pytorch 实现VGG16 解决VGG误差不更新问题
问题

查看非叶子结点的梯度,不是none,如果把全连接层的激活函数删掉,结果一样,显然是激活函数的原因,因为loaddata函数
在处理数据的时候把数据所放在(-1,1)的区间中了,所以用relu函数在<0的时候, 基本和神经元死亡没啥区别了,那么前向死亡,反向传播就更别想了,早点睡吧,赶紧换,sigmoid都比relu强… 然后去掉dropout函数 减少训练的时间
话不多说先上代码
import time
import torch
import torchvision
import torchvision.transforms as transforms
# import matplotlib.pyplot as plt
import numpy as np
import torch.optim as optim
import torch.nn as nn
import torch.nn.functional as F
import vgg
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
# self.f = stack_big((2, 2, 3, 3, 3), ((3, 64), (64, 128), (128, 256), (256, 512)))
net = []
for n, c in zip((2, 2, 5, 3), ((3, 64), (64, 128), (128, 256), (256, 512))):
in_c = c[0]
out_c = c[1]
net += [stack_mini(n, in_c, out_c)]
# self.f = nn.Sequential(*net)
self.f = nn.Sequential(*net)
# print(self.f)
self.fc = nn.Sequential(
nn.Linear(2 * 2 * 512, 384),
nn.SELU(True),
# nn.Tanh(),
nn.Linear(384, 192),
nn.SELU(True),
# nn.Tanh(),
nn.Linear(192, 10)
)
def forward(self, x):
# x = self.f(x)
x = self.f[0](x)
x = self.f[1](x)
x = self.f[2](x)
x = self.f[3](x)
x = x.view(x.shape[0], -1)
x = self.fc(x)
return x
def stack_mini(num_convs, in_channels, out_channels):
'''
block块 开始以卷积层开始,结束以池化层结束 过程中提取高纬数据
:param num_convs: 循环次数
:param in_channels: 输入通道数
:param out_channels: 输出通道数
:return:
'''
# 定义第一层并转换为list
net = [nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1), nn.ReLU(True)] # 卷积+激活层
# 循环定义其它层
for i in range(num_convs - 1): # 卷积层+激活层
# net.append(nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1))
# net.append(nn.ReLU(True))
net += [nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1), nn.ReLU(True)]
# 定义池化层
# net.append(nn.MaxPool2d(2, 2)) # 2*2 步长为2
net += [nn.MaxPool2d(2, 2)]
# return net
return nn.Sequential(*net)
def stack_big(num_convs, channels):
'''
创建数据提取模块
:param num_convs:[循环次数]list
:param channels:[(输入,输出),(输入维度,输出维度)]list
:return:数据特征提取网络
'''
net = []
for n, c in zip(num_convs, channels):
in_c = c[0]
out_c = c[1]
net += [stack_mini(n, in_c, out_c)]
return net
def loadData():
tf = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
trainset = torchvision.datasets.CIFAR10(root='../data', train=True, download=True, transform=tf)
trainLoader = torch.utils.data.DataLoader(trainset, batch_size=32, shuffle=True, num_workers=2)
testset = torchvision.datasets.CIFAR10(root='../data', train=False, download=True, transform=tf)
testLoader = torch.utils.data.DataLoader(testset, batch_size=32, shuffle=True, num_workers=2)
return trainLoader, testLoader
classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
def train_model_GPU(PATH):
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
print(device)
net = Net()
net = net.to(device)
criterion = nn.CrossEntropyLoss() # 交叉熵损失函数,因为是多分类问题,所以使用交叉熵损失
# 优化器
# optimizer = optim.SGD(net.parameters(), lr=1e-3) # momentum动量初始化 adam?
optimizer = optim.Adam(net.parameters(), lr=1e-3, betas=(0.9, 0.99))
# optimizer = optim.Adagrad(net.parameters(), lr=1)
# optimizer = optim.RMSprop(net.parameters(), lr=1e-3, alpha=0.9)
trainLoader, testLoader = loadData()
num = 0
list_num = []
list_num2 = []
y_list = []
y_list2 = []
for epoch in range(30):
# 所有数据循环n次训练
running_loss = 0.0
for i, data in enumerate(trainLoader, 0):
# 所有数据训练一遍是一个epoch
inputs, labels = data[0].to(device), data[1].to(device)
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs, labels)
running_loss += loss.item()
loss.backward()
optimizer.step()
# print('lossitem', loss.item())
num += 1
list_num2.append(num)
y_list2.append(running_loss)
if (i + 1) % 5 == 0:
list_num.append(num)
y_list.append(running_loss / 5)
print(epoch + 1, i + 1, running_loss / 5)
running_loss = 0.0
import matplotlib.pyplot as plt
# plt.plot(list_num, y_list, linestyle='-')
plt.scatter(list_num, y_list)
plt.savefig('./2demo.png')
plt.scatter(list_num2, y_list2)
plt.savefig('./demo.png')
print('finish fit')
torch.save(net.state_dict(), PATH)
def evaluate_model(PATH):
# PATH = '../alex_net.pth'
net = Net()
net.load_state_dict(torch.load(PATH))
a, testLoader = loadData()
correct = 0
total = 0
with torch.no_grad():
# 不进行求导
for i, data in enumerate(testLoader):
images, labels = data
outputs = net(images)
_, predicted = torch.max(outputs.data, 1) # 输出中选取概率最大的值
if (i % 100 == 0):
print('输入图片images--->', images.shape) # torch.Size([4, 3, 32, 32])
print('真实标签labels--->', labels.shape) # torch.Size([4])
print('输出值outputs-->', outputs.shape) # torch.Size([4, 10])
print('预测值predicted--->', predicted, 'labels标签值--->', labels)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print(total, correct)
print(f'准确率为{100 * correct / total}')
if __name__ == '__main__':
a = time.time()
train_model_GPU('../vgg2.pth')
b = time.time()
print(b - a)
evaluate_model('../vgg2.pth')


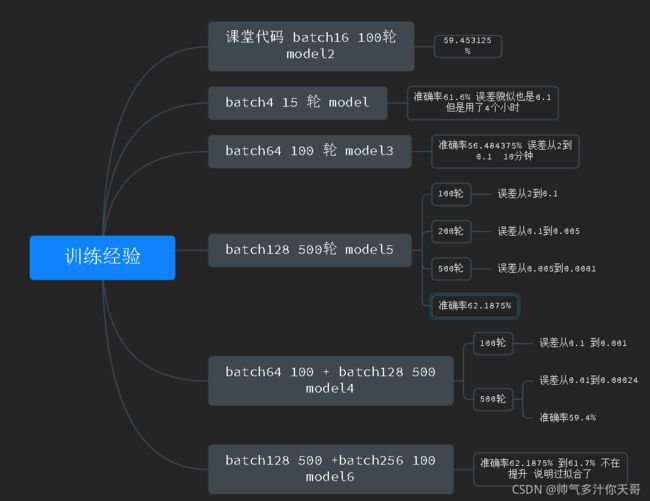
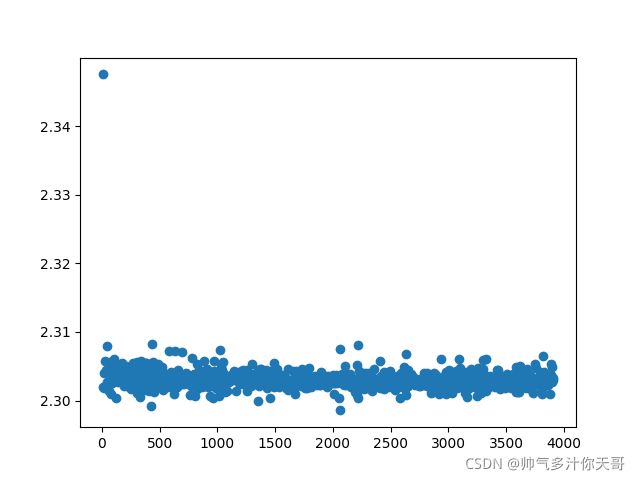
最简单的神经网络两层卷积,三层全连接,参数不再调整,仅仅只看batch 与epoch 对准确率的影响,这里的准确率是循环10次验证集取平均值得出的,可信度比较高

去掉随机失活,更改激活函数后,epoch30 batchSize=64 误差图像 10分类,准确率79%


纵坐标为误差,横坐标为训练次数
batchSize=128 时,epoch=1 时,效果立竿见影的看到误差线性向下跌 跟你买的基金一样

第一张图是平均误差散点图

第二张图是实际误差散点图
batchSize=128 时,epoch=2 时,效果更好了,准确率来到了50%,跌的更猛了,赶紧清仓拉


batchSize=128 时,epoch=10 时,效果更好了,准确率来到了75%


可以看到误差还是线性下降那么继续增加轮次,但是要注意一点,并非纯粹的线性,最好加上动态学习率的设计
动态学习率
epoch越大学习率越小


添加5epoch后,准确率仅提升2% 由75%到77%
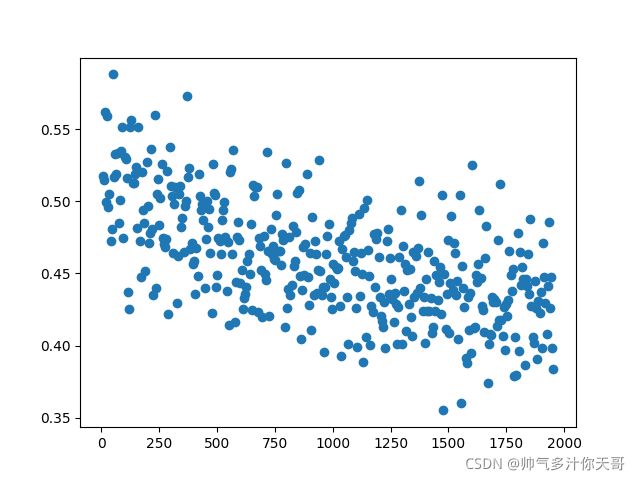

误差不忍直视,基本没怎么动,这里换一个学习率 +数据增强 …有时间再试试,未完待续
继续更新,2021年10月16日22:43:48
改进 epoch=1 准确率59%
无意间发现vgg模块中的激活函数还是relu没有改selu,改过来之后把学习率设置为1e-4 效果出奇的好
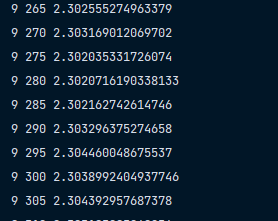
平均误差下降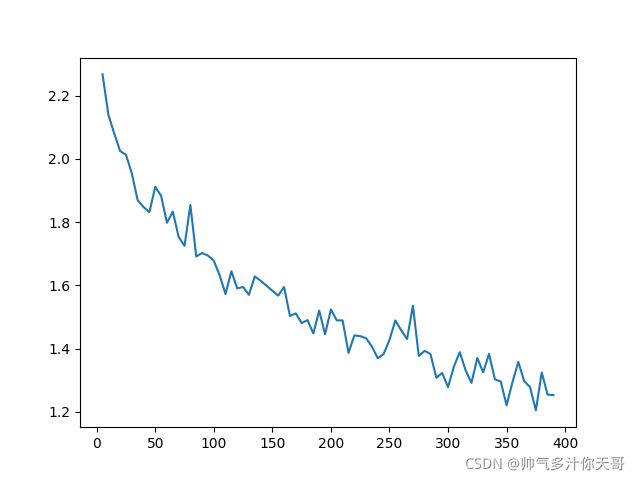
真实梯度下降 10个类别

此时只想放一首潘森的噢噢噢噢哦哦哦哦哦哦哦哦哦哦哦哦哦哦哦哦哦哦哦哦哦哦哦哦哦哦哦哦哦哦哦哦哦哦哦哦哦哦哦哦哦哦哦哦哦哦哦哦哦哦哦哦哦哦哦哦哦哦哦哦
epoch5 准确率80% omg


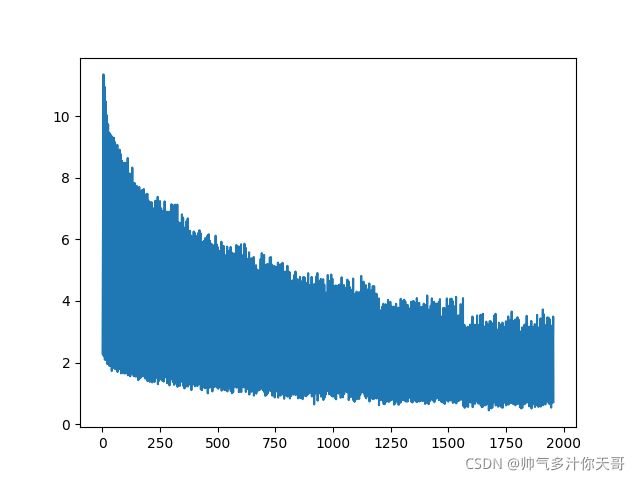
epoch30试一试呗? 裂开了
下降的比较均匀,到0.01数量级时希望不会过拟合和退化,说实话这么调参真没有googlenet方便…
看看准确率与epoch的关系…第一轮很不错 但是看看后面的…
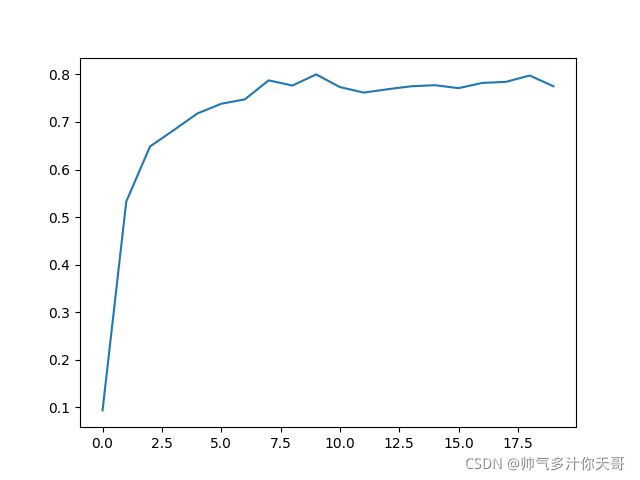
全局最优貌似已经找不到了,误差已经到0.01数量级了,再降低也就过拟合了

问题不是模型的问题了,如果能从数据中学到更多东西那么不需要及轮次准确率就可以上去,学不到了,才会上不去
这个模型的代码放上
import time
import torch
import torchvision
import torchvision.transforms as transforms
# import matplotlib.pyplot as plt
import numpy as np
import torch.optim as optim
import torch.nn as nn
import torch.nn.functional as F
import vgg
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
# self.f = stack_big((2, 2, 3, 3, 3), ((3, 64), (64, 128), (128, 256), (256, 512)))
net = []
for n, c in zip((2, 2, 5, 3), ((3, 64), (64, 128), (128, 256), (256, 512))):
in_c = c[0]
out_c = c[1]
net += [stack_mini(n, in_c, out_c)]
# self.f = nn.Sequential(*net)
self.f = nn.Sequential(*net)
# print(self.f)
self.fc = nn.Sequential(
nn.Linear(2 * 2 * 512, 384),
nn.SELU(True),
# nn.Tanh(),
nn.Linear(384, 192),
nn.SELU(True),
# nn.Tanh(),
nn.Linear(192, 10)
)
def forward(self, x):
# x = self.f(x)
x = self.f[0](x)
x = self.f[1](x)
x = self.f[2](x)
x = self.f[3](x)
x = x.view(x.shape[0], -1)
x = self.fc(x)
return x
def stack_mini(num_convs, in_channels, out_channels):
'''
block块 开始以卷积层开始,结束以池化层结束 过程中提取高纬数据
:param num_convs: 循环次数
:param in_channels: 输入通道数
:param out_channels: 输出通道数
:return:
'''
# 定义第一层并转换为list
net = [nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1), nn.SELU(True)] # 卷积+激活层
# 循环定义其它层
for i in range(num_convs - 1): # 卷积层+激活层
# net.append(nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1))
# net.append(nn.ReLU(True))
net += [nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1), nn.SELU(True)]
# 定义池化层
# net.append(nn.MaxPool2d(2, 2)) # 2*2 步长为2
net += [nn.MaxPool2d(2, 2)]
# return net
return nn.Sequential(*net)
def stack_big(num_convs, channels):
'''
创建数据提取模块
:param num_convs:[循环次数]list
:param channels:[(输入,输出),(输入维度,输出维度)]list
:return:数据特征提取网络
'''
net = []
for n, c in zip(num_convs, channels):
in_c = c[0]
out_c = c[1]
net += [stack_mini(n, in_c, out_c)]
return net
def loadData():
tf = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
trainset = torchvision.datasets.CIFAR10(root='../data', train=True, download=True, transform=tf)
trainLoader = torch.utils.data.DataLoader(trainset, batch_size=128, shuffle=True, num_workers=2)
testset = torchvision.datasets.CIFAR10(root='../data', train=False, download=True, transform=tf)
testLoader = torch.utils.data.DataLoader(testset, batch_size=128, shuffle=True, num_workers=2)
return trainLoader, testLoader
classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
def train_model_GPU(PATH):
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
print(device)
net = Net()
net = net.to(device)
criterion = nn.CrossEntropyLoss() # 交叉熵损失函数,因为是多分类问题,所以使用交叉熵损失
# 优化器
# optimizer = optim.SGD(net.parameters(), lr=1e-3) # momentum动量初始化 adam?
optimizer = optim.Adam(net.parameters(), lr=1e-4, betas=(0.9, 0.99))
# optimizer = optim.Adagrad(net.parameters(), lr=1)
# optimizer = optim.RMSprop(net.parameters(), lr=1e-3, alpha=0.9)
trainLoader, testLoader = loadData()
num = 0
list_num = []
list_num2 = []
y_list = []
y_list2 = []
accturly_list = []
accturly_x = []
for epoch in range(20):
# 所有数据循环n次训练
running_loss = 0.0
all = 0
for i in range(10):
all += evaluate_model2(net, device)
accturly_list.append(all / 10)
accturly_x.append(epoch)
for i, data in enumerate(trainLoader, 0):
# 所有数据训练一遍是一个epoch
inputs, labels = data[0].to(device), data[1].to(device)
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs, labels)
running_loss += loss.item()
loss.backward()
optimizer.step()
# print('lossitem', loss.item())
num += 1
list_num2.append(num)
y_list2.append(running_loss)
if (i + 1) % 5 == 0:
list_num.append(num)
y_list.append(running_loss / 5)
print(epoch + 1, i + 1, running_loss / 5)
running_loss = 0.0
import matplotlib.pyplot as plt
# plt.plot(list_num, y_list, linestyle='-')
plt.plot(list_num, y_list)
plt.savefig('./2demo.png')
plt.show()
plt.plot(accturly_x, accturly_list)
plt.show()
plt.savefig('accturly.png')
plt.plot(list_num2, y_list2)
plt.show()
plt.savefig('./demo.png')
print('finish fit')
torch.save(net.state_dict(), PATH)
def evaluate_model2(net, device):
# PATH = '../alex_net.pth'
a, testLoader = loadData()
correct = 0
total = 0
with torch.no_grad():
# 不进行求导
for i, data in enumerate(testLoader):
images, labels = data[0].to(device), data[1].to(device)
outputs = net(images)
_, predicted = torch.max(outputs.data, 1) # 输出中选取概率最大的值
if (i % 100 == 0):
print('输入图片images--->', images.shape) # torch.Size([4, 3, 32, 32])
print('真实标签labels--->', labels.shape) # torch.Size([4])
print('输出值outputs-->', outputs.shape) # torch.Size([4, 10])
print('预测值predicted--->', predicted, 'labels标签值--->', labels)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print(total, correct)
print(f'准确率为{100 * correct / total}')
return correct / total
def evaluate_model(PATH):
# PATH = '../alex_net.pth'
net = Net()
net.load_state_dict(torch.load(PATH))
a, testLoader = loadData()
correct = 0
total = 0
with torch.no_grad():
# 不进行求导
for i, data in enumerate(testLoader):
images, labels = data
outputs = net(images)
_, predicted = torch.max(outputs.data, 1) # 输出中选取概率最大的值
if (i % 100 == 0):
print('输入图片images--->', images.shape) # torch.Size([4, 3, 32, 32])
print('真实标签labels--->', labels.shape) # torch.Size([4])
print('输出值outputs-->', outputs.shape) # torch.Size([4, 10])
print('预测值predicted--->', predicted, 'labels标签值--->', labels)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print(total, correct)
print(f'准确率为{100 * correct / total}')
if __name__ == '__main__':
a = time.time()
train_model_GPU('../vgg2.pth')
b = time.time()
print(b - a)
evaluate_model('../vgg2.pth')
写个数据放大试一试把