自然语言处理(NLP)与知识图谱(KG)的发展史
我这个人比较磨叽,做什么事之前,都喜欢把相关技术的来龙去脉先了解清楚,有一个比较全面的认识之后,才开始动手。
关于NLP和KG,首先需要了解一下定义:
NLP即自然语言处理(Natural Language Processing),是研究人与计算机交互的语言问题的一门学科。说白了就是让计算机听懂人话的技术。
知识图谱(Knowledge Graph,KG),来源于谷歌的智能语义搜索引擎技术。其本质上是基于语义网络(semantic network)思想,的一种有向图结构的语义知识库,用于以符号形式描述物理世界中的概念及其相互关系。
其实,我在这里主要想聊的是实现知识表示和知识推理(强智能)的技术,这也是让人工智能可以像人类一样思考的重要一步,而知识图谱只是当前最流行的一种表达和实现方式。
那么,我为什么要把NLP和KG放在一起介绍呢?
主要是因为,近些年来,它们的技术已经开始逐步交融,相互影响和促进。实现了部分知识表示和知识推理的功能。
事实上,自然语言处理和智能一直都是紧密联系在一起的,人类之所以区别于其他动物,正是因为发明了语言和文字,可以通过它们将一代又一代的知识和经验积累和传承下去。所以语言本身就是智能的最重要载体,能够解析语言才是真正的智能。
一、自然语言处理
比尔盖茨曾经说过,“语言理解是人工智能皇冠上的明珠”。这句话表达了两个含义,自然语言处理,是人工智能的核心任务,但同时也是一个非常复杂艰巨的任务。
因此,让计算机听懂人话,不可能一蹴而就。需要分解为许多个小的任务和需求。常见的NLP任务有:翻译、摘要、对话、分类、聚类、情感、抽取、纠错等。
那么,如何解决这些问题,相关技术是如何发展的?
我在这里把NLP技术的发展,分为三个阶段:基于规则、统计机器学习和深度学习。
1、基于规则
这个也是我们最容易想到的、最直观的方法,即使是各种优秀模型层出不穷的现在,仍然有许多场景会用到基于规则的方法。下面我简单介绍几种常用的方法:
首先,是关键词匹配。比如,我想判断一条商品评论的情感倾向,就可以创建一组正面情感的关键词组,再创建一组负面情感的关键词组。分别进行字符串匹配,可以一定程度的判断出当前评论的情感倾向。
那么,如果有更复杂字符串匹配需求怎么办?那我们可以使用正则表达式,来进行匹配,具体方法可参考教程:正则表达式 – 简介 | 菜鸟教程
另外,当文本很长又很多时,关键词组匹配的效率太低怎么办?
字典树(Trie Tree)可以解决这个问题。它又称单词查找树,是一种树形结构,是一种哈希树的变种。它的优点是:利用字符串的公共前缀来减少查询时间,最大限度地减少无谓的字符串比较,查询效率比哈希树高。
除了匹配效率的问题,如果我想要模糊匹配,如何判断两行文本的相似度呢?
我们可以用莱文斯坦距离(Levenshtein Distance,LD),它是编辑距离的一种。指两个字串之间,由一个转成另一个所需的最少编辑操作次数。允许的编辑操作包括将一个字符替换成另一个字符,插入一个字符,删除一个字符。
那么,文本相似度=1-(莱温斯坦距离/最大字符串长度)
但是,这个方法也有缺点,比如对于文字顺序变化很大的文本,相似度计算出来就很低。
比如,“光明正大”和“正大光明”,这两个词在我们看来是一个意思,但是他们的莱温斯坦距离是4,相似度计算为0。
这种情况,我们可以使用杰卡德系数(Jaccard index),它不考虑顺序问题,用于计算两个集合的相似度,计算方式为:杰卡德系数=集合交集/集合并集。
在上面这个示例中,“光明正大”和“正大光明”的杰卡德系数为1。
当然,以上方法,只能解决一些简单的问题。如果涉及到稍微复杂一些的语义理解任务,这些方法的作用就十分有限了。
对于复杂的自然语言处理任务,最初也是尝试使用基于规则的方法来解决。最直观的想法就是:语言是有规则的,可以对语句和语义进行分析,从语法规则、词性和构词法等方面,教会计算机理解人类语言。
这大概是受到传统语言学研究的影响。因为随着16世纪欧洲开始对外进行文化输出,首先走向世界的是《圣经》,在翻译和输出的过程中,语言的语法得到总结和完善。到18、19世纪,西方的语言学家已经对各种语言进行了非常形式化的总结,形成了十分完备的体系。这些规则也是我们人类学习语言的好工具。而这些语法又很容易用计算机的算法进行描述,这就更加坚定了大家对基于规则的自然语言处理的信心。
20世纪80年代以前,自然语言处理工作中的文法规则基本上都是人工写的。科学家们设计了一些文法分析器,可以分析上百个词汇表,较短的简单语句。原本大家以为随着对自然语言语法概括的越来越全面,同时计算机能力的提高,基于规则的方法可以逐步解决自然语言理解的问题。
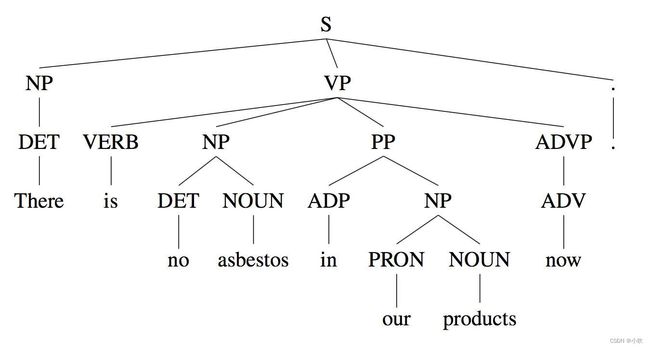
但是,这种想法很快遇到了麻烦。因为文法分析实际上是一件很啰嗦的事,一个简单的句子就能分析出一个复杂的二维树结构,还需要用到多条文法规则。对于稍微复杂的句子,就很难分析了。有人估算,要想通过文法规则覆盖20%的真实语句,至少需要几万条文法规则。语言学家们几乎已经是来不及写了,而且文法规则写到最后,有些规则甚至会出现矛盾。为了解决这些矛盾,又要为规则设置特定的使用环境。
更加麻烦的是,在自然语言中存在的多义词,需要通过上下文环境,甚至一些背景知识或者常识,才能正确描述。对于上下文有关的文法,其计算复杂度基本上是语句长度的六次方。这样的计算量,当前的计算机根本无法分析较长的真实语句。20世纪70年代,基于规则的句法分析技术很快就走到了尽头,更不必说更加复杂语义分析方法了。利用计算机进行自然语言处理的研究,努力到20世纪70年代初,可以说是相当失败的。
2、统计机器学习
1970年以后,统计语言学的出现,使得自然语言处理重获新生,推动这个技术转变的关键人物就是弗里德里克·贾里尼克和他领导的IBM华生实验室。

不过,最初他们也没有想要去解决整个自然语言处理的各种问题,而是只希望解决语音识别的问题。他使用信息论的方法,将语音识别当作一个通信问题,并用两个隐马尔可夫模型(声学模型和语言模型)把语音识别率从70%提升到90%,同时语音识别的规模从几百上升到几万单词,这直接将语音识别从实验室推向了实际应用。
他们的方法和成就在自然语言处理界引发了巨大的震动。但是,基于规则的方法和基于统计的方法之间的争执,还是持续了十几年。因为一项新研究方法的发展成熟,需要很多年。
1988年IBM的彼得·布朗等人提出了基于统计的机器翻译方法,其框架是对的,但是效果很差,因为当时没有足够的统计数据,也没有足够强大的模型来解决不同语言语序颠倒的问题。而布朗等人,随后也跑去文艺复兴技术公司(迄今为止最成功的对冲基金公司)发财去了。直到20世纪90年代,随着计算力和数据量的提高,基于统计的方法,才逐步超越了基于规则的方法。
那么,到底什么是基于统计的机器学习模型呢?
顾名思义,就是基于统计学方法的机器学习算法。那到底怎么用统计学方法来解决自然语言处理的问题呢?
下面我们来举一个例子。比如这里有一句话:
美联储主席本·伯南克昨天告诉媒体7000亿美元的救助资金将借给上百家银行、保险公司和汽车公司。
这句话看起来就很通顺,意思也很明确。
如果改变一些词的顺序,或者替换掉一些词,将这句话变成:
本·伯南克美联储主席昨天7000亿美元的救助资金告诉媒体将借给银行、保险公司和汽车公司上百家。
这个句子的意思就有些含糊了,不过多少还能看出一些意思来。
但是如果在打乱一些,变成:
联主美储席本·伯诉提南将借天的救克告媒昨助资金70元亿00美给上百百百家银保行、汽车险公司公司和。
基本上读者就不知所云了。
为什么会这样呢?一个只懂得基于规则的自然语言处理方法的科学家,可能会解释说,第一个句子合乎语法,词义清晰。第二个句子虽然语法有些问题,但词义还算清晰。而第三个句子连词义都不清晰了,所以难以理解。
这种解释很直观,也很容易理解。不过前文中也说过,基于规则的语法和词法分析,对于复杂一些的句子就变得难以处理,所以这条路走不通。
而贾里尼克换了一个角度,用一个简单的统计模型很漂亮的解决了这个问题。他的出发点很简单:一个句子是否合理,就看它出现的可能性大小如何。这里的可能性,就是用概率来衡量。第一个句子出现的概率大概是10-20,第二个句子出现的概率大概是10-25,第三个句子出现的概率是10-70。所以第一个句子最合理,出现的概率是第二个句子的10万倍,是第三个句子的一百亿亿亿亿亿亿倍。
下面我们来建立这个方法的数学模型:
假定S表示某一个有意义的句子,由一串特定顺序排列的词w1,w2,…,wn组成,这里n是句子的长度。那么S在所有文本中出现的概率就是P(S),由于S是由一列特定顺序的词组成,那么可以表示为:
P(s)=P(w1,w2,,…,wn)
根据贝叶斯公式,也就是条件概率公式,S这个序列出现的概率,等于每个词出现在特定位置的条件概率想乘,我们可以得到:
P(s)=P(w1)·P(w2| w1)·P(w3| w1,w2)·…·P(wn| w1,w2,…,wn-1)
P(w1)表示第一个词出现在句首的概率,P(w2| w1)表示w2出现w1在之后的概率,以此类推。可以看出wn出现的概率,与之前的词都有关。
从计算上来看,P(w1)很容易算,P(w2| w1)也还不算太麻烦,但P(w3| w1,w2)及非常难算了,它涉及到三个词,以及它们的顺序。再往后的条件概率,可能性已经多到几乎无法计算。
这个问题应当如何解决呢?
从19世纪到20世纪初,俄国有个数学家叫马尔科夫,他提出了一种偷懒但还颇为有效的方法,就是每当遇到这种情况时,就假设一个词wi出现的概率只同它前面的词wi-1有关,于是问题就变得很简单了,S出现的概率可以表示为:
P(s)=P(w1)·P(w2| w1)·P(w3|w2)·…·(wi|wi-1)···…·P(wn|wn-1)
这种假设在数学上称为马尔科夫假设,是一种对现实情况的近似计算。根据上述公式得到的统计语言模型是一个二元模型。当然也可以假设一个词由前N-1个词决定,对应的模型被称为N元模型。
在实际应用中,N一般不会超过3,因为当N从1到2,再从2到3时,模型的效果上升显著。而当N从3到4时,效果提升并不显著,而资源消耗却急剧上升。那么,模型从三元升到四元,甚至升到五元六元,是不是就能覆盖所有的语言现象呢?答案显然是否定的。在自然语言中,上下文的关联跨度可能非常大,甚至可能从一个段落跨到另一个段落。因此再怎么提高模型阶数,都无法解决问题,这也是马尔科夫假设的局限性。要解决这个长程依赖的问题,还需要其他的模型。
此外,这个模型还有如何训练,零概率问题和平滑方法等等细节需要解决。比如对于大部分词,当统计量足够大时,根据大数定理,可以把统计频率当作概率来使用。但有些词对,在语料库中并没有出现,或者只出现了一两次,如何估算其概率就比较棘手了。贾里尼克及其同事的贡献不仅仅在于提出了统计语言模型,而且还很漂亮的解决了所有细节问题,这才是其工作有意义的地方。具体的细节,我们就不在这里展开讨论了,感兴趣的可以自己去查阅相关资料。
以上,介绍了用统计机器学习解决自然语言处理问题的理论核心——统计语言模型。下面我们再来说一些经典的统计机器学习算法:
TF-IDF(Term Frequency - Inverse Document Frequency),用频率的手段来表征词语在文章中的重要性。其中TF(Term Frequency,缩写为TF)也就是词频,即一个词在文中出现的次数。这个很容易理解,在一篇文章里出现频率较高的词,对于这篇文章的主题的确认更加重要。
当然,这个办法有一个明显的漏洞,有些词在自然语言中的词频很高,但是它对文章的主题有没有什么用处。比如“的”,“是”,“和”等等,我们叫它“停止词”。还有一些词,比如“应用”,在汉语中虽然没有停止词那么多,但是也很通用。另外,还有一些专业的词汇,比如“原子能”,当它们频繁出现在一篇文章中时,显然在篇文章中很重要。那么如何平衡这些不同词汇的权重呢?
这里引入了一个叫“逆文本频率指数”(Inverse Document Frequency,缩写为IDF)的概念,它的计算公式为:
IDF = log(D/Dw)
其中D为所有文章的总数,Dw表示词语w在Dw篇文章中出现过。因此,Dw越大,w的权重越小,反之亦然。这样,就有:
TF-IDF = TF · IDF
那么,计算IDF的函数为什么是对数函数,而不是其他函数呢?
提出算法的人,并没有给出解释。后来经过研究发现,其实IDF的概念就是一个特定环境下关键词的概率分布的“交叉熵”。这也是用信息论来解决自然语言处理问题的又一个例证。
“熵”在信息论中是个基础的概念,十分重要。并且是在数学上得到了严格的证明。感兴趣的小伙伴,可以深入了解一下。这里就不详细展开讲解了。
BOC(bag-of-words,词袋),词袋模型其实是一类模型的统称,是将文本进行编码的一种方法。基本的方法是建立一个词表,统计一篇文章或者一段文本中各个词汇出现的次数,从而生成一个文本向量,来规范化的表示文本。其特点是只关注文本包含的词汇,而忽略词汇的顺序。向量长度等于词表长度,1表示该位置对应的词汇出现了一次,0表示该词汇没有出现,这种词汇的编码方式叫做one-hot。
可以看得出来,基本的词袋模型,就相当于与TF-IDF中的TF,也就是词频表示。为了增强词袋模型的表示能力,我们可以剔除词频很高但包含信息很少的“停止词”。还可以对不同的词加权重,比如用逆文本频率指数IDF作为权重,这样词袋又变成了TF-IDF [狗头]。
LDA(Latent Dirichlet Allocation,隐含狄利克雷分布),也是一种词袋模型,它可以通过无监督学习的方式,进行主题分类。此模型认为一篇文档是由一组词构成的一个集合,词与词之间没有顺序以及先后的关系。一篇文档可以包含多个主题,文档中每一个词都由其中的一个主题生成。它在训练时不需要手工标注的训练集,需要的仅仅是文档集以及指定主题的数量k即可,最终将文档集中每篇文档的主题按照概率分布的形式给出,对于每一个主题均可找出一些词语来描述它。
LSA(Latent Semantic Analysis,潜在语义分析),也是一种无监督学习方法,主要用于文本的话题分析,它通过矩阵分解发现文本与单词之间的基于话题的语义关系,从而得到话题向量空间以及文本在话题向量空间的表示,可用于信息检索。
在这一阶段,自然语言处理的方法处于百花齐放的阶段,基本上是八仙过海各显神通,并没有什么一家独大的方法。不像现在,大家都在从各个角度,疯狂内卷神经网络。
不过,对于自然语言处理方法的分类,倒是下了不少功夫,主要分为以下四大类:
(1)词法分析,包括分词、词性标注、实体识别、拼写检查等等。
(2)句法分析,包括句法结构分析、依存句法分析等等。
(3)语义分析,包括词义表示(词嵌入)、词义消歧、语义角色标注等等。
(4)文档分析,包括篇章结构,摘要,文档分类等等。
说到“分词”,尤其对于中文,一直是一个十分重要的技术。因为单个字的意思比较模糊,需要将句子先划分为含义比较明确的词,才能方便后续的处理。
最容易想到的分词方法,就是查字典,从左到右匹配字典中存在词汇。不过,语言中存在很多歧义性的场景,很难通过查字典的方法解决。随着统计语言模型的运用,分词的二义性基本得到了解决。到这里,分词已经属于一个已解决的问题,准确率提升的空间十分有限。
Jieba分词工具是一款优秀的python第三方中文分词库,基本上可以应付绝大部分场景的需求。jieba分词_IRON POTATO的博客-CSDN博客_jieba分词
近年来,随着深度神经网络技术在NLP领域的发展和应用,分词这个自然语言处理的中间过程,被逐步弱化。大部分情况下,只需将文本直接输入模型,就可以得到最终的结果。
那么,在深度学习大行其道的今天,传统的统计学习方法还在用吗?
答案是:在用,传统模型在可解释性和加强模型鲁棒性方面,对深度学习的方法可以有一定的补充。甚至基于规则的方法,在很多简单的场景中也在广泛使用。
下面我们就进入重头戏,来说说深度学习模型这个当红“炸子鸡”!
3、深度学习
事实上,深度学习模型也属于统计机器学习,只不过用深度神经网络代替了概率分布函数。深度神经网络的基础原理,可以参考我的另一篇文章《神经网络算法入门》。
深度学习的方法已经出现很多年了,但是在近十年才又再度收到关注。
2012年,AlexNet的横空出世,让深度学习从计算机视觉领域,火了起来。具体细节,可以参考我的这篇文章《CNN发展史+论文+代码》。
这把火很快就烧到了NLP领域,不过自然语言处理主要用的是RNN模型,因为语言都是词的序列。不过也有使用CNN的模型,但效果并没有十分亮眼。
下面,我就依次介绍一些我认为比较经典的工作。
首先是,word2vec(2013),其实这个模型并不叫word2vec,这只是作者所提供代码包的名字。论文中真正的模型有两个,分别是CBOW(Continuous Bag-of-Words)和Skip-gram。
CBOW翻译过来是连续词袋,看名字就知道肯定跟词袋有关系。那么这里的“连续”是什么意思呢?
我们上面讲过,最基本的词袋模型中,词是用one-hot的方法表示的,也就是说每个词向量之间都是正交的,它们相互独立,没有任何关系。而实际上,自然语言中的各个词显然是有关系的,有的词义很接近,比如“西红柿”和“番茄”,有些词义却没什么关系,比如“番茄”和“手机”,但“苹果”和“手机”倒是有很大的关系。将这些关系表示出来,就是这个“连续”的含义。
那么如何做到这一点呢?
word2vec的基本逻辑是:一条自然语言的语料中,相邻的词关系应该更加紧密;两个不同的词,如果它们在语料中,前后相邻的词都相同,那么它们的含义应该更加接近。
作者设计了CBOW和Skip-gram两个模型,来实现以上的逻辑。结构如下图所示:
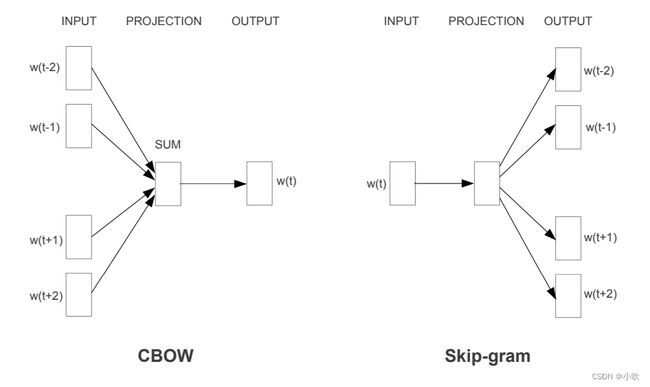
其中,CBOW是用周围词来预测中心词,Skip-gram是用中心词来预测周围词。最终得到的是一个词向量矩阵,可以将高维的one-hot词向量,转为低维的连续的词向量,从而得到不同词之间的关系。
词向量矩阵的一个例子如下图所示。这里的词表长度为5,那么一个词的one-hot表示就是一个5维向量,要将这个5维的向量投射到3维的空间中,需要乘以一个5x3的词向量矩阵,可以看的出来词向量矩阵的每一行,就是一个词向量。

将高维的one-hot词向量,映射到低维连续空间的方法叫做词嵌入(word embedding)。词嵌入方法可以更好表达出词与词之间的关系,用于后续的模型处理,能够一定程度的降低训练所需的样本量,提升模型效果。
详细资料可以参考:
论文:https://arxiv.org/pdf/1301.3781.pdf
博客:word2vec介绍_vincent_hahaha的博客-CSDN博客_word2vec
word2vec之后,涌现了更多词嵌入方式。例如:
GloVe(Global Vectors,2014),是融合了LSA的全局特征的矩阵分解,与word2vec的局部上下文的思想,引入了共现概率矩阵(Co-occurrence Probabilities Matrix)的无监督学习词向量表示方法。
上面介绍的词嵌入方法,虽然比one-hot词向量更好,但也有一个明显的问题。那就是训练得到的词向量是固定的。事实上,同一个词,在不同的语境中,表达的含义可能完全不同。这些静态的词嵌入方式,无法解决多义词的问题。那怎么办呢?
于是有人提出了ELMo(Embeddings from Language Models,2018.3)方法,用双向LSTM来表示语言模型。LSTM(长短记忆网络)是一种RNN模型,不了解的小伙伴,可以看看我的这边文章:《理解LSTM网络(Understanding LSTM Networks)原文与翻译》。
ELMo用两个LSTM模型,分别将一句话从前后两个方向依次输入,得到的对应向量拼接在一起,得到最终的词向量表示。这样就使得词向量中带了上下文的信息。具体结构如下图所示:

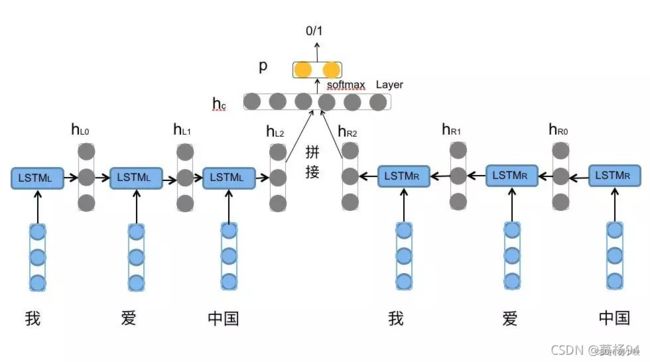
除了词嵌入以外,深度神经网络当然也是可以直接用于自然语言处理任务的。比较经典的模型有BiLSTM(双向长短记忆网络),用于文本分类的网络结构如下所示:
下面,一位重量级选手即将出场!
它就是Transformer(2017.12),提出这个模型结构的论文名字叫《Attention is All You Need》。正如这篇文章题目中说的那样,它主要提出了一种叫做注意力机制的模型结构。这种结构的逻辑在于:输入的句子中,每个词与其他词之间的关联程度都是不同的,这种关联就叫做注意力机制。如下图所示:

RNN模型虽然也可以很好的表达序列关系,但对于这种相隔多个词的关联关系,并不能很好的表达。
这种注意力是相互的,所以每个词都有一行与其他词关联的参数。最终的注意力参数是一个高宽都是句子长度的方形矩阵。句子长度为4的注意力参数矩阵,如下图所示:

注意力机制的具体结构如下图所示:

Q和K做矩阵乘法得到注意力参数矩阵,这是这篇文章最核心的贡献。注意力模块可以堆叠N层,模型整体结构如下图所示:

输入部分,由于没有了RNN结构,为了模型可以用到序列信息,加入了Positional Encoding。该向量偶数位用sin函数,奇数位用cos函数。计算公式如下所示:
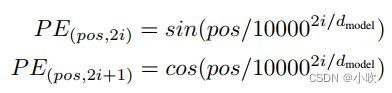
至于Positional Encoding为什么这样设置,论文中并没有给出详细的解释,我也没搞明白。反正最终这个模型有用,而且效果很好。
此外,由于这个模型最初是被设计用来解决翻译的问题,是个seq2seq的模型。所以加上了decoder模块。decoder的注意力模块加了一个mask层,使得decoder的输入序列,后面的词可以注意到前面的词,但前面的词无法注意到后面的词。
以上介绍了Transformer最关键的一些设计,详细的资料可以参考:
论文:https://arxiv.org/pdf/1706.03762v5.pdf
Transformer模型详解(图解最完整版):Transformer模型详解(图解最完整版) - 知乎
十分钟理解Transformer:十分钟理解Transformer - 知乎
由于Transformer过于优秀,产生了大量对其进行的研究和改进工作,甚至这种结构很快被应用到了计算机视觉领域,也取得了不错的效果。有人对这些研究进行了总结,具体的资料可以参考:
《A Survey of Transformers》论文:https://arxiv.org/pdf/2106.04554.pdf
《A Survey of Transformers》博客:复旦大学邱锡鹏教授团队:Transformer最新综述 - 知乎
Transformer的成功进一步推动了深度学习在NLP领域的应用和发展。目前应用的最新最好的模型,基本上都使用了注意力模块,并从各个角度进行了改进和优化。
BERT(Bidirectional Encoder Representation Transformers,2019),和Transformer一样,也是由谷歌的研发团队发布的模型。它的结构基本上就是Transformer的Encoder部分。如下图所示:

这个工作主要的贡献在于,确立了先用大量语料进行预训练,再针对特定场景数据微调的方法。
预训练中,主要使用了两个任务,MLM(Masked Language Model,掩码语言模型)和NSP(Next Sentence Prediction,预测下个句子)。
MLM是随机将句子中的部分词用特殊的标记[MASK]代替,并使用模型预测被掩码的词。NSP是将语料中前后相连的两个句子随机互换位置,并在输入是在句首插入[CLS]标记,使用模型预测是否对句子进行了顺序互换。
我们注意到,这两个预训练任务,都无需对语料库进行人工标注,而是可以用程序批量处理。这样就极大的增加了可训练语料的范围,从而获得效果更加好的模型。
另外,Transformer系的模型训练时,不必像RNN系的模型那样依赖上一个时刻的状态,可以并行训练,极大的提升了训练速度,这也是其可以支持大模型预训练的重要原因。
除此之外,BERT在输入的部分,增加了Segment Embedding,用于区分不同的句子,如下图所示:
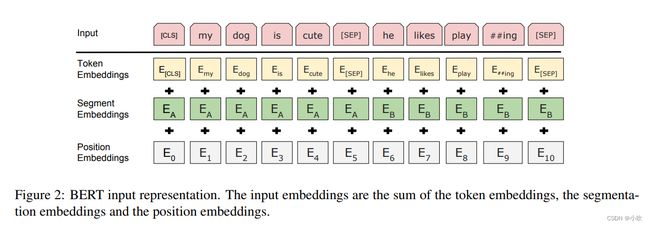
到目前为止,模型的基本结构已经没有大的更新,大家开始从模型的细节、训练任务和调优等方面优化模型的性能。
关于BERT的详细资料可以参考:
论文:https://arxiv.org/pdf/1810.04805v2.pdf
BERT 论文详细阅读笔记:BERT 论文详细阅读笔记 - 知乎
BERT详解1:BERT详解_yangdelong的博客-CSDN博客_bert
BERT详解2:BERT 详解_Decennie的博客-CSDN博客_bert详解
另外一个值得关注的模型是GPT(Generative Pre-Training),这是OpenAI发布的深度学习语言模型,它的使用了Transformer的decoder结构,所以输入的句子有方向性。而BERT用的encoder,没有mask层,这大概就是BERT叫做双向编码表示(Bidirectional Encoder Representation Transformers)的原因吧。
GPT的主要特点是大,目前最新的GPT-3甚至达到了1750亿的参数量,其生成的文本,已十分接近人类的表达方式。GPT也开启了各大机构疯狂内卷大模型的竞赛。
据说GPT-4也即将发布,其开发负责人曾在采访中暗示GPT-4已经通过了图灵测试!
GPT模型可参考论文:
https://s3-us-west-2.amazonaws.com/openai-assets/research-covers/language-unsupervised/language_understanding_paper.pdf
Transformer系的模型还有很多,这里只列举其中几个比较有名的模型。
XLNET,对BERT进行了改进,放弃BERT的自编码(AE,autoencoding)模式,采用GPT的自回归(AR,autoregressive)模式,同时进行了一些改进,巧妙地避免了AE和AR模型的传统缺点。
此外,还集成了Transformer-XL的相对位置编码与片段循环机制,改进了超长序列的依赖问题。详细介绍可参考:
论文:https://arxiv.org/abs/1906.08237v2
博客:最通俗易懂的XLNET详解_爱编程真是太好了的博客-CSDN博客_xlnet
Transformer-XL论文:https://arxiv.org/abs/1901.02860
RoBERTa(A Robustly Optimized BERT Pretraining Approach),也是对BERT的改进版本,这点从论文题目就可以看得出来。首先,它训练上增大了模型参数量;采用了更大的batch size;新增了训练数据。另外,训练方法上去掉了NSP任务;采用了动态掩码,也就是每轮训练Mask不同的词;文本编码采用Byte-Pair Encoding(BPE)是字符集和词级别表征的混合,也就是增大了词汇表,加入了很多subword单元。详细介绍可参考:
论文:https://arxiv.org/abs/1907.11692v1
博客:RoBERTa 详解_Decennie的博客-CSDN博客_roberta
StructBERT,是阿里巴巴达摩院提出的NLP预训练模型,也是在BERT基础上做出了一些改进。增加了词序重构任务,句子重构任务。详细介绍可参考:
论文:https://arxiv.org/pdf/1908.04577.pdf
博客:StructBERT解读_别水贴了的博客-CSDN博客_structbert
BART,是一个降噪自动解码器,seq2seq的模型,具有对损坏文本的双向编码器和一个从左到右的自回归解码器。它同时吸收了BERT和GPT的特点,预训练过程中,采用encoder部分添加各种噪声,在decoder上进行还原的方法。意图是破坏掉这些有关序列结构的信息,防止模型去“依赖”这样的信息。详细介绍可参考:
论文:https://arxiv.org/abs/1910.13461v1
博客:BART模型 - 知乎
中文领域,目前效果最好的模型是百度的ERNIE(Enhanced Representation through Knowledge Integration,2019),百度坚持简单有效的原则,并没有对模型结构做过多的修改,还是沿用的BERT的基本结构。
ERNIE1.0对训练任务进行了优化,mask任务除了BERT本身词级别的mask以外,还增加了短语级别的mask和实体级别的mask。另外还增加了DLM(Dialogue Language Model )任务。这不得不让人感叹百度作为互联网大厂,数据积累之多,与工程能力之强了。
ERNIE2.0增加了更多的训练任务,同时提出了一个叫做持续多任务学习(continual multi-task learning)的训练框架。
ERNIE3.0则是在2.0基础上继续探索持续多任务学习框架,并将模型参数量提升到100亿级别。同时还应用了近几年来的多种优化策略。详细介绍可参考:
论文:
ERNIE1.0:https://arxiv.org/abs/1904.09223v1
ERNIE2.0:https://arxiv.org/abs/1907.12412
ERNIE3.0:https://arxiv.org/abs/2107.02137
三个版本的ERNIE:ERNIE三个版本进化史 - 知乎
ERNIE详解:ERNIE 百度1/2 详解 - 知乎
代码:https://github.com/PaddlePaddle/ERNIE
其实还有一个ERNIE,是清华大学的ERNIE(Enhanced Language Representation with Informative Entities),这个模型也是希望通过实体信息对模型进行增强,不过它并没有完全沿用BERT的模型结构,而是针对实体信息的学习,附加了一些新的模型结构。不过它的名气相比百度ERNIE差得很远,也没有进行持续的优化。详细介绍可参考:
论文:https://aclanthology.org/P19-1139.pdf
两个ERNIE的对比:『清华ERNIE』 与 『百度ERNIE』 的爱恨情仇 - 知乎
这里说个有趣的小插曲,ELMO、BERT和ERNIE其实都《芝麻街》中的角色,这是一部美国儿童教育电视,相当于国内的《蓝猫淘气三千问》。现在再看看ERNIE的强行凑缩写,这百度和清华模型撞名的事,应该不是巧合。

除了对模型结构本身和训练任务的优化,还有一些有意思的研究,也非常有趣。
T5(Text-to-Text Transfer Transformer,2020),模型结构方面采用了原生的Transformer,主要在迁移学习方面进行了探索。通过为输入序列增加特殊的前缀,将许多不同的任务都统一为文本到文本的任务。详解介绍可参考:
论文:https://arxiv.org/pdf/1910.10683v3.pdf
博客:T5模型简介_愤怒的可乐的博客-CSDN博客_t5模型
UIE(Universal Information Extraction,2022),提出了一种统一的文本到结构(text-to-structure)的生成架构。设计了一种结构化抽取语言(Structural Extraction Language,SEL)将异构的信息抽取结构,编码成统一的表示。可以用一个统一的模型实现多种信息抽取任务。详解介绍可参考:
论文:https://arxiv.org/pdf/2203.12277.pdf
论文笔记:通用信息抽取UIE论文笔记_J_Xiong0117的博客-CSDN博客
示例:PaddleNLP/model_zoo/uie at develop · PaddlePaddle/PaddleNLP · GitHub
从上面的发展历程可以看得出来,除了模型结构,还有很多角度可以对自然语言处理任务进行优化,以应对复杂的现实需求。
那么,最近NLP领域最热的概念是什么呢?
我觉得是,提示学习(Prompt Learning)。当然,这个概念并不是今年才提出来的。随着GPT等大模型的发展,已经有不少相关的研究。
最近这个概念火起来,是因为一篇综述文章:
Pre-train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processing
所谓提示学习,是指通过一些提示语句,在不经过训练的情况下,引导大模型给出正确的预测结果。比如:

想要判断一条电影评论是正面的还是负面的,可以将这句话[X]拼接上提示语句“Overall,it was a [Z] movie”。通过模型预测的[Z]词,可以得到评论[X]的情感倾向。这只是一个简单的例子,还可以设计出更加精巧的提示语句,完成更加复杂一些的自然语言处理任务。
最令人惊喜的是,这种方法可以在完全不需要训练数据的情况下,得到不错的结果。这实在是低资源场景的福音。
那么,为什么提示学习,或者说大模型能够做到这一点呢?
其实脸书2019年的一篇文章可以一定程度上解释这个问题:语言模型即知识库(Language Models as Knowledge Bases)
论文:Language Models as Knowledge Bases? | Papers With Code
博客:Facebook - Language Models as Knowledge Bases 简介 - 知乎
如题所示,语言模型即知识库。由于大规模的预训练语言模型,在训练过程中学习了大量有意义的语料。因此它学到的不仅仅是语言的表达方式,也包含了很多知识。
事实上语言本身就是人类用于交流和传承知识的工具,也是智能的载体和重要表现方式。因此语言模型中包含了知识,不足为奇。提示学习,就是通过自然语言的方式,与模型进行交互,引导模型将使用这些知识用于处理特定的任务。
提示学习令我惊喜的地方,其实并不在于其低资源场景下的优秀表现。而在于找到了一种可以与语言模型沟通交互的方法。
我认为,完全可以通过模板化语言将语言模型和知识图谱结合在一起,一方面增强语言模型的能力,另一方面可以实现知识表示和推理,这很可能是未来实现强智能的一条道路。
当然这里还有许多问题需要解决:
(1)如何使用知识图谱数据迭代语言模型?
(2)如何建立标准化的知识图谱?
(3)如何将图谱转为语言表示?
(4)如何解决实体消歧等问题?
下面我们就先来聊聊什么是知识图谱,以及它是如何发展的。
二、知识图谱
上文中我们提到了“语言模型即知识库”这个概念。事实上,对于如何建立知识库,实现知识的表示和推理,也就是实现真正智能的研究,在计算机刚出现的时候就开始了。
只不过在连接主义(神经网络)兴起之前,占据主导地位的还是“符号主义”的研究。所谓符号主(Symbolism),是指通过一些确定含义的符号,实现基于逻辑推理的智能模拟方法,又称为逻辑主义(Logicism),心理学派(Psychlogism),或者计算机学派(Computerism)。
知识图谱就是一种符号主义的智能模拟方法,其发展历程大概可以分为以下六个阶段:
(1) 语义网络(Semantic networks)的概念由Quillian于1968年提出,顾名思义,就是一种表示知识的结构化方式,而且是特别针对语义信息的表述的,起初作为自然语言处理的数据组织方式而使用。其用相互连接的节点和边来表示知识。节点表示对象、概念,边表示节点之间的关系。例如:

(2) 本体论(Ontology)的概念早在1970年就开始于知识组织构建中引入。它其实是个哲学概念,从《荷马史诗》开始,就有了本体论的影子,经过无数世纪的探讨,又作为知识组织的理念,用于指导人工智能的展开。
它的关键在于让计算机能够处理人类的知识。然而,人类脑海中的知识通常是直觉性的,我们无法将这种直觉性的知识直接输入给计算机,Ontology 就是一种对知识建模,使计算机能够识别人类知识的方法。
本体通过对于概念(Concept)、术语(Terminology)及其相互关系(Relation, Property)的规范化(Conceptualization)描述,勾画出某一领域的基本知识体系和描述语言。
(3) 万维网(WWW)的概念始于1989年Berners-Lee T.提出的文档系统。新的知识组织形式叫超文本链接(HTML)。它是一种全局性的信息结构,将文档中的不同部分通过关键字建立链接关系,使信息得以用交互方式搜索。没错,这就是我们今天广泛使用的万维网的来源。
(4) 语义网(Semantic Web)于1998年Berners-Lee T.发表。它的核心是:通过给万维网上的文档(如:HTML)添加能够被计算机所理解的语义“元数据”(Meta data),从而使整个互联网成为一个通用的信息交换媒介。语义网通过使用标准、置标语言和相关的处理工具来扩展万维网的能力。
(5) 关联数据(Linked Data)是Bizer C.和Cyganiak R.于2007年提交的Linked Open Data Project中提出,关联开放数据云是一个全球分布的数据网络,实际上,它可以看作一个跨越整个网络的数据库。Linked Data开始提出使用三元组来描述数据资源。
(6) 知识图谱(Knowledge Graph)于2012年5月16日Google的产品中发布,是一个较以往更为复杂的结构化数据源,被用于搜索引擎。
事实上,知识图谱的提出,并不是在论文里,而是在一篇谷歌的官方博客中:《Introducing the Knowledge Graph: things, not strings》。
作者辛格尔博士对知识图谱的介绍很简短:things,not string。这抓住了知识图谱的核心,也点出了知识图谱加入之后搜索发生的变化。以前的搜索,都是将要搜索的内容看作字符串,结果是和字符串进行匹配,将匹配程度高的排在前面,后面按照匹配度依次显示。
利用知识图谱之后,将搜索的内容不再看作字符串,而是看作客观世界的事物,也就是一个个的个体。搜索比尔盖茨的时候,搜索引擎不是搜索“比尔盖茨”这个字符串,而是搜索比尔盖茨这个人,围绕比尔盖茨这个人,展示与他相关的人和事,左侧百科会把比尔盖茨的主要情况列举出来,右侧显示比尔盖茨的微软产品和与他类似的人,主要是一些IT行业的创始人。一个搜索结果页面就把和比尔盖茨的基本情况和他的主要关系都列出来了,搜索的人很容易找到自己感兴趣的结果。
这篇博客中,只是给出了知识图谱的概念,并没有严格的定义和标准。事实上,时至今日,知识图谱仍未形成统一的标准,但其核心含义就是用于知识的表达和推理。
知识图谱的本质就是一种网状知识库,用于直观的表示这些知识实体与知识实体,或者知识实体与知识属性之间的联系。它是由一个个知识三元组组成。目前知识三元组的形式有两种,分别是<实体1,关系,实体2>和<实体1,属性1,属性值>。
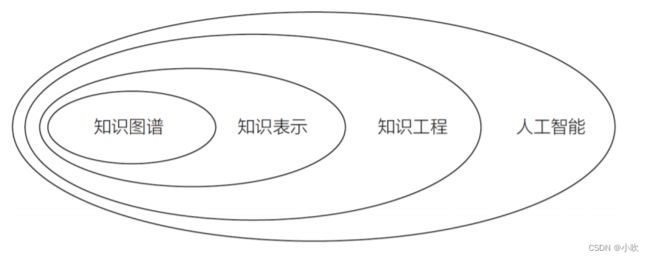
知识图谱具有如下3种特点:
(1)数据及知识的存储结构为有向图结构。有向图结构允许知识图谱有效地存储数据和知识之间的关联关系;
(2)具备高效的数据和知识检索能力。知识图谱可以通过图匹配算法,实现高效的数据和知识访问;
(3)具备智能化的数据和知识推理能力。知识图谱可以自动化、智能化地从已有的知识中发现和推理多角度的隐含知识。
目前,知识图谱技术已经在互联网领域如搜索引擎、智能问答等发挥了重要作用,同时也已经在多个领域进行初步应用,比如:金融、电商、医疗等。许多国际著名企业也已经开始探索知识图谱的应用,比如谷歌、微软、IBM、苹果等。
知识图谱另外一个很重要的概念是 Schema,即限定待加入知识图谱数据的格式;相当于某个领域内的数据模型,包含了该领域内有意义的概念类型以及这些类型的属性。
其作用是规范结构化数据的表达,一条数据必须满足Schema预先定义好的实体对象及其类型,才被允许更新到知识图谱中。
一图胜千言,下图中的DataType限定了知识图谱节点值的类型为文本、日期、数字(浮点型与整型)。图中的Thing限定了节点的类型及其属性。
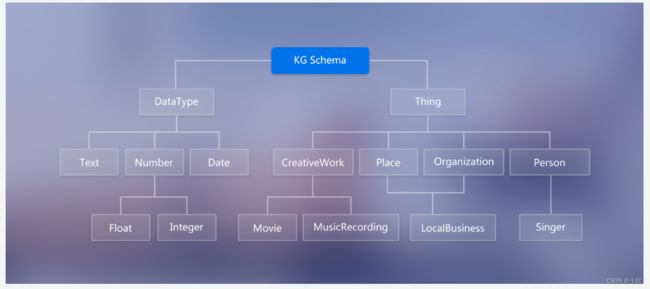
图中Schema构建的知识图谱中仅可含作品、地方组织、人物;其中作品的属性为电影与音乐、地方组织的属性为当地的商业(如:饭店、俱乐部等)、人物的属性为歌手。
下图是一个普遍认同的知识图谱构建过程,主要分为四个阶段:知识获取、信息抽取、知识融合和知识加工。
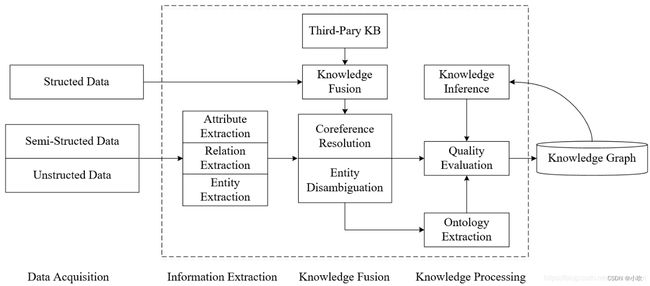
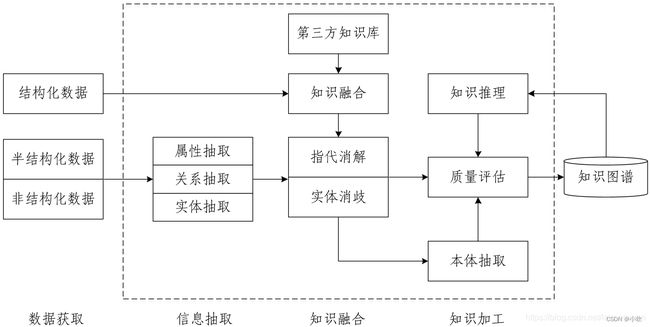
1、数据获取(Data Acquisition)
主要包括结构化数据、半结构化数据和非结构化数据。
2、信息抽取(Information Extraction)
(1)实体抽取(Entity Extraction)/命名实体识别(Name Entity Recognition),从数据中获取实体信息。
(2)关系抽取(Relation Extraction),从数据中获取实体之间的关系。
(3)属性抽取(Attribute Extraction),从数据中获取实体对应的属性数据。
3、知识融合(Knowledge Fusion)
(1)指代消解(Coreference Resolution),就是把代表同一实体的不同指称,划分到一个等价集合中。
(2)实体消歧(Entity Disambiguation),是指同一个词可能有多个意思,需要在不同的上下文中识别出这个词指代的是哪个实体。
(3)实体链指(Entity Linking),是一种任务,它要求我们将非结构化数据中的表示实体的词语(即所谓mention,对某个实体的指称项)识别出来,并将从知识库(领域词库,知识图谱等)中找到mention所表示的那一个实体。实体链指一般包括,实体识别、候选实体获取、实体消歧这三个主要环节。
(4)知识融合(Knowledge Fusion),将不同知识库中的知识合并在一起,需要进行本体对齐和实体匹配。
4、知识加工(Knowledge Processing)
(1)本体(Ontology)和本体构建(Ontology Extraction)
本体和知识图谱都通过定义元数据以支持语义服务。不同之处在于:知识图谱更灵活, 支持通过添加自定义的标签划分事物的类别。本体侧重概念模型的说明,能对知识表示进行概括性、抽象性的描述,强调的是概念以及概念之间的关系。
大部分本体不包含过多的实例,本体实例的填充通常是在本体构建完成以后进行的。知识图谱更侧重描述实体关系,在实体层面对本体进行大量的丰富与扩充。
可以认为,本体是知识图谱的抽象表达,描述知识图谱的上层模式;知识图谱是本体的实例化, 是基于本体的知识库。
(2)知识推理(Knowledge Inference),是指通过图谱进行推理并得到结论的过程。
(3)质量评估(Quality Evaluation),可以将图谱应用在某个具体任务,通过任务效果来反应图谱的质量。
三、未来展望
人工智能的发展,在最近十年取得了长足的进步,涌现出许多令人振奋的产品和研究成果。但目前的智能水平,仍然停留在感知智能阶段。距离像人类一样,甚至超越人类的强智能,还有相当的距离。目前还只能代替人类完成部分简单重复的劳动。想要具备在复杂场景下判断和决策的能力,还有很长的路要走。
不过,即便是人工智能技术的一点点突破,都可以很大程度的促进生产力的发展进步。以下是我认为的,四个比较重要的人工智能待突破方向:
1、深度神经网络可解释性研究,能够增强深度神经网络的可靠性,同时也有助于模型的持续学习和优化。
2、模型的持续学习与更新,让模型可以像人一样持续进步,使得知识可以传承和转移。
3、处理时间序列数据,让模型能够理解事物发展变化的过程,而不是只学到一个静态知识库,同时也有助于模型进行更加复杂的推理。
4、语言模型与知识图谱结合,这是目前看来让深度神经网络模型实现知识推理和可解释性的一种方法。
如果可以在这四个方面做出一些贡献,都将是里程碑式的工作,能够极大地促进人工智能技术,甚至人类社会的发展!
以上,只是我学习在NLP和KG过程中的一些总结和感悟,水平有限,错漏难以避免,如有发现,还请不吝指正!
参考资料:
[1] 《数学之美》作者:吴军
[2] NLP的发展历程:NLP的发展历程 - 知乎
[3] NLP基础算法总结:NLP基础算法总结_平原2018的博客-CSDN博客_nlp算法
[4]【从入门到高阶】NLP 算法:【从入门到高阶】NLP 算法的流程、主要任务及涉及算法,全都囊括了(Python 实战)_Python数据挖掘的博客-CSDN博客_nlp流程
[5] 计算文本相似度的常用算法:
计算文本相似度的常用算法_氧小氢的博客-CSDN博客_文本相似度算法
[6] 什么是知识图谱:
什么是知识图谱?
[7] 知识图谱入门——认识知识图谱:知识图谱入门——认识知识图谱 - 知乎
[8] 知识图谱简介:知识图谱(Knowledge Graph)简介 - 知乎
[9] 图计算思维与实践(一)概览:图计算思维与实践 (一)概览 - 知乎
[10] 知识图谱构建技术一览:知识图谱构建技术一览_lairongxuan的博客-CSDN博客_知识图谱构建技术
[11] 知识图谱综述文章:https://arxiv.org/pdf/2002.00388.pdf