干货!权衡偏差和方差的近似最优图神经网络邻接点采样器
点击蓝字

关注我们
AI TIME欢迎每一位AI爱好者的加入!


张庆儒:
2020年获得上海交通大学学士学位,现为佐治亚理工计算机系在读二年级博士生,曾在ICLR, NeurIPS发表多篇论文,他的主要研究方向为图数据与序列数据上的算法设计与理论分析。
内容简介
图神经网络在图相关的应用中取得了很好的表现,但随着工业界数据集规模的不断扩张,全部邻接点上的图卷积操作在计算上变得不可拓展。先有的工作现后提出了一些邻接点采样算法来解决这个问题,但他们大多缺乏可靠的理论保证,同时也仍会有很高的采样方差。在这篇文章中,我们将GNN的邻接点采样问题公式化为多臂老虎机问题(Multi-Armed Bandit, MAB),我们提出同时考虑采样偏差与方差,从而达到一个更好的权衡。通过显式地研究GNN巡练的动态方程,我们证明了提出的算法理论上可以达到接近最有的采样误差。
1
Background
Graph Convolution:图卷积操作由以下公式给定

Graph Convolution会根据给定的根节点v,将所有节点的weighted embedding加权到一起作为自己下一层的weighted embedding。

Notations:

Neighbor Sampling:

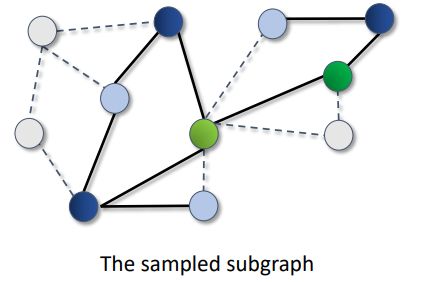
在大多数的sampling算法中,都会使用static policy,即pi,t是固定的。
The optimal pi,t,即可以把sampling variance降到最低的policy是关于zi,t的function
zi,t是会随时间变化而变化的,并且会有一个unknown dynamic
zi,t是partially observable的
所以,在这种情况下计算optimal policy是不可行的。为了解决static policy相关的上述问题,有学者进行了以下研究——多臂老虎机的问题。
2
BanditSampler (Liu et. al, 2020)

Adversary Multi-Armed Bandit (MAB)
在Bandit中,有一个player将会从k个老虎机中选一个来拉它的摇杆。然后这名player会受到相应arm的一个reward。最后会根据得到的reward去更新policy,pt。更新policy的算法一般有EXP3等。目标就是尽可能地最大化reward,以及等价于最小化其regret。
“Adversary”:每一个多臂老虎机的reward distribution是随时间变化而变化的,并不固定。
Multiple play Bandit:指我们可以同时抛多个arm,而不是单个的arm,并会有相应算法如EXP3.M等去更新对应的policy。
因此,根据以上特征,我们可以很容易联想到在neighbor sampling中,我们也是在interation中去sample k个neighbor。然后,我们得到了他的embedding,就可以计算出本次sampling的sampling的variance。当然,我们的最后目标是最小化这个sampling variance,因此我们可以把neighbor sampling转化成embedding问题,最后这个variance就会等价于regret,neighbor等价于arm。
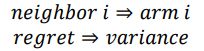

我们只需考虑sampling variance,因此我们对reward给出定义如下:
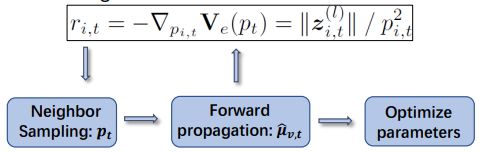
3
Limitation of BanditSampler
但是BanditSampler还是存在一些limitation的,首先是他们的regret分析。
Their Regret analysis
Policy的variance可以被upper bound:
![]()
因此当我们最大化reward的时候,也等价于我们最小化这个upper bound。同时也证明了BanditSampler可以自动的得到一个optimal variance。
![]()
Limitation of the existing regret
![]()
即每一步中最优的policy和最优的reward和当前的policy、reward的一个差值。

Limitation
Crucial Implicit Assumptions:
▪Reward distribution is independent with previous ▪actions (oblivious adversary): not hold for GNN training
n Bounded reward variation
Numerical Instability

4
Rethinking the reward
为解决上述问题,我们提出考虑bias-variance decomposition。
The bias-variance decomposition of approximation error
![]()


Trade Variance with Bias by a Biased Estimator
我们提出采用一个biased estimator去解决上述问题:
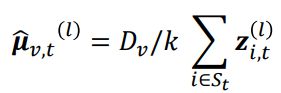
然后,我们同时优化bias和variance:
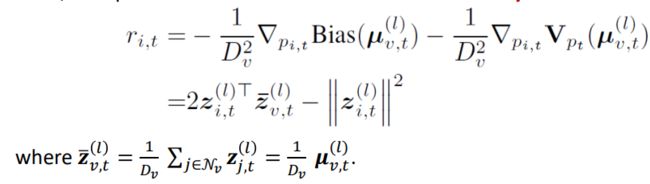
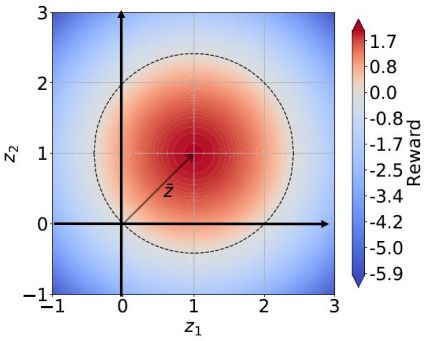
由于partial observability的问题,我们的practical reward如下定义:


Interpretation of our rewards:

![]()
5
Our Algorithm: Thanos
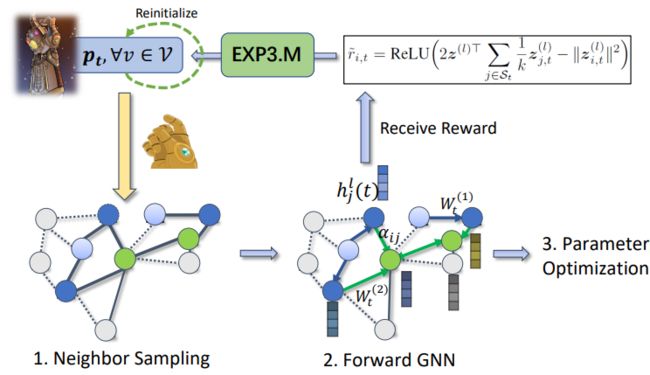
Thanos: “Thanos Has A Near Optimal Sampler
首先,我们根据当前的policy做neighbour sampling,当有了sample graph之后再做Forward GNN,然后就可以根据计算得到的reward去根据EXP3算法得到pt。
为了解决trade off问题,我们采用了每个Δt step去初始化policy。
6
Training Dynamic of GCN
SGD优化的GCN训练背景下的动态嵌入
递归地展开前向聚合和训练步骤
假设:

Reward Variation Budget

7
Regret Bound
Theorem 3 (Informal): 在与之前相同的假设下,regret of Thanos的最坏情况后悔可以被限制为

因此,我们可以说Thanos的sampling approximation error在以最快的速率converge到optimal oracle的。
总结:
我们的reward定义出了一个更加直接有效的regret
Reward的variation budget可以被公式化为embedding dynamic
我们还显式的推导了the training dynamic of GCN
8
Experiments
在合成数据集上比较Illustrating Policy的不同。
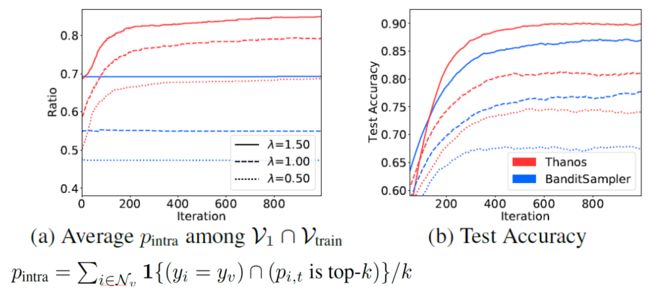
我们直接比较了sampling的approximation error。
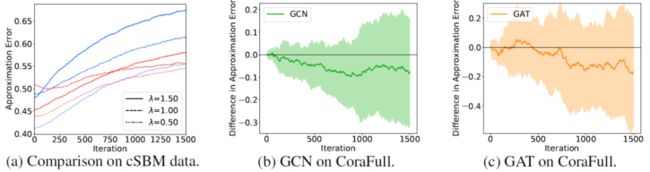
在CoraFull上研究BanditSampler的Norm Bias现象
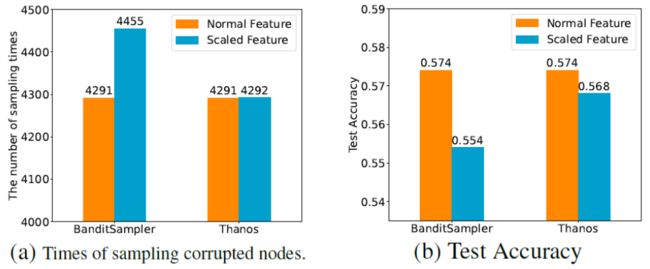
Thanos并不会受Norm Bias影响,他的表现也不会被降低许多,完美的解决了Norm Bias问题。
Benchmark Datasets
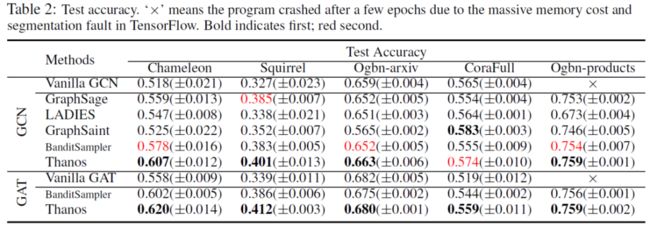
提
醒
点击“阅读原文”,即可观看本场回放
整理:林 则
作者:张庆儒
往期精彩文章推荐

记得关注我们呀!每天都有新知识!
关于AI TIME
AI TIME源起于2019年,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法和场景应用的本质问题进行探索,加强思想碰撞,链接全球AI学者、行业专家和爱好者,希望以辩论的形式,探讨人工智能和人类未来之间的矛盾,探索人工智能领域的未来。
迄今为止,AI TIME已经邀请了800多位海内外讲者,举办了逾400场活动,超400万人次观看。

我知道你
在看
哦
~
![]()
点击 阅读原文 查看回放!