关于Focal loss损失函数的代码实现
引言
场景:使用Bert做一个违规样本分类模型,数据呈现正负样本不均衡,难易样本不均衡等问题,尝试使用Focal loss替换Bert中后半部分的交叉熵损失函数。
初衷:由于使用的Bert模型中使用的损失函数为交叉熵损失函数,torch.nn.CrossEntropyLoss,那么如果能理解实现原理,将focal loss在该api基础上实现,就可以尽可能少修改原始代码
- Focal loss的公式:其中用到的交叉熵损失函数表达式是(3)
F L ( p t ) = − ( 1 − p t ) γ log p t (1) FL(p_{t}) = - (1 - p_{t})^{\gamma}\log{p_{t}}\tag{1} FL(pt)=−(1−pt)γlogpt(1) - 其中:
p t = { p i f y = 1 1 − p o t h e r w i s e (1.1) p_{t}=\begin{cases} p& if & y = 1 \\ 1-p && otherwise \end{cases}\tag{1.1} pt={p1−pify=1otherwise(1.1)
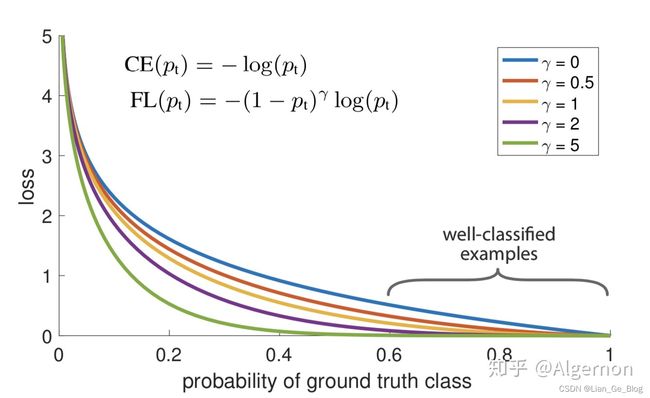
辅助理解:首先要了解的是交叉熵损失函数可以是二分类也可以是多分类,核心就是sigmoid还是softmax作为激活函数,那么对应的就是CE和BCE,从而focal loss根据CE BCE也就有两种表达。
1 focal loss的公式推导过程理解可以参考:寻找解决样本不均衡方法之Focal Loss与GHM - 知乎 (zhihu.com)
2 交叉熵损失函数的推导过程可以参考:交叉熵损失函数 - 知乎 (zhihu.com)
3 CE与BCE的区别:CE Loss 与 BCE Loss 区别 - 知乎 (zhihu.com)
- BCE:二分类
L = − ∑ i = 1 N ( y i log y ^ i + ( 1 − y i ) log ( 1 − y ^ i ) ) (2) L = -\sum^N_{i=1}(y_{i}\log{\hat{y}_{i}} + (1-y_{i})\log{(1-\hat{y}}_{i}))\tag{2} L=−i=1∑N(yilogy^i+(1−yi)log(1−y^i))(2) - CE:多分类,当其是二分类时候与BCE有什么区别可见上面的链接
L = − ∑ i = 1 N ( y i log y ^ i ) (3) L = -\sum^N_{i=1}(y_{i}\log{\hat{y}_{i}} )\tag{3} L=−i=1∑N(yilogy^i)(3) - pytorch中具体实现方法可以查看:[CrossEntropyLoss — PyTorch 1.12 documentation]


- softmax,log_softmax,nllloss的表达式:
- 关于nllloss专门整理一篇介绍。
σ ( z ) j = e z j ∑ k = 1 n e z k (softmax) \sigma(z)_{j} = \frac{e^{z_{j}}}{\sum_{k=1}^ne^{z_{k}}}\tag{softmax} σ(z)j=∑k=1nezkezj(softmax)
l o g s o f t m a x = ln σ ( z ) j logsoftmax = \ln{\sigma(z)_{j}} logsoftmax=lnσ(z)j
n l l l o s s = − 1 N ∑ k = 1 N y k ( l o g s o f t m a x ) nllloss = - \frac{1}{N}\sum_{k=1}^Ny_{k}(logsoftmax) nllloss=−N1k=1∑Nyk(logsoftmax)
- 使用pytorch实现focal loss源码如下:(个人觉得比较简练的一个)
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, Dataset
import torchvision
import torchvision.transforms as F
from IPython.display import display
class FocalLoss(nn.Module):
def __init__(self, weight=None, reduction='mean', gamma=0, eps=1e-7):
super(FocalLoss, self).__init__()
self.gamma = gamma
self.eps = eps
self.ce = torch.nn.CrossEntropyLoss(weight=weight, reduction=reduction)
def forward(self, input, target):
logp = self.ce(input, target)
p = torch.exp(-logp)
loss = (1 - p) ** self.gamma * logp
return loss.mean()
代码来源:Focal Loss代码分析(公式修改版-知乎公式坑) - 知乎 (zhihu.com)
代码实现的原理如下:
pytorch中交叉熵损失函数所有表达式,类比(3)
l o s s ( x , c l a s s ) = − log e x c l a s s ∑ j e x j = − x c l a s s + log ∑ j e x j (3) loss(x,class) = -\log{\frac{e^{x_{class}}}{\sum_{j}e^{x_j}}}= -x_{class} + \log{\sum_{j}e^{x_j}}\tag{3} loss(x,class)=−log∑jexjexclass=−xclass+logj∑exj(3)
α-balanced交叉熵结合表达式
l o s s ( x , c l a s s ) = α c l a s s ∗ ( − x c l a s s + log ∑ j e x j ) (4) loss(x,class)= \alpha_{class}*(-x_{class} + \log{\sum_{j}e^{x_j}})\tag{4} loss(x,class)=αclass∗(−xclass+logj∑exj)(4)
focal loss表达式:
l o s s ( x , c l a s s ) = ( 1 − e x c l a s s ∑ j e x j ) γ − log e x c l a s s ∑ j e x j = ( 1 − e x c l a s s ∑ j e x j ) γ ( − x c l a s s + log ∑ j e x j ) = − ( 1 − p t ) γ log ( p t ) (5) loss(x,class) =(1 - \frac{e^{x_{class}}}{\sum_{j}e^{x_j}})^{\gamma} -\log{\frac{e^{x_{class}}}{\sum_{j}e^{x_j}}} =(1 - \frac{e^{x_{class}}}{\sum_{j}e^{x_j}})^{\gamma}(-x_{class} + \log{\sum_{j}e^{x_j}}) = -(1-p_{t})^{\gamma} \log{(p_{t})}\tag{5} loss(x,class)=(1−∑jexjexclass)γ−log∑jexjexclass=(1−∑jexjexclass)γ(−xclass+logj∑exj)=−(1−pt)γlog(pt)(5)
带有alpha平衡参数的focal loss表达式:
l o s s ( x , c l a s s ) = − α t ( 1 − p t ) γ log ( p t ) (6) loss(x,class) = -\alpha_{t}(1-p_{t})^{\gamma} \log{(p_{t})}\tag{6} loss(x,class)=−αt(1−pt)γlog(pt)(6)
将CrossEntropyLoss改成Focal Loss
− log p t = n n . C r o s s E n t r o p y L o s s ( i n p u t , t a r g e t ) (7) -\log{p_{t}} = nn.CrossEntropyLoss(input, target)\tag{7} −logpt=nn.CrossEntropyLoss(input,target)(7)
那么:
p t = t o r c h . e x p ( − n n . C r o s s E n t r o p y L o s s ( i n p u t , t a r g e t ) ) (8) p_{t} = torch.exp(-nn.CrossEntropyLoss(input, target))\tag{8} pt=torch.exp(−nn.CrossEntropyLoss(input,target))(8)
所有Focal loss的最终为
f o c a l l o s s = − α t ( 1 − p t ) γ log ( p t ) (9) focalloss = -\alpha_{t}(1-p_{t})^{\gamma} \log{(p_{t})}\tag{9} focalloss=−αt(1−pt)γlog(pt)(9)
当然考虑到是mini-batch算法,因此最后一步取均值运算。
关于使用CE与BCE的实现方法可以参考以下代码:(关于γ与α的调参也有部分解答)
一、Focal Loss理论及代码实现_MY头发乱了的博客-CSDN博客_focal loss代码实现
基于二分类交叉熵实现
# 1.基于二分类交叉熵实现
class FocalLoss(nn.Module):
def __init__(self, alpha=1, gamma=2, logits=False, reduce=True):
super(FocalLoss, self).__init__()
self.alpha = alpha
self.gamma = gamma
self.logits = logits
self.reduce = reduce
def forward(self, inputs, targets):
if self.logits:
BCE_loss = F.binary_cross_entropy_with_logits(inputs, targets, reduce=False)
else:
BCE_loss = F.binary_cross_entropy(inputs, targets, reduce=False)
pt = torch.exp(-BCE_loss)
F_loss = self.alpha * (1-pt)**self.gamma * BCE_loss
if self.reduce:
return torch.mean(F_loss)
else:
return F_loss
其他的参考资料
关于binary_cross_entropy_with_logits与binary_cross_entropy的区别可以看:
pytorch损失函数binary_cross_entropy和binary_cross_entropy_with_logits的区别_czg792845236的博客-CSDN博客_binary_cross_entropy torch
关于focal loss二分类公式的一些变形可以参考:
【论文解读】Focal Loss公式、导数、作用详解 - 知乎 (zhihu.com)
使用纯pytorch代码实现focal loss
Focal Loss 的Pytorch 实现以及实验 - 知乎 (zhihu.com)
辅助理解代码实现:
深度学习之目标检测(五)-- RetinaNet网络结构详解_木卯_THU的博客-CSDN博客_retinanet
focal loss原理及简单代码实现_pomelo33的博客-CSDN博客_focal loss代码实现
吃透torch.nn.CrossEntropyLoss() - 知乎 (zhihu.com)