i,j,:) (i,j,:)都是相当于VIT中的一个patches。之后经过多头注意力机制进行patches之间的信息融合,输出大小仍为为 ( W , H , e m b e d _ d i m ) (W,H,embed\_dim) (W,H,embed_dim)的有更加丰富信息的特征图。
同样,DETR中也有很多个encoder layer,最后的输出进入解码器。
解码器
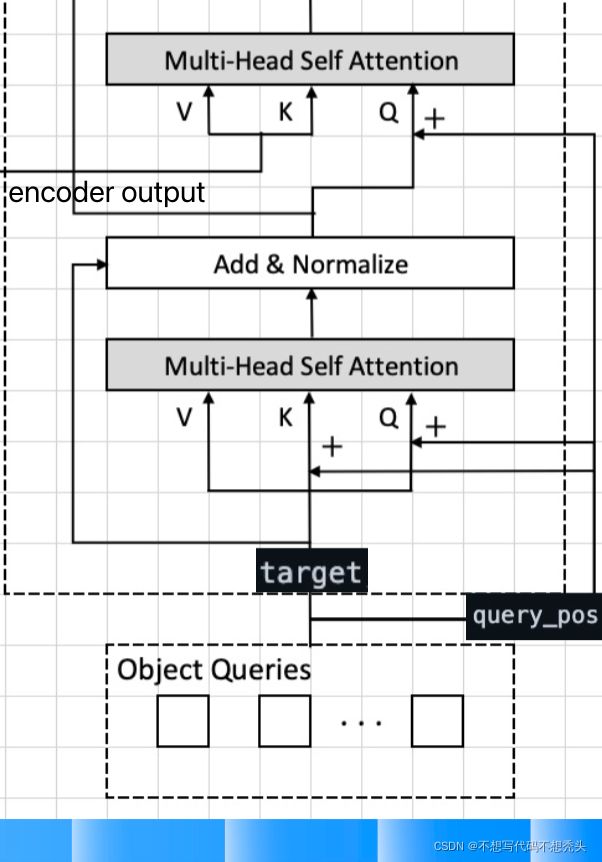
一般而言,可以使用embedding的参数来生成可训练的对应大小的queries。queries也需要加入位置编码(图中的query_pos)。解码器中的位置编码不只是在输入的时候加入,可以看上图,它在queries的自注意力机制的K和Q,queries和编码器输出的交互注意力机制中也都引入了query_pos。
在queries和编码器输出的交互注意力机制中,DETR的做法就很像最初版的的transformer了。来源解码器的特征作为Q,去查询来源于编码器的K和V,也很符合【让queries去特征图中查找特征形成锚框】的直觉。
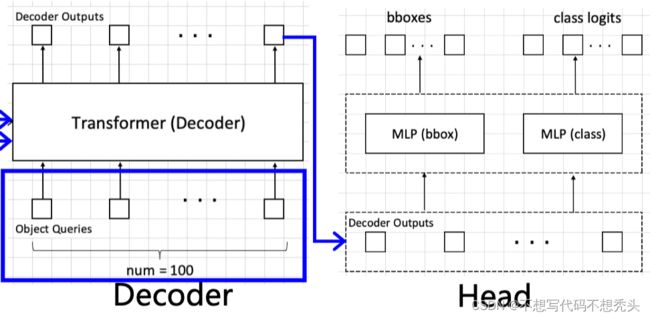
最后decoder的输出将分别进入两个MLP进行分类和回归。
损失函数
还有一个问题,那就是set predition得到的anchor box是无序的,怎么和每个ground truth对应起来呢?
一个比较直观的思路就是每个anchor box都去找和自己匹配度最高的那个ground truth。为了解决这种涉及寻找两个集合最优匹配的问题,DETR采用了匈牙利算法,具体的原理可以去看看相关文章,在这里我们只需要知道他能解决最优匹配问题就好了。
得到最优匹配以后,就可以计算位置loss和分类loss了。DETR的loss由两部分构成
- 利用交叉熵损失计算的分类损失。
- 利用GIOU和L1距离计算得到的位置回归损失。
总结
笔者认为DETR的贡献并不只是把transformer引入了目标检测领域,更重要的是它的set prediction的思想,相对于预先生成锚框的方法,这是一种直观简洁的新设计,很可能引发一波新的目标检测浪潮。