【笔记】2022.06.20 python数据分析三大神器numpy、pandas、matplotlib
0. 引入案例
RIGHT Example:
names = ['孙悟空', '李元芳', '白起', '狄仁杰', '达摩']
courses = ['语文', '数学', '英语']
import random
scores = [[random.randrange(60, 101) for _ in range(3)] for _ in range(5)]
print(scores)
# [[100, 97, 76], [91, 79, 66], [84, 78, 71], [87, 81, 96], [73, 71, 88]]
def mean(nums):
"""求均值"""
return sum(nums) / len(nums)
def variance(nums):
"""求方差"""
mean_value = mean(nums)
return mean([(num - mean_value) ** 2 for num in nums])
def stddev(nums):
"""求标准差"""
return variance(nums) ** 0.5
# 统计每个学生的考试平均分
for idx, name in enumerate(names):
temp = scores[idx]
avg_score = mean(temp)
print(f'{name}考试平均分为:{avg_score:.1f}分')
'''
孙悟空考试平均分为:91.0分
李元芳考试平均分为:78.7分
白起考试平均分为:77.7分
狄仁杰考试平均分为:88.0分
达摩考试平均分为:77.3分
'''
# 统计每门课的最高分、最低分、标准差
for idx, course in enumerate(courses):
temp = [scores[i][idx] for i in range(len(names))]
max_score, min_score = max(temp), min(temp)
print(f'{course}成绩最高分:{max_score}分')
print(f'{course}成绩最低分:{min_score}分')
print(f'{course}成绩标准差:{stddev(temp):.1f}分')
'''
语文成绩最高分:100分
语文成绩最低分:73分
语文成绩标准差:8.8分
数学成绩最高分:97分
数学成绩最低分:71分
数学成绩标准差:8.6分
英语成绩最高分:96分
英语成绩最低分:66分
英语成绩标准差:11.1分
'''
# 将学生及其考试成绩以行的方式输出(按平均分从高到低排序)
results = {name: temp for name, temp in zip(names, scores)}
sorted_keys = sorted(results, key=lambda x: mean(results[x]), reverse=True)
for key in sorted_keys:
verbal, math, english = results[key]
print(f'{key}:\t{verbal}\t{math}\t{english}')
'''
孙悟空: 100 97 76
狄仁杰: 87 81 96
李元芳: 91 79 66
白起: 84 78 71
达摩: 73 71 88
'''
1. 感性认知
Python数据分析三大神器
- Numpy - Numerical Python - ndarray - 保存数据,完成批量的运算和处理
- pandas - Panel Data Set - Series(一维数据) / DataFrame(二维数据) - 封装了数据分析需要的各种方法
- matplotlib - 绘制统计图表
1.1 Numpy
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# 将list处理成ndarray对象
scores = np.array(scores)
print(scores)
'''
array([[100, 97, 76],
[ 91, 79, 66],
[ 84, 78, 71],
[ 87, 81, 96],
[ 73, 71, 88]])
'''
# 查看数据类型
type(scores)
# numpy.ndarray
# 按横向(学生)求平均值
np.round(scores.mean(axis=1), 1)
# array([91. , 78.7, 77.7, 88. , 77.3])
# 按竖向(学科)求最高分、最低分、标准差
scores.max(axis=0)
# array([100, 97, 96])
scores.min(axis=0)
# array([73, 71, 66])
np.round(scores.std(axis=0), 1)
# array([ 8.8, 8.6, 11.1])
1.2 pandas
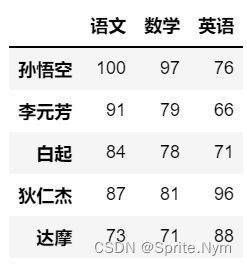
scores_df = pd.DataFrame(data=scores, columns=courses, index=names)
scores_df
效果图:
# 计算平均分
np.round(scores_df.mean(axis=1), 1)
'''
孙悟空 91.00000
李元芳 78.66875
白起 77.66875
狄仁杰 88.00000
达摩 77.33125
dtype: float64
'''
# 添加平均分列到表中
scores_df['平均分']= scores_df.mean(axis=1)
scores_df
效果图:

# 写入Excel文件
scores_df.to_excel('考试成绩.xlsx')
# 改plt字体
plt.rcParams['font.sans-serif'] = ['KaiTi']
plt.rcParams['axes.unicode_minus'] = False
# 将生成的图表改成矢量图
%config InlineBackend.figure_format='svg'
# 生成柱状图
scores_df.plot(kind='bar', y=['语文','数学','英语'])
# 旋转横轴的刻度
plt.xticks(rotation=0)
# 保存图表
plt.savefig('成绩柱状图.svg')
# 显示图表
plt.show()
效果图:

# 求学科最高分、最低分、平均分
scores_df.max()
'''
语文 100.0
数学 97.0
英语 96.0
平均分 91.0
dtype: float64
'''
scores_df.min()
'''
语文 73.0
数学 71.0
英语 66.0
平均分 77.3
dtype: float64
'''
scores_df.std()
'''
语文 9.874209
数学 9.602083
英语 12.361230
平均分 6.461656
dtype: float64
'''
2. Numpy
2.1 创建一维数组
# 方法一:通过array函数将list处理成ndarray对象
array1 = np.array([1, 2, 10, 20, 100])
array1
# array([ 1, 2, 10, 20, 100])
type(array1)
# numpy.ndarray
# 方法二:指定一个范围创建数组对象
array2 = np.arange(1, 100, 2)
array2
'''
array([ 1, 3, 5, 7, 9, 11, 13, 15, 17, 19, 21, 23, 25, 27, 29, 31, 33,35, 37, 39, 41, 43, 45, 47, 49, 51, 53, 55, 57, 59, 61, 63, 65, 67, 69, 71, 73, 75, 77, 79, 81, 83, 85, 87, 89, 91, 93, 95, 97, 99])
'''
# 方法三:指定范围和元素的个数创建数组对象
array3 = np.linspace(-5, 5, 101)
array3
'''
array([-5. , -4.9, -4.8, -4.7, -4.6, -4.5, -4.4, -4.3, -4.2, -4.1, -4. ,
-3.9, -3.8, -3.7, -3.6, -3.5, -3.4, -3.3, -3.2, -3.1, -3. , -2.9,
-2.8, -2.7, -2.6, -2.5, -2.4, -2.3, -2.2, -2.1, -2. , -1.9, -1.8,
-1.7, -1.6, -1.5, -1.4, -1.3, -1.2, -1.1, -1. , -0.9, -0.8, -0.7,
-0.6, -0.5, -0.4, -0.3, -0.2, -0.1, 0. , 0.1, 0.2, 0.3, 0.4,
0.5, 0.6, 0.7, 0.8, 0.9, 1. , 1.1, 1.2, 1.3, 1.4, 1.5,
1.6, 1.7, 1.8, 1.9, 2. , 2.1, 2.2, 2.3, 2.4, 2.5, 2.6,
2.7, 2.8, 2.9, 3. , 3.1, 3.2, 3.3, 3.4, 3.5, 3.6, 3.7,
3.8, 3.9, 4. , 4.1, 4.2, 4.3, 4.4, 4.5, 4.6, 4.7, 4.8,
4.9, 5. ])
'''
# 方法四:用随机生成元素的方法创建数组对象
# 随机小数
array4 = np.random.random(10)
array4
'''
array([0.74861994, 0.80263292, 0.54287411, 0.99088428, 0.27465232,
0.4421258 , 0.34908231, 0.39729076, 0.11863797, 0.37728455])
'''
# 随机整数
array5 = np.random.randint(1, 10)
array5
# 5
# 随机正态分布
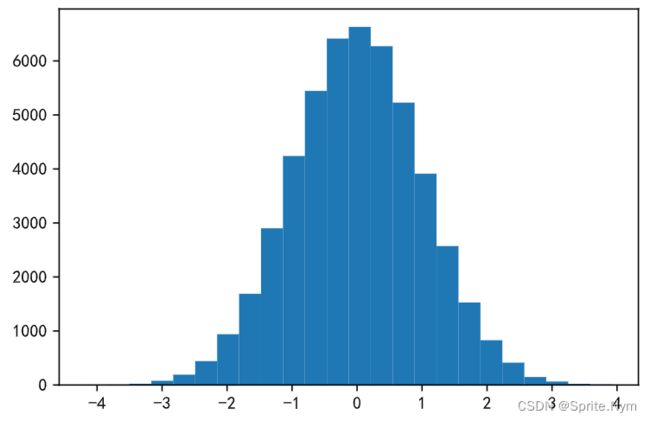
array6 = np.random.normal(0, 1, 50000)
array6
'''
array([-1.24165108, -0.07314869, -1.37729185, ..., -1.00691177,
0.19568883, 0.43887128])
'''
# 生成直方图
plt.hist(array6, bins=24)
plt.show()
效果图:
2.2 创建二维数组
# 方法一:通过array函数将嵌套列表处理成二维数组
array8 = np.array(([1, 2, 3], [4, 5, 5], [7, 8, 9]))
array8
'''
array([[1, 2, 3],
[4, 5, 5],
[7, 8, 9]])
'''
# 方法二:通过对一维数组调形变成二维数组
temp= np.arange(1, 11)
array9 = temp.reshape((5, 2))
array9
'''
array([[ 1, 2],
[ 3, 4],
[ 5, 6],
[ 7, 8],
[ 9, 10]])
'''
# 方法三;通过生成随机元素创建二维数组
array10 = np.random.randint(60, 101, (5, 3))
array10
'''
array([[71, 91, 67],
[95, 71, 96],
[90, 91, 92],
[67, 83, 74],
[95, 78, 60]])
'''
# 方法四:创建全0、全1、指定值的二维数组
array11 = np.zeros((5, 4), dtype='i8')
array11
'''
array([[0, 0, 0, 0],
[0, 0, 0, 0],
[0, 0, 0, 0],
[0, 0, 0, 0],
[0, 0, 0, 0]], dtype=int64)
'''
array12 = np.ones((5, 4), dtype='i8')
array12
'''
array([[1, 1, 1, 1],
[1, 1, 1, 1],
[1, 1, 1, 1],
[1, 1, 1, 1],
[1, 1, 1, 1]], dtype=int64)
'''
array13 = np.full((5, 4), 100)
array13
'''
array([[100, 100, 100, 100],
[100, 100, 100, 100],
[100, 100, 100, 100],
[100, 100, 100, 100],
[100, 100, 100, 100]])
'''
# 方法五:创建单位矩阵
array14 = np.eye(5)
array14
'''
array([[1., 0., 0., 0., 0.],
[0., 1., 0., 0., 0.],
[0., 0., 1., 0., 0.],
[0., 0., 0., 1., 0.],
[0., 0., 0., 0., 1.]])
'''
2.3 数组的索引和切片
2.3.1 普通用法
array10
'''
array([[71, 91, 67],
[95, 71, 96],
[90, 91, 92],
[67, 83, 74],
[95, 78, 60]])
'''
# 取指定元素
array10[1][2]
# 96
array10[1, 2]
# 96
# 取部分元素
array10[:3, :2]
'''
array([[71, 91],
[95, 71],
[90, 91]])
'''


总结:对多维数组的操作中,每做一次索引降一次维,而做切片不会降维。
2.3.2 特殊索引
# 花式索引(fancy index)
array2[[0, 1, 2, -3, -2, -1, -10]]
# array([ 1, 3, 5, 95, 97, 99, 81])
array10[[0, 1, 4], [0, 1, 2]]
# array([71, 71, 60])
# 布尔索引
array1[[False, True, False, True, False]]
# array([ 2, 20], dtype=uint64)
array2[array2 > 80]
# array([81, 83, 85, 87, 89, 91, 93, 95, 97, 99])
array16 = np.arange(1, 10)
array16[array16 % 2 !=0]
# array([1, 3, 5, 7, 9])
array16[(array16 > 5) & (array16 % 2 != 0)]
# array([7, 9])
array16[(array16 > 5) | (array16 % 2 != 0)]
# array([1, 3, 5, 6, 7, 8, 9])
array16[(array16 > 5) | ~(array16 % 2 != 0)]
# array([2, 4, 6, 7, 8, 9])
array10[array10 > 80]
# array([91, 95, 96, 90, 91, 92, 83, 95])
2.5 ndarray对象的方法
array1 = np.random.randint(10, 50, 10)
array1
# 求和
array1.sum
np.sum(array1)
# 求平均
array1.mean()
np.mean(array1)
# 求中位数
np.median(array1)
# 求最大值最小值
array1.max()
np.amax(array1)
array1.min()
np.amin(array1)
# 求极差(全距)
array1.ptp()
np.ptp(array1)
# 求方差
array1.var
np.var(array1)
# 求标准差
array1.std
np.std(array1)
# 求累计和
array1.cumsum()
np.cumsum(array1)
2.5.1 对上述描述性统计方法的补充说明:


2.5.2 用Excel实现上述功能


2.5.3 分位点和找异常值

def outliers_by_iqr(t_array, lower_points = 0.25, upper_points = 0.75, whis = 1.5):
"""iqr找异常值"""
q1, q3 = np.quantile(t_array, [lower_points, upper_points])
iqr = q3 - q1
return t_array[(t_array < q1 - whis * iqr)|(t_array > q3 + whis * iqr)]
# 测试
array2[-1] = 15
outliers_by_iqr(array2)
# array([15])
2.5.4 Z-score找异常值
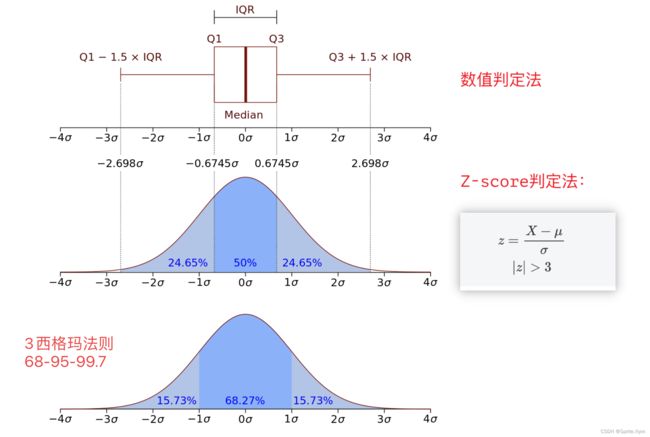
def outliers_by_zscore(array, threshold=3):
"""Z-score判定法检测离群点"""
mu, sigma = array.mean(), array.std()
return array[np.abs((array - mu) / sigma) > threshold]
# 把数组改长点,以使500显得突兀
# repeat()(会把相同元素放在一起)和tile()(按原本的顺序重复)
temp = np.repeat(array2[:-1], 100)
# append()和insert()添加
temp = np.append(temp, array2[-1])
temp = np.insert(temp, 0, array2[-1])
temp
outliers_by_zscore(temp)
# array([500, 500])
2.6 其他方法
2.6.1 all()/any
判断数组中是否所有元素都是True/判断数组是否有True的元素。
2.6.2 astype()方法
拷贝数组,并将数组中的元素转换为指定的类型。
array5 = array3.astype(np.float64)
array5.dtype
# dtype('float64')
2.6.3 dump()和load()方法
保存数组到文件中,可以通过NumPy中的load()函数从保存的文件中家在数据创建数组。
序列化:把对象处理成字符串(str)或字节串(bytes) —> 串行化/腌咸菜
反序列化:把字符串或字节串还原成对象 —> 反串行化
-
json模块:dump / dumps / load / loads —> 通用,跨语言
-
pickle模块:dump / dumps / load / loads —> 私有协议,其他语言无法反序列化
# 保存
with open('array3', 'wb') as file:
array3.dump(file)
# 读取
with open('array3', 'rb') as file:
array6 = np.load(file, allow_pickle=True)
array6
2.6.4 fill()方法
向数组中填充指定的元素。即数组中元素全部变成指定元素。
2.6.5 flatten()方法
将多维数组扁平化成一维数组
array7 = np.arange(1, 11).reshape(5, 2)
array7
'''
array([[ 1, 2],
[ 3, 4],
[ 5, 6],
[ 7, 8],
[ 9, 10]])
'''
array7.flatten('C')
# array([ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
array7.flatten('F')
# array([ 1, 3, 5, 7, 9, 2, 4, 6, 8, 10])
2.6.6 nonzero()方法
返回非0元素的索引
2.6.7 round()方法
对数组中的元素做四舍五入操作。
2.6.8 sort()方法
array8 = np.random.randint(1, 100, 10)
array8
# array([55, 98, 48, 98, 38, 5, 35, 36, 39, 87])
# 返回排序后的新数组
np.sort(array8)
# array([ 5, 35, 36, 38, 39, 48, 55, 87, 98, 98])
array8
# array([55, 98, 48, 98, 38, 5, 35, 36, 39, 87])
# 在原始数组上就地排序
array8.sort()
# 无返回值
array8
# array([ 8, 10, 12, 27, 28, 43, 45, 57, 65, 98])
2.6.9 transpose()和swapaxes()方法
交换数组指定的轴。
# 对于二维数组,transpose相当于实现了矩阵的转置
array7.transpose()
'''
array([[ 1, 3, 5, 7, 9],
[ 2, 4, 6, 8, 10]])
'''
# swapaxes交换指定的两个轴,顺序无所谓
array7.swapaxes(0, 1)
'''
array([[ 1, 3, 5, 7, 9],
[ 2, 4, 6, 8, 10]])
'''
2.6.10 tolist()方法
将数组转成Python中的list。不改变原数组。
array7.tolist()
# [[1, 2], [3, 4], [5, 6], [7, 8], [9, 10]]
2.7 其他常用函数
2.7.1 np.unique()
去重。
array9 = np.array([1,1,1,1,2,2,2,3,3,3])
array9
# array([1, 1, 1, 1, 2, 2, 2, 3, 3, 3])
np.unique(array9)
# array([1, 2, 3])
2.7.2 stack堆叠
array10 = np.array([[1,1,1], [2,2,2]])
array10
'''
array([[1, 1, 1],
[2, 2, 2]])
'''
array11 = np.array([[3,3,3,], [4,4,4,]])
array11
'''
array([[3, 3, 3],
[4, 4, 4]])
'''
# 水平方向(沿着1轴方向)的堆叠
np.hstack((array10, array11))
'''
array([[1, 1, 1, 3, 3, 3],
[2, 2, 2, 4, 4, 4]])
'''
# 垂直方向(沿着0轴方向)的堆叠
np.vstack((array10, array11))
'''
array([[1, 1, 1],
[2, 2, 2],
[3, 3, 3],
[4, 4, 4]])
'''
# 沿着指定轴堆叠并升维
np.stack((array10, array11), axis=0)
'''
array([[[1, 1, 1],
[2, 2, 2]],
[[3, 3, 3],
[4, 4, 4]]])
'''
np.stack((array10, array11), axis=1)
'''
array([[[1, 1, 1],
[3, 3, 3]],
[[2, 2, 2],
[4, 4, 4]]])
'''
2.7.3 concatenate合并
array12 = np.concatenate((array10, array11), axis=0)
array12
'''
array([[1, 1, 1],
[2, 2, 2],
[3, 3, 3],
[4, 4, 4]])
'''
array13 = np.concatenate((array10, array11), axis=1)
array13
'''
array([[1, 1, 1, 3, 3, 3],
[2, 2, 2, 4, 4, 4]])
'''
2.7.4 split拆分
# 垂直方向(沿着0轴方向)的拆分
np.vsplit(array12, 2)
'''
[array([[1, 1, 1],
[2, 2, 2]]),
array([[3, 3, 3],
[4, 4, 4]])]
'''
np.vsplit(array12, 4)
'''
[array([[1, 1, 1]]),
array([[2, 2, 2]]),
array([[3, 3, 3]]),
array([[4, 4, 4]])]
'''
# 水平方向(沿着1轴方向)的拆分
np.hsplit(array12, 3)
'''
[array([[1],
[2],
[3],
[4]]),
array([[1],
[2],
[3],
[4]]),
array([[1],
[2],
[3],
[4]])]
'''
# 沿着指定轴拆分
np.split(array13, 2)
'''
[array([[1, 1, 1, 3, 3, 3]]), array([[2, 2, 2, 4, 4, 4]])]
'''
np.split(array13, 3, axis=1)
'''
[array([[1, 1],
[2, 2]]),
array([[1, 3],
[2, 4]]),
array([[3, 3],
[4, 4]])]
'''
2.7.5 extract抽取
# 按照指定的条件从数组中抽取元素(类似于布尔索引)
np.extract(array14 <= 50, array14)
# array([19, 23, 50])
array14[array14 <= 50]
# array([19, 23, 50])
2.7.6 select多条件筛选
# 按照条件列表处理数组中的元素得到新的数组(多条件)
np.select([array14 % 2 == 0, array14 % 2 != 0], [array14 / 2, array14 ** 2])
# array([ 361., 9025., 38., 529., 25.])
2.7.7 where单条件筛选
# 按照条件数组中的元素得到新的数组(单条件)
np.where(array14 % 2 == 0, array14, 0)
# array([ 0, 0, 76, 0, 50])
2.7.8 resize调整大小
从左到右,从上到下循环填充
array15 = np.arange(1, 10).reshape((3, 3))
array15
'''
array([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]])
'''
# 调整数组的大小
np.resize(array15, (4, 4))
'''
array([[1, 2, 3, 4],
[5, 6, 7, 8],
[9, 1, 2, 3],
[4, 5, 6, 7]])
'''
2.7.9 put替换
# 替换数组中指定索引的元素
np.put(array15, 5, 100)
array15
'''
array([[ 1, 2, 3],
[ 4, 5, 100],
[ 7, 8, 9]])
'''
np.put(array15, [1, 2], 100)
array15
'''
array([[ 1, 100, 100],
[ 4, 5, 100],
[ 7, 8, 9]])
'''
2.7.10 place替换
# 替换数组中满足条件的元素
np.place(array15, array15 == 100, [2, 3])
array15
'''
array([[1, 2, 3],
[4, 5, 2],
[7, 8, 9]])
'''
2.8 数组的运算
2.8.1 广播机制
前提条件(必须满足其中一个):
-
两个数组的后缘维度(shape属性从后往前看)相同。
-
两个数组的后缘维度不同,但是其中一个维度为1。
满足广播机制是为了沿着缺失的轴或者沿着维度1的轴广播自己,最终让形状变得一致。
# 满足条件1:
array16 = np.arange(1, 16).reshape(5, 3)
array17 = np.array([[1, 1, 1]])
array16 + array17
'''
array([[ 2, 3, 4],
[ 5, 6, 7],
[ 8, 9, 10],
[11, 12, 13],
[14, 15, 16]])
'''
# 还是满足条件1:
array18 = np.random.randint(1, 18, (3, 4, 2))
array18
'''
array([[[ 2, 11],
[17, 16],
[ 2, 6],
[ 3, 13]],
[[ 6, 17],
[15, 4],
[ 2, 2],
[ 9, 6]],
[[ 8, 4],
[ 5, 9],
[15, 11],
[ 6, 17]]])
'''
array19 = np.random.randint(1, 10, (4, 2))
array19
'''
array([[7, 5],
[1, 7],
[2, 7],
[6, 5]])
'''



2.8.2 点积运算
A ⋅ B = ∑ a i b i A \cdot B = \sum a_ib_i \\ A⋅B=∑aibi
A ⋅ B = ∣ A ∣ ∣ B ∣ c o s θ A \cdot B = |A||B|cos\theta A⋅B=∣A∣∣B∣cosθ
计算出来为标量
# 求点积
a = np.array([1, 2, 3])
b = np.array([2, 4, 6])
np.dot(a, b)
# 28,即1 * 2 + 2 * 4 + 3 * 6 = 28
# 求a的模
# linear algebra
np.linalg.norm(a)
# 求b的模
np.linalg.norm(b)
# 求a,b夹角的余弦值,进而得到a,b的相关度
np.dot(a, b) / np.linalg.norm(a) / np.linalg.norm(b)
# 1.0
2.9 矩阵
2.9.1 矩阵的一些方法
# 创建矩阵
m1 = np.matrix('1 2; 3 4')
m1
'''
matrix([[1, 2],
[3, 4]])
'''
type(m1)
# numpy.matrix
# 获取对应的数组对象
m1.A
'''
array([[1, 2],
[3, 4]])
'''
# 获取对应的扁平化后的数组对象
m1.A1
'''
array([1, 2, 3, 4])
'''
# 获取转置后的矩阵
m1.T
'''
matrix([[1, 3],
[2, 4]])
'''
m1.swapaxes(0, 1)
m1.transpose()
# 同理
# 获取逆矩阵
m1.I
'''
matrix([[-2. , 1. ],
[ 1.5, -0.5]])
'''
2.9.2 矩阵乘法


A ⋅ A − 1 = I A \cdot A^{-1} = I A⋅A−1=I
m2 = np.matrix('1 0 2; -1 3 1')
m2
'''
matrix([[ 1, 0, 2],
[-1, 3, 1]])
'''
m3 = np.mat([[3, 1], [2, 1], [1, 0]])
m3
'''
matrix([[3, 1],
[2, 1],
[1, 0]])
'''
m2 * m3
'''
matrix([[5, 1],
[4, 2]])
'''
# 通过嵌套列表或二维数组创建matrix对象
m4 = np.asmatrix(np.arange(1, 10).reshape((3, 3)))
m4
'''
matrix([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]])
'''
# determinent
# 计算矩阵的值
np.linalg.det(m4)
# 计算矩阵的秩
np.linalg.matrix_rank(m4)
array2 = m2.A
array2
'''
array([[ 1, 0, 2],
[-1, 3, 1]])
'''
array3 = m3.A
array3
'''
array([[3, 1],
[2, 1],
[1, 0]])
'''
# 数组对象的矩阵乘法
array2 @ array3
'''
array([[5, 1],
[4, 2]])
'''
# 求逆矩阵
array1 = m1.A
np.linalg.inv(array1)
'''
array([[-2. , 1. ],
[ 1.5, -0.5]])
'''
2.9.3 解线性方程
{ x 1 + 2 x 2 + x 3 = 8 3 x 1 + 7 x 2 + 2 x 3 = 23 2 x 1 + 2 x 2 + x 3 = 9 \begin{cases} x_1 + 2x_2 + x_3 = 8 \\ 3x_1 + 7x_2 + 2x_3 = 23 \\ 2x_1 + 2x_2 + x_3 = 9 \end{cases} ⎩⎪⎨⎪⎧x1+2x2+x3=83x1+7x2+2x3=232x1+2x2+x3=9
A ⋅ x = b A \cdot x = b A⋅x=b
A = np.array([[1, 2, 1], [3, 7, 2], [2, 2, 1]])
b = np.array([8, 23, 9]).reshape(-1, 1)
C = np.hstack((A, b))
C
'''
array([[ 1, 2, 1, 9],
[ 3, 7, 2, 23],
[ 2, 2, 1, 9]])
'''
np.linalg.matrix_rank(A)
# 3
np.linalg.matrix_rank(C)
# 3
A ⋅ x = b A − 1 ⋅ A ⋅ x = A − 1 ⋅ b I ⋅ x = A − 1 ⋅ b x = A − 1 ⋅ b A \cdot x = b \\ A^{-1} \cdot A \cdot x = A^{-1} \cdot b \\ I \cdot x = A^{-1} \cdot b \\ x = A^{-1} \cdot b \\ A⋅x=bA−1⋅A⋅x=A−1⋅bI⋅x=A−1⋅bx=A−1⋅b
# 用上面的公式解线性方程组
np.linalg.inv(A) @ b
'''
array([[1.],
[2.],
[3.]])
'''
# 解线性方程组
np.linalg.solve(A, b)
'''
array([[1.],
[2.],
[3.]])
'''
2.10 相关系数
# 下载机器学习模块
pip install scikit-learn
import warnings
warnings.filterwarnings('ignore')
from sklearn.datasets import load_boston
# 加载波士顿房价数据集
datasets = load_boston()
# 查看datasets属性
dir(datasets)
# ['DESCR', 'data', 'data_module', 'feature_names', 'filename', 'target']
# 打印内容描述
print(datasets.DESCR)
# 内容太多不予展示
# 打印影响因素数据
datasets.data
# 内容太多不予展示
# 查看数据类型
type(datasets.data)
# numpy.ndarray
# 查看shape
datasets.data.shape
# (506, 13)
# 查看影响因素名
datasets.feature_names
'''
array(['CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE', 'DIS', 'RAD',
'TAX', 'PTRATIO', 'B', 'LSTAT'], dtype='
# 获得房价数据
y = datasets.target
y.shape
# (506,)
# 获得犯罪率数据
x1 = datasets.data[:, 0]
x1.shape
# (506,)
# 计算犯罪率和房价相关系数
np.corrcoef(x1, y)
'''
array([[ 1. , -0.38830461],
[-0.38830461, 1. ]])
'''
# 获得低收入群体数据
x2 = datasets.data[:, -1]
x2.shape
# (506,)
# 计算低收入群体与房价相关系数
np.corrcoef(x2, y)
'''
array([[ 1. , -0.73766273],
[-0.73766273, 1. ]])
'''
# 后面相同的例子省略
# 画散点图
plt.scatter(x1, y)
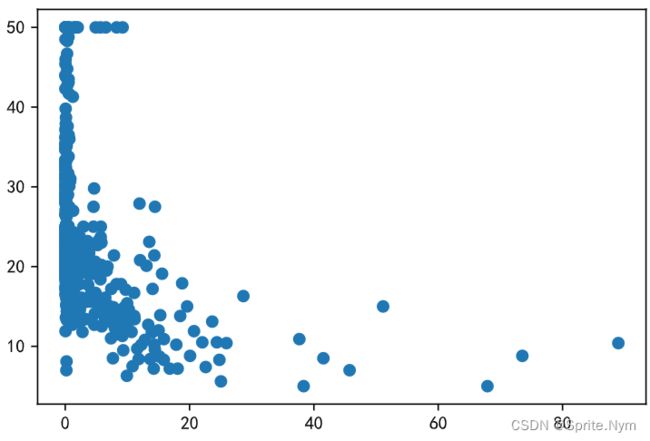
plt.scatter(x2, y)

2.11 K近邻
# 得到x:平均房间数数据,y:房价数据
x = datasets.data[:, 5]
y = datasets.target
# 将历史数据存入字典
history_data = {}
delta = 0
for room, price in zip(x, y):
if room not in history_data:
history_data[room] = price
else:
delta += 0.000001
history_data[room + delta] = price
len(history_data)
# 506
import heapq
def predicate_by_knn(room_num, k=5):
# 找到离目标数据最近的k个历史数据
nearest_neighbors = heapq.nsmallest(k, history_data, key=lambda x:(x-room_num) ** 2)
# 计算历史数据这些键对应的值的平均数
return round(np.mean([history_data[key] for key in nearest_neighbors]), 2)
# 调用函数试试
predicate_by_knn(6.125)
# 22.12
predicate_by_knn(5.525)
# 13.32
2.12 蒙特卡洛模拟
def get_loss(x, y, a, b):
"""损失函数"""
return np.mean((a * x + b - y) ** 2)
# 开始蒙特卡洛模拟,如果出现误差更低的情况就记录下来
min_loss = np.inf
best_a, best_b = None, None
for _ in range(10000):
a, b = np.random.random(2) * 200 - 100
curr_loss = get_loss(x, y, a, b)
if curr_loss < min_loss:
min_loss = curr_loss
best_a, best_b = a, b
print(a, b, min_loss)
print(best_a, best_b)
y_hat = best_a * x + best_b
# 画图看看
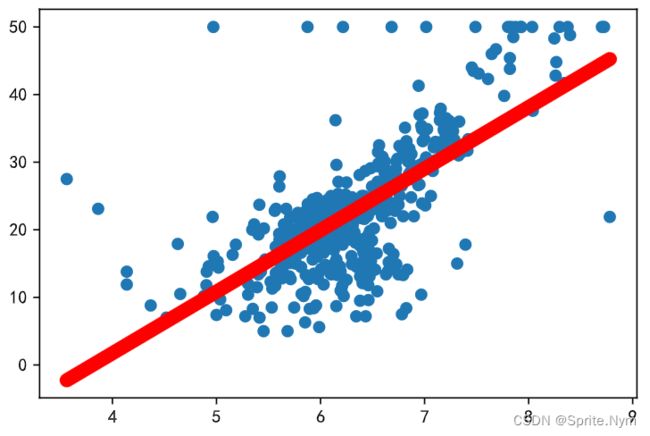
plt.scatter(x, y)
plt.plot(x, y_hat, color='red', linewidth=8)

# 定义出来根据拟合曲线求预测值的函数
def predicate_by_regression(room_num):
return round(best_a * room_num + best_b, 2)
# 调用函数试试
predicate_by_regression(5.525)
# 15
2.13 梯度下降
# 求a的偏导数
def partial_a(x, y, a, b):
return 2 * np.mean((y - a * x - b) * (-x))
# 求b的偏导数
def partial_b(x, y, a, b):
return 2 * np.mean(-y + a * x + b)
# 用梯度下降算法求a, b
a, b = 50, -50
delta = 0.013
for _ in range(1000):
a = a - partial_a(x, y, a, b) * delta
b = b - partial_b(x, y, a, b) * delta
print(get_loss(x, y, a, b))
print(best_a, best_b)
2.14 NumPy自带lstsq函数

param1 = np.vstack((x, np.ones(x.size))).T
param1
param2 = y.reshape((-1, 1))
param2
# least square - 最小二乘解
results = np.linalg.lstsq(param1, param2)
results
'''
(array([[ 9.10210898],
[-34.67062078]]),
array([22061.87919621]),
2,
array([143.99484122, 2.46656609]))
'''
a, b = results[0].flatten()
a, b
# (9.102108981180313, -34.67062077643857)
y_hat = a * x + b
plt.scatter(x, y)
plt.plot(x, y_hat, color='red', linewidth=8)
3. Pandas
3.1 series
3.1.1 创建对象
# 创建Series对象
ser1 = pd.Series(data=[320, 180, 250, 220], index=[f'{x}季度' for x in '1234'])
ser1
'''
1季度 320
2季度 180
3季度 250
4季度 220
dtype: int64
'''
# 通过字典创建series对象
ser2 = pd.Series(data={'一季度': 320, '二季度': 180, '三季度': 250, '四季度': 220})
ser2
'''
一季度 320
二季度 180
三季度 250
四季度 220
dtype: int64
'''
3.1.2 索引
# 普通索引
ser1['1季度']
# 320
ser2.一季度
# 320 (这种查询方法不能改成1季度,因为数字不能开头)
# 花式索引
ser1[['1季度', '3季度']]
'''
1季度 320
3季度 250
dtype: int64
'''
# 布尔索引
ser1[ser1 >= 200]
'''
1季度 320
3季度 250
4季度 220
dtype: int64
'''
3.1.3 切片
ser1[1:3]
'''
2季度 180
3季度 250
dtype: int64
'''
# 用自己取的索引名来切片两头都可以取到
ser1['2季度': '3季度']
'''
2季度 180
3季度 250
dtype: int64
'''
3.1.4 series对象的属性
# 获取索引
ser2.index
# Index(['一季度', '二季度', '三季度', '四季度'], dtype='object')
# 获取索引的值
ser2.index.values
# array(['一季度', '二季度', '三季度', '四季度'], dtype=object)
# 获取数据
ser2.values
# array([320, 180, 250, 220], dtype=int64)
# 元素个数
ser2.size
# 4
# 元素是否唯一
ser2.is_unique
# True
# 有没有空值
ser2.hasnans
# False
ser2['二季度'] = np.nan
ser2
'''
一季度 320.0
二季度 NaN
三季度 250.0
四季度 220.0
dtype: float64
'''
ser2.hasnans
# True
ser2['二季度'] = 280
ser2
# 280
# 数据是否单调递增
ser2.is_monotonic_increasing
# False
# 数据是否单调递减
ser2.is_monotonic_decreasing
# True
3.1.5 series对象的方法
# 获取描述性统计信息 - 集中趋势
# 求和
print(ser2.sum())
# 求平均
print(ser2.mean())
# 中位数
print(ser2.median())
'''
1070.0
267.5
265.0
'''
# 众数
print(ser2.mode())
'''
0 220.0
1 250.0
2 280.0
3 320.0
dtype: float64
'''
# 获取描述性统计信息 - 离散趋势
# 最大值和最小值
print(ser2.max())
print(ser2.min())
# 方差和标准差
print(ser2.var())
print(ser2.std())
print(np.var(ser2))
print(np.std(ser2))
# 上下四分位数
print(ser2.quantile(0.25))
print(ser2.quantile(0.75))
print(np.quantile(ser2, (0.25, 0.5, 0.75)))
'''
320
220
1825.0
42.720018726587654
1368.75
36.99662146737185
242.5
290.0
[242.5 265. 290. ]
'''
# 直接获取所有描述性统计信息
ser2.describe()
'''
count 4.000000
mean 267.500000
std 42.720019
min 220.000000
25% 242.500000
50% 265.000000
75% 290.000000
max 320.000000
dtype: float64
'''
3.1.6 数据清洗
3.1.6.1 去重
ser3 = pd.Series(['apple', 'banana', 'apple', 'pitaya', 'apple', 'pitaya', 'durian'])
ser3
'''
0 apple
1 banana
2 apple
3 pitaya
4 apple
5 pitaya
6 durian
dtype: object
'''
# 去重 ---> ndarray
ser3.unique()
# array(['apple', 'banana', 'pitaya', 'durian'], dtype=object)
# 不重复元素的个数
ser3.nunique()
# 4
# 元素重复的频次(按频次降序排列)
ser3.value_counts()
'''
apple 3
pitaya 2
banana 1
durian 1
dtype: int64
'''
# 判断元素是否重复
ser3.duplicated()
'''
0 False
1 False
2 True
3 False
4 True
5 True
6 False
dtype: bool
'''
# 布尔索引去重
ser3[~ser3.duplicated()]
'''
0 apple
1 banana
3 pitaya
6 durian
dtype: object
'''
# 去重 ---> Series
ser3.drop_duplicates()
'''
0 apple
1 banana
3 pitaya
6 durian
dtype: object
'''
# keep - 重复元素保留第一项还是最后一项,默认值first
ser3.drop_duplicates(keep='last')
'''
1 banana
4 apple
5 pitaya
6 durian
dtype: object
'''
# inplace - 是否就地进行操作
# True ---> 就地操作,不返回新的对象 ---> None
# False(默认值)---> 返回操作后的新对象 ---> Series
ser3.drop_duplicates(keep=False, inplace=True)
ser3
'''
1 banana
6 durian
dtype: object
'''
3.1.6.2 缺失值
# 判断空值
ser4.isnull()
'''
0 False
1 False
2 True
3 False
4 True
dtype: bool
'''
# 判断非空值
ser4.notnull()
'''
0 True
1 True
2 False
3 True
4 False
dtype: bool
'''
# 通过布尔索引筛选非空值
ser4[ser4.notnull()]
'''
0 10.0
1 20.0
3 30.0
dtype: float64
'''
# 删除指定的数据
ser4.drop(index=2)
'''
0 10.0
1 20.0
3 30.0
4 NaN
dtype: float64
'''
ser4.drop(index=[2, 4])
'''
0 10.0
1 20.0
3 30.0
dtype: float64
'''
# 删除空值(inplace=True,就地删除)
ser4.dropna()
'''
0 10.0
1 20.0
3 30.0
dtype: float64
'''
# 填充空值
ser4.fillna(50)
'''
0 10.0
1 20.0
2 50.0
3 30.0
4 50.0
dtype: float64
'''
ser4.fillna(method='ffill')
'''
0 10.0
1 20.0
2 20.0
3 30.0
4 30.0
dtype: float64
'''
ser4.fillna(method='bfill')
'''
0 10.0
1 20.0
2 30.0
3 30.0
4 NaN
dtype: float64
'''
# 前后都填充一次
ser4.fillna(method='ffill').fillna(method='bfill')
3.1.6.3 排序和头部值
# 给索引排序
# ascending ---> 升序还是降序 ---> 默认值True,代表升序
ser1.sort_index(ascending=False)
'''
4季度 220
3季度 250
2季度 180
1季度 320
dtype: int64
'''
# 给值排序
ser1.sort_values(ascending=False)
'''
1季度 320
3季度 250
4季度 220
2季度 180
dtype: int64
'''
# Top-N
ser1.nlargest(3)
'''
1季度 320
3季度 250
4季度 220
dtype: int64
'''
ser1.nsmallest(2)
'''
2季度 180
4季度 220
dtype: int64
'''
3.1.6.4 数据处理
# 例1:format对字符串批量处理
ser5 = pd.Series(['cat', 'dog', np.nan, 'rabbit'])
ser5
'''
0 cat
1 dog
2 NaN
3 rabbit
dtype: object
'''
ser5.map('I am a {}'.format, na_action='ignore')
'''
0 I am a cat
1 I am a dog
2 NaN
3 I am a rabbit
dtype: object
'''
# 例2:对数据批量处理
ser6 = pd.Series(np.random.randint(30, 80, 10))
ser6
'''
0 62
1 67
2 65
3 64
4 64
5 31
6 76
7 42
8 54
9 45
dtype: int32
'''
# 以下3种写法都可以
def upgrade(score):
return score ** 0.5 * 10
# np.round(ser6.map(upgrade), 0)
# np.round(ser6.map(lambda x: x ** .5 * 10), 0)
np.round(ser6.apply(lambda x: x ** .5 * 10), 0)
'''
0 79.0
1 82.0
2 81.0
3 80.0
4 80.0
5 56.0
6 87.0
7 65.0
8 73.0
9 67.0
dtype: float64
'''
线性归一化(标准化):
X i ′ = X i − X m i n X m a x − X m i n X_i' = \frac {X_{i} - X_{min}} {X_{max} - X_{min}} Xi′=Xmax−XminXi−Xmin
零均值归一化(中心化):
X i ′ = X i − μ σ X_i' = \frac {X_{i} - \mu} {\sigma} Xi′=σXi−μ
# 例3:对数据进行归一化
ser7 = pd.Series(data=np.random.randint(1, 10000, 10))
ser7
'''
0 9359
1 1222
2 2843
3 985
4 2478
5 3935
6 6838
7 1999
8 5907
9 9064
dtype: int32
'''
# 线性归一化
x_min = ser7.min()
x_max = ser7.max()
ser7.map(lambda x: (x - x_min) / (x_max - x_min))
'''
0 1.000000
1 0.028302
2 0.221877
3 0.000000
4 0.178290
5 0.352281
6 0.698949
7 0.121089
8 0.587772
9 0.964772
dtype: float64
'''
# 零均值归一化
miu = ser7.mean()
sigma = ser7.std()
ser7.map(lambda x: (x - miu) / sigma)
'''
0 1.646880
1 -1.090183
2 -0.544923
3 -1.169903
4 -0.667699
5 -0.177605
6 0.798885
7 -0.828822
8 0.485722
9 1.547650
dtype: float64
'''
3.1.7 绘图
ser7 = pd.Series(
data = np.random.randint(150, 550, 8),
index = [f'{x}季度' for x in '11213434']
)
ser7
'''
1季度 322
1季度 440
2季度 348
1季度 256
3季度 242
4季度 483
3季度 401
4季度 448
dtype: int32
'''
# 根据季度汇总数据绘制饼图
# level = 0表示按0级索引分组
temp = ser7.groupby(level=0).sum()
temp
'''
1季度 1018
2季度 348
3季度 643
4季度 931
dtype: int32
'''
# 绘制柱状图
temp.plot(kind='bar', color=['#a3f3b4', '#D8F781', 'blue', 'pink'])
plt.xticks(rotation=0)
plt.grid(True, alpha=0.5, axis='y', linestyle=':')
plt.show()

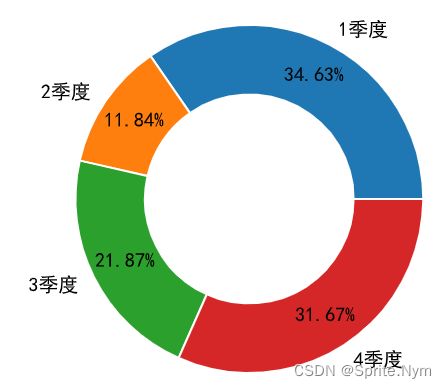
# 绘制饼图
temp.plot(kind='pie', autopct='%.2f%%', wedgeprops={
'edgecolor': 'w',
'width': 0.4,
}, pctdistance=0.8)
# 改y轴标签
plt.ylabel('')
plt.show()
3.2 DataFrame
3.2.1 创建DataFrame对象
3.2.1.1 通过构造器语法创建DataFrame对象
stuids = np.arange(1001, 1006)
courses = ['语文', '数学', '英语']
scores = np.random.randint(60, 101, (5, 3))
# 方法1:通过二维数组或嵌套创建DataFrame对象
df1 = pd.DataFrame(data = scores, columns = courses, index = stuids)
df1
# 方法2:通过字典创建DataFrame对象
scores = {
'语文': [62, 72, 93, 88, 93],
'数学': [95, 65, 86, 66, 87],
'英语': [66, 75, 82, 69, 82]
}
df2 = pd.DataFrame(data = scores, index = stuids)
df2
3.2.1.2 读取CSV文件
# 读取CSV文件创建DataFrame对象
df4 = pd.read_csv(
'datas/2018年北京积分落户数据.csv',
index_col='id', # 指定索引列
sep='#', # 指定分隔符
quotechar='`', # 包裹内容的字符
usecols=['id', 'name', 'score'], # 读取哪些列
nrows=10, # 读取的行数
skiprows=np.arange(1, 11) # 跳过的行数
# skiprows=lambda rn: rn > 0 and random.random() < 0.9 # 随机跳过行数
)
df4
# 读取CSV文件并创建成迭代器对象
df5_iter = pd.read_csv(
'datas/bilibili.csv',
encoding='gbk',
chunksize=10, # 10个内容1箱
iterator=True # 创建成迭代器对象
)
df5_iter
# 通过迭代器获取DataFrame对象
next(df5_iter)
3.2.1.3 读取Excel文件
df6 = pd.read_excel('datas/全国旅游景点数据.xlsx')
df6
# 省略结果展示
df7 = pd.read_excel(
'datas/2020年销售数据.xlsx',
sheet_name='data', # 要读的表名
header=0, # 指定表头位置
nrows=500,
skiprows=np.arange(1, 502)
)
df7
# 省略结果展示
df8 = pd.read_excel(
'datas/三国人物数据.xlsx',
sheet_name='全部人物数据',
header=0,
usecols=np.arange(0, 10)
)
df8
# 省略结果展示
3.2.1.4 从SQL提取数据
# 创建conn对象
import pymysql
conn = pymysql.connect(host='47.104.31.138', port=3306,
user='guest', password='Guest.618',
database='hrs', charset='utf8mb4')
conn
# 3.2.2 数据重塑
3.2.2.1 表联结
from sqlalchemy import create_engine
engine = create_engine('mysql+pymysql://guest:[email protected]:3306/hrs')
engine
# 获取部门表
dept_df = pd.read_sql('select dno, dname, dloc from tb_dept', engine)
dept_df
# 获取员工表
emp_df = pd.read_sql('select eno, ename, job, sal, comm, dno from tb_emp', engine)
emp_df
# 用DataFrame的方法去内联结
emp_df.merge(dept_df, how='inner', on='dno')
# 改列名后,两表列名不再相等
dept_df.rename(columns={'dno': 'deptno'}, inplace=True)
# 用left_on和right_on设置联表条件
temp_df = emp_df.merge(dept_df, how='inner', left_on='dno', right_on='deptno')
temp_df
# 也可以用函数联表
temp_df = pd.merge(emp_df, dept_df, how='inner',
left_on='dno', right_on='deptno')
temp_df
# 此时不会自动合并用于联表的相同列,可以手动删除
temp_df.drop(columns=['deptno', 'job'], inplace=True)
# 将deptno列改为索引列
dept_df = dept_df.set_index('deptno')
# 联结条件是索引列时写right_index=True
pd.merge(emp_df, dept_df, how='inner', left_on='dno', right_index=True)
3.2.2.2 表拼接(相当于union)
import os
# ignore_index=True表示无视原来的编号重新编号
df1 = pd.concat([pd.read_csv(f'datas/jobs/{i}') for i in os.listdir('datas/jobs')],
ignore_index=True)
df1.drop(columns=['uri', 'city'], inplace=True)
df1
3.2.3 获取指定行/列的数据
# 1. 操作列
# 获取指定列
df1['site']
# 计算不重复公司名数
df1['company_name'].nunique()
# 去重
df1['company_name'].drop_duplicates()
# 花式索引同时获取多列
df1[['company_name', 'site', 'edu']]
# 布尔索引
df1[df1['edu']=='本科']
# 按索引列和列名同时取多行
df1.loc[[4, 7, 1]]
# 按自带索引切片取多行
df1.iloc[1:5]
# 按索引列切片取多行
df1.loc[1:5]
# 2. 操作单元格
# 按索引列和列名锁定单元格
df1.at[7, 'company_name']
# 按编号锁定单元格
df1.iat[7, 0]
# 修改单元格
df1.iat[7, 0] = '川大资本家'
注意:iloc和loc、iat和at,不加i表示按行名和列名查,加了i表示按索引号顺序查。
3.2.4 数据清洗
3.2.4.1 空值处理
# 判断是否是空值
emp_df.isnull()
# 判断是否是非空值
emp_df.notnull()
# 删除含空值的行(即沿着0轴删)
emp_df.dropna()
# 删除含空值的列(即沿着1轴删)
emp_df.dropna(axis=1)
# 填充指定列的空值(由于每一列处理空值要求不同,所以一列列改)
emp_df['comm'] = emp_df['comm'].fillna(0).astype(np.int64)
emp_df
3.2.4.2 去重
# 判断重复
emp_df.duplicated('job')
# 去重
emp_df.drop_duplicates('job', keep='first')
# 获取DataFrame对象的相关信息
ytb.info()
# 获取DataFrame对象的前10行
ytb.head(10)
# 获取DataFrame对象的后10行
ytb.tail(10)
案例:
# 不限制最大显示列数
pd.set_option('display.max_column', None)
# 读科比投篮数据表
kobe = pd.read_csv('datas/Kobe_data.csv', index_col='shot_id')
kobe
# 查看信息
kobe.info()
# 统计比赛次数
kobe['game_id'].nunique()
# 统计与哪个队伍交手次数最多
kobe.drop_duplicates('game_id', inplace=True)
ser = kobe['opponent'].value_counts()
ser.index[0]
3.2.4.3 异常值
# 按索引删除
kobe.drop(index=kobe[kobe['opponent']=='BKN'].index)
# 将指定单元格替换掉(先限制到目标列,以免其他地方被无意间替换)
kobe['opponent'] = kobe['opponent'].replace(['SEA', 'BKN'], ['OKC', 'NJN'])
# 正则表达式替换
kobe = kobe.replace('BKN|SEA', '---', regex=True)
3.2.4.4 时间日期
# 字符串转换成时间日期
kobe['game_date'] = pd.to_datetime(kobe['game_date'])
# 获得时间日期中的年份、季度、月份
kobe['year'] = kobe['game_date'].dt.year
kobe['quarter'] = kobe['game_date'].dt.quarter
kobe['month'] = kobe['game_date'].dt.month
3.2.4.5 字符串
# .str获取数据系列对应的字符串,再调字符串方法
kobe['opponent'] = kobe['opponent'].str.lower()
kobe
3.2.5 数据筛选
# 筛选job_type为python或者数据分析的岗位
jobs_df.query('job_type == "python" or job_type == "数据分析"')
# 筛选job_name包含python或数据分析的岗位
jobs_df = jobs_df[jobs_df['job_name'].str.lower().str.contains('python') |
jobs_df['job_name'].str.contains('数据分析')]
3.2.6 数据处理
3.2.6.1 正则表达式抽取数据
# 用正则表达式捕获组抽取数据
temp_df = jobs_df['salary'].str.extract(r'(\d+)[Kk]?-(\d+)[Kk]?')
# 通过applymap方法将DataFrame的每个元素处理成int类型
temp_df = temp_df.applymap(int)
temp_df.info()
# 沿着1轴求平均值
jobs_df['salary'] = temp_df.mean(axis=1)
jobs_df
3.2.6.2 字符串拆分
# 拆分site列
temp_df = jobs_df['site'].str.split(r'\s', expand=True, regex=True)
temp_df.rename(columns={0: 'city', 1: 'district', 2: 'street'}, inplace=True)
temp_df
# 直接加列
jobs_df[temp_df.columns] = temp_df
jobs_df
# 删除指定列
jobs_df.drop(columns='site', inplace=True)
jobs_df
# 通过索引内联结
jobs_df.merge(temp_df, how='inner', left_index=True, right_index=True)
注意:apply和map是Series的方法,而applymap是DataFrame的方法。
3.2.6.3 调整列的顺序
# 重新调整索引的顺序
jobs_df.reindex(columns=['company_name', 'city', 'district', 'street', 'salary', 'year', 'edu', 'job_name', 'job_type'])
# 用花式索引调整列的顺序
jobs_df[['company_name', 'city', 'district', 'street', 'salary', 'year', 'edu', 'job_name', 'job_type']]
3.2.6.4 删除指定行
# 按布尔索引获取目标行并删除
jobs_df.drop(index=jobs_df[(jobs_df['edu'] == '高中') | (jobs_df['edu'] == '中专')].index,
inplace=True)
jobs_df
3.2.6.5 替换目标单元格
jobs_df['min_exp'] = jobs_df['year'].replace(['1年以内', '经验不限', '应届生'],
['0-1年', '0年', '0年']).str.extract(r'(\d+)')
jobs_df
3.2.6.6 分箱和作图
# 先看数据分布情况
luohu_df['score'].describe()
# 分箱
score_seg = pd.cut(luohu_df['score'], bins=np.arange(90, 130, 5), right=False)
score_seg
# 把分箱后的数据加回去
luohu_df.insert(4, 'score_seg', score_seg)
luohu_df
# 统计各箱数量
ser2 = luohu_df['score_seg'].value_counts()
ser2
# 画柱状图
ser2.plot(kind='bar')
for i, index in enumerate(ser2.index):
# 第一个参数是x轴位置,第二个是y轴位置,第三个是显示的字符串,第四个是居中对齐
plt.text(i, ser2[index] + 20, ser2[index], ha='center')
# x轴刻度逆时针旋转30度
plt.xticks(rotation=30)
3.2.6.7 定类变量的处理
# 创建哑变量矩阵
temp_df = pd.get_dummies(persons_df['职业'])
'''
医生 教师 画家 程序员
0 1 0 0 0
1 1 0 0 0
2 0 0 0 1
3 0 0 1 0
4 0 1 0 0
'''
# 写回原表
persons_df[temp_df.columns] = temp_df
persons_df
# 删除原职业列
persons_df.drop(columns='职业', inplace=True)
persons_df
3.2.6.8 定序变量的处理
# 用apply映射函数将定序变量处理成数值
def edu_to_value(sc):
results = {'高中': 1, '大专': 3, '本科': 5, '研究生': 10}
return results.get(sc, 0)
persons_df['学历'] = persons_df['学历'].apply(edu_to_value)
persons_df
3.2.7 数据分析
3.2.7.1 获取描述性统计信息
# 导入数据
sales_df = pd.read_excel('datas/2020年销售数据.xlsx', sheet_name='data')
sales_df
# 查看信息
sales_df.info()
# 计算销售额
sales_df['销售额'] = sales_df['销售数量'] * sales_df['售价']
sales_df
# 计算每个订单销售额的平均值
sales_df['销售额'].sum() / sales_df['销售订单'].nunique()
# 获取描述性统计信息
sales_df['销售数量'].describe()
3.2.7.2 排序和头部值
# 将DataFrame对象按销售额排降序(想按多个关键字排序就用列表,ascending后也跟列表)
sales_df.sort_values(by=['销售额'], ascending=False)
# 取销售额最大的前10条数据
sales_df.nlargest(10, '销售额')
# 取销售额最小的前5条数据
sales_df.nsmallest(5, '销售额')
3.2.7.3 分组聚合
# 1. 统计2020年月度销售额
# 添加月份列的写法
sales_df['月份'] = sales_df['销售日期'].dt.month
sales_df.groupby('月份')[['销售额']].sum()
# 不添加月份列的写法(会导致产生的结果表列名还是原来的‘销售日期’)
sales_df.groupby(sales_df['销售日期'].dt.month)[['销售额']].sum()
# 2. 统计各品牌销售额占比
total_sales = sales_df['销售额'].sum()
ser = sales_df.groupby('品牌')['销售额'].sum()
ser / total_sales
# 画饼图(不用自己算百分比,会自动算)
ser.plot(kind='pie', autopct='%.1f%%', pctdistance=1.3)
# 3. 统计各地区的月度销售额
# 方法1:自己groupby聚合
# 多级索引(此时以销售区域和月份作为索引列)
temp_df = sales_df.groupby(['销售区域', '月份'])[['销售额']].sum()
temp_df
# 重置索引(此时销售区域和月份成为普通列)
temp_df = temp_df.reset_index()
temp_df
# 透视(指定谁是索引、谁是列、谁是值)
temp_df2 = temp_df.pivot(index='销售区域', columns='月份', values='销售额').fillna(0).applymap(int)
temp_df2
# 方法2:一步到位
# 生成透视表 ---> 根据A统计B
sales_df.pivot_table(
index='销售区域',
columns='月份',
values='销售额',
aggfunc=np.sum, # 可以同时用多个聚合函数,传列表
fill_value=0,
margins=True, # 添加汇总行、列
margins_name='总计' # 改汇总行、列的名字
).applymap(int)
# 4. 统计各渠道的品牌销量
pd.pivot_table(
sales_df, index='销售渠道', columns='品牌', values='销售数量',
aggfunc='sum', margins=True, margins_name='总计'
)
# 5. 统计不同售价区间的月度销量占比
sales_df['售价'].describe()
# 方法1:条件列
# 定义条件列的条件
def make_tag(price):
if price < 200:
return '低端'
return '中端' if price < 470 else '高端'
# 创建条件列
sales_df['价位'] = sales_df['售价'].apply(make_tag)
sales_df
# 透视表
temp_df = pd.pivot_table(sales_df, index='价位', columns='月份', values='销售数量', aggfunc='sum')
temp_df
# 改行的顺序
temp_df = temp_df.reindex(index=['低端', '中端', '高端'])
temp_df
# 方法2:分箱
price_seg = pd.cut(sales_df['售价'], bins=[0, 200, 470, 1500], right=False)
price_seg
# 透视表
pd.pivot_table(sales_df, index=price_seg, columns='月份', values='销售数量', aggfunc='sum')
3.2.8 总结
-
核心数据类型:
- Series - 表示一维数据
- DataFrame - 表示二维数据
-
核心的方法和函数
- 数据加载:read_csv / read_excel / read_sql —> DataFrame
- rename:修改行索引和列索引的名字
- reset_index:重置索引(drop=True,表示删除原索引列;level=0,表示只把第1个索引列变成普通列)
- set_index:设置索引,指定使用哪个或哪些列充当索引
- reindex:调整索引的顺序(行和列都可以)
- 数据筛选:
- query:条件表达式 / 布尔索引
- drop:把不满足条件的数据直接删除
- 数据重塑:
- merge —> how / on / left_on / right_on / left_index / right_index
- concat
- 数据准备:
- 缺失值:isna / notna / dropna / fillna
- 重复值:duplicated / drop_duplicates / nunique
- 异常值:drop / replace
- 预处理:map / apply / applymap / transform / cut / qcut / get_dummies / where / mask
- 统计排序:
- 统计:sum / mean / count / max / min / std / var / cumsum
- 排序:sort_index / sort_values / nlargest / nsmallest
- 数据透视:
- 分组:groupby —> Groupby对象 —> 聚合函数
- 透视表:pivot_table —> 根据A统计B —> index / columns / values / aggfunc
- 数据呈现
- 绘图:plot —> kind —> line / scatter / bar / barh / pie
- 数据加载:read_csv / read_excel / read_sql —> DataFrame
3.2.9 其他边角知识
# 1. aggregate - 聚合
sales_df.groupby('月份')[['销售额']].agg(['sum', 'max', 'min', 'count'])
# 2. 索引(反)堆叠
# 窄表变宽表(多级索引的某一级放到上面)
# 先生成窄表
temp_df = sales_df.groupby(['销售区域', '月份'])[['销售额']].sum()
temp_df
# 反堆叠变宽表
temp_df = temp_df.unstack(level=0).fillna(0).applymap(int)
temp_df
# 将列索引堆叠到行索引上(宽表变窄表)
temp_df=temp_df.stack()
temp_df
# 3. 索引调序
# 方法1
temp_df.reorder_levels(['月份', '销售区域'])
# 方法2
temp_df.swaplevel(0, 1)
# 4. 随机抽样
# 抽xx条样
sales_df.sample(n=200)
# 抽百分之xx的样
sales_df.sample(frac=0.1).sort_index()
# 5. 插值
ser = pd.Series([0, 1, np.nan, 9, 16, np.nan, 36])
ser
# 线性插值
ser.interpolate()
# 取上面一个数的值
ser.interpolate(method='pad')
# 二次项插值
ser.interpolate(method='polynomial', order=2)
# 6. 处理复合值
temp_df = pd.DataFrame({'A': [[1, 2, 3], 'foo', 10, 20], 'B': [[10, 20, 30], 1, 1, 1]})
temp_df
'''
A B
0 [1, 2, 3] [10, 20, 30]
1 foo 1
2 10 1
3 20 1
'''
temp_df.explode(['A', 'B'])
'''
A B
0 1 10
0 2 20
0 3 30
1 foo 1
2 10 1
3 20 1
'''
# 7. 移动数据
# 生成数据
temp_df = sales_df.groupby('月份')[['销售额']].sum()
temp_df
# 下移一行生成新列
temp_df['上期销售额'] = temp_df['销售额'].shift(1)
temp_df
# 计算环比
100 * (temp_df['销售额'] - temp_df['上期销售额']) / temp_df['上期销售额']
# 8. 用pct_change方法计算环比
def to_percentage(value):
if np.isnan(value):
return '---'
return f'{value * 100:.2f}%'
temp_df.pct_change()['销售额'].map(to_percentage)
# 9. 窗口计算
import pandas_datareader as pdr
# 获取数据
baidu_df = pdr.get_data_stooq('BIDU', start='2022-1-1', end='2022-5-31')
baidu_df
# 排序
baidu_df.sort_index(inplace=True)
baidu_df
# 窗口计算(5行计算1次均值)
day5_mean = baidu_df['Close'].rolling(5).mean()
day5_mean
# 窗口计算(10行计算1次均值)
day10_mean = baidu_df['Close'].rolling(10).mean()
day10_mean
# 画折线图
plt.figure(figsize=(8, 4), dpi=150)
plt.plot(baidu_df.index, day5_mean, color='orange')
plt.plot(baidu_df.index, day10_mean, color='blue')
plt.show()
# 10. 计算相关系数
# 获取数据
boston_df = pd.read_csv('datas/boston_house_price.csv', index_col=0)
boston_df
# 计算协方差
boston_df.cov()
# 计算两列的相关系数
np.corrcoef(boston_df['RM'], boston_df['PRICE'])
# 两两计算相关系数(默认按皮尔逊相关系数计算)
temp_df = boston_df.corr(method='pearson')
temp_df
# 计算某列和其他列的相关系数
temp_df[['PRICE']].style.background_gradient('Reds')
# 计算偏度
boston_df['PRICE'].skew()
# 计算峰度
boston_df['PRICE'].kurt()
附:偏度和峰度
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-0izLuvrG-1656407811559)(C:\Users\HP\AppData\Roaming\Typora\typora-user-images\image-20220628155808772.png)]
# 11. Index类型
RangeIndex:数字索引
CategoricalIndex:类别索引
MultiIndex:多级索引
DatetimeIndex:时间日期索引
# 1. 多级索引
# 准备数据
stu_ids = np.arange(1001, 1006)
sms = ['期中', '期末']
index = pd.MultiIndex.from_product((stu_ids, sms), names=['学号', '学期'])
index
from random import random
courses = ['语文', '数学', '英语']
scores = np.random.randint(60, 101, (10, 3))
scores_df = pd.DataFrame(data=scores, columns=courses, index=index)
scores_df
# 计算每个学生的平均成绩,期中占25%,期末占75%
def handel_score(x):
# 解包拿到两个值、或者x.values()拿到列表
a, b = x
return a * 0.25 + b * 0.75
scores_df.groupby(level=0).agg(handel_score)
# 2. 时间日期索引
# 按指定日期数量创建日期列表
pd.date_range('2021-1-1', '2021-6-1', periods=21)
# 以周围单位创建时间列表
pd.date_range('2021-1-1', '2021-6-1', freq='W')
# 创建时间列表后做减法改时间
pd.date_range('2021-1-1', '2021-6-1', freq='W') - pd.DateOffset(days=2)
# 每周取1次数据
baidu_df.asfreq('M')
# 每10天取1次数据,取不到就用上面的数据填充
baidu_df.asfreq('10D', method='ffill')
# 基于时间分组数据
baidu_df['Volume'].resample('10D').sum()
# 更改时区
baidu_df.tz_localize('Asia/Chongqing')