神经网络应用: 手写数字识别(MNIST数据集)
1. 前言
本文使用 tensorflow 2.10.0 版本构建神经网络模型并进行训练,不同版本之间的 API 可能会有不同,请选择合适的版本学习。
2. MNIST 数据集介绍
MNIST数据集(Mixed National Institute of Standards and Technology database)是美国国家标准与技术研究院收集整理的大型手写数字数据库,该 数据集包含 60000 个⽤于训练的样本和 10000 个⽤于测试的样本,图像是固定⼤小 (28x28 像素 ),每个像素的 值为0 到 255,通道数为 1(灰度图), 如下图所示:

其中 tensorflow 包含了 MNIST 数据集,可直接导入使用。
3. 代码实现
3.1 导入所需的工具包
# 导入相应的工具包
import numpy as np
from matplotlib import pyplot as plt
# tf 中使用工具包
import tensorflow as tf
# 数据集
from tensorflow.keras.datasets import mnist
# 构建模型
from tensorflow.keras.models import Sequential
# 导入需要的层
from tensorflow.keras.layers import Dense, Dropout, Activation, BatchNormalization
# 导入辅助工具包
from tensorflow.keras import utils
# 正则化
from tensorflow.keras import regularizers3.2 加载数据集并显示部分数据
# 数据集中的类别总数
nb_classes = 10
# 加载数据集
(X_train, y_train), (X_test, y_test) = mnist.load_data()查看训练数据集和测试数据集的大小
X_train.shape
X_test.shape
展示训练数据集其中的一条数据
# 显示数据
plt.figure()
plt.rcParams['figure.figsize'] = (7, 7)
plt.imshow(X_train[1], cmap='gray')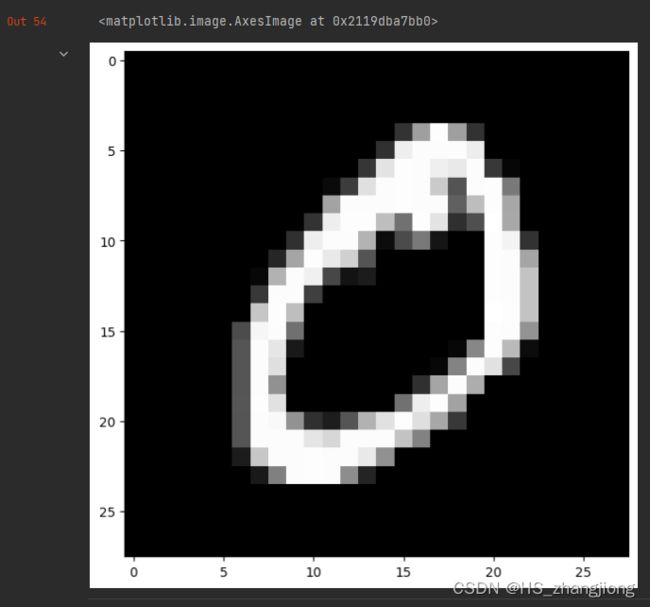
3.3 数据处理
神经⽹络中的每个训练样本是⼀个向量,因此需要对输⼊进⾏重塑,使每个28x28的图像成为⼀个784维的向量。另外,将输⼊数据进⾏归⼀化处理,从0-255调整到0-1。
# 调整数据维度: 每一个数字转换成一个向量
X_train = X_train.reshape(60000, 784)
X_test = X_test.reshape(10000, 784)
# 格式转换
X_train = X_train.astype('float32')
X_test = X_test.astype('float32')
# 归一化
X_train /= 255
X_test /= 255
# 维度调整后的结果
print(f'训练集: {X_train.shape}')
print(f'测试集: {X_test.shape}')
另外对于标签值我们也需要进行处理,将其转换为独热编码(one-hot encoding)的形式。对于一个标量来说就需要将其转换为一个向量,其中向量的维度就是标签中样本的类别个数。

# 将目标值转换成独热编码的形式
y_train = utils.to_categorical(y_train, nb_classes)
y_test = utils.to_categorical(y_test, nb_classes)3.4 模型构建
本文构建具有 2 个隐藏层和 1 个输出层的全连接网络,其中隐藏层的神经元个数均为 512,输出层神经元个数为 10。
# 利用序列模型来构建模型
model = Sequential()
# 全连接层, 共 512 个神经元, 输入维度大小为 784
model.add(tf.keras.Input(shape=(784,)))
model.add(Dense(512))
# 激活函数使用 relu
model.add(Activation('relu'))
# 使用正则化方法 dropout
model.add(Dropout(0.2))
#全连接层 512个神经元 加入 L2 正则化
model.add(Dense(512, kernel_regularizer = regularizers.l2(0.001)))
# BN 层
model.add(BatchNormalization())
# 激活函数
model.add(Activation('relu'))
model.add(Dropout(0.2))
# 输出层 共 10 个神经元
model.add(Dense(10))
# softmax 将神经网络的输出的 score 转换为概率值
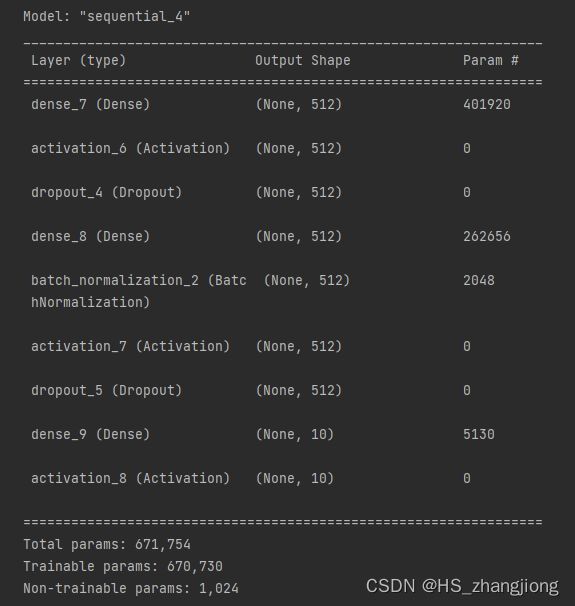
model.add(Activation('softmax'))使用 model.summary() 查看模型的架构
3.5 模型编译
设置模型训练使⽤的损失函数交叉熵损失和优化⽅法 Adam,损失函数⽤来衡量预测值与真实值之间的差异,优化器⽤来使⽤损失函数达到最优。
# 模型编译 指明损失函数和优化器 评估指标
model.compile(loss='categorical_crossentropy', optimizer='Adam', metrics=['accuracy'])3.6 模型训练
指定 batch_size 大小为 128,将 128 个样本同时送入网络进行训练,迭代 10 次(epochs = 10)。
# batch_size 是每次送入模型的样本个数, epochs 是所有样本的迭代次数, 并指明验证数据集
history = model.fit(X_train, y_train, batch_size=128, epochs=10, validation_data=(X_test, y_test))训练过程如下:
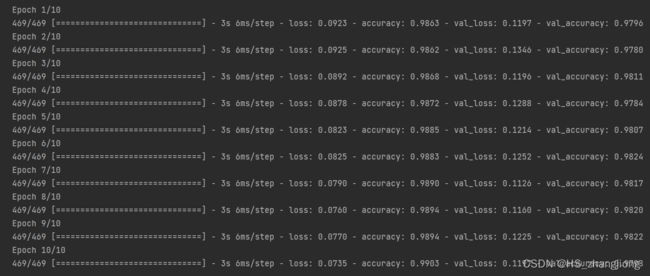
可视化损失函数和模型训练精确度
# 绘制损失函数的变化曲线
plt.figure()
# 训练集损失函数变化
plt.plot(history.history['loss'], label='train_loss')
# 验证集损失函数变化
plt.plot(history.history['val_loss'], label='val_loss')
plt.legend()
# 绘制网格
plt.grid()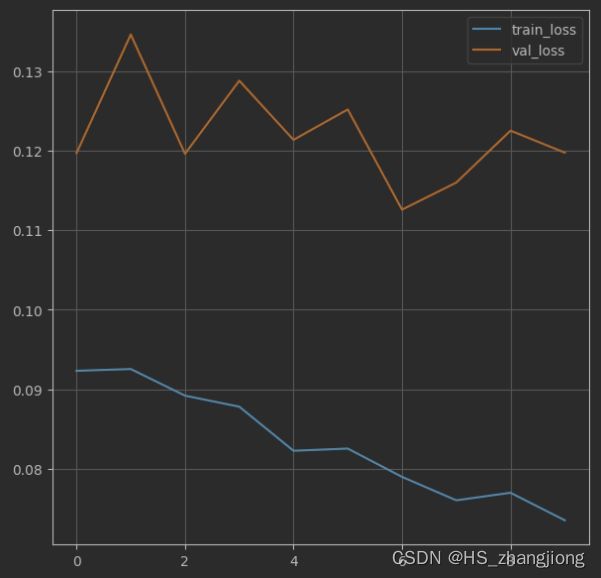
# 绘制准确率的变化曲线
plt.figure()
# 训练集损失函数变化
plt.plot(history.history['accuracy'], label='train_accuracy')
# 验证集损失函数变化
plt.plot(history.history['val_accuracy'], label='val_accuracy')
plt.legend()
plt.grid()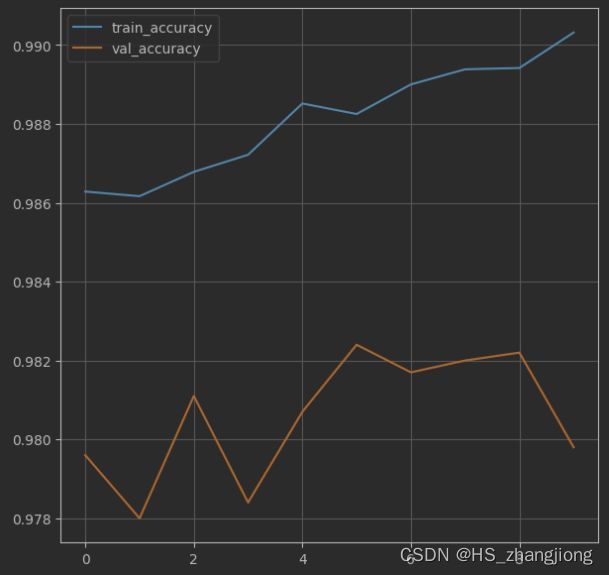
3.7 模型测试(评估)
# 模型测试
score = model.evaluate(X_test, y_test, verbose=1)
# 打印结果
print(f'测试集准确率: {score}')
3.8 模型保存与加载
可以将训练好的模型保存到文件中,其中包括了权重W和偏置b
# 保存模型架构与权重在 h5 文件中
model.save('my_model.h5')
# 加载模型 包括对应的架构和权重
model = tf.keras.models.load_model('my_model.h5')
# 测试加载的模型
model.evaluate(X_test, y_test, verbose=1)