神经网络学习笔记3——LSTM长短期记忆网络
目录
1.循环神经网络
1.1循环神经网络大致结构
1.2延时神经网络(Time Delay Neural Network,TDNN)
1.3按时间展开
1.4反向传播
1.5 梯度消失,梯度爆炸
2.lstm门控原理
3Matlab实现
整个博文,原理和代码实现建议配合视频食用,口感更佳
LSTM长短期记忆网络从原理到编程实现
LSTM长短期记忆网络从原理到编程实现_哔哩哔哩_bilibili
代码链接
链接:https://pan.baidu.com/s/1lrtbjpgpegiAGLOLLZcYoA
提取码:5lt3
--来自百度网盘超级会员V5的分享
要讲LSTM首先要了解下他所属的大类循环神将网络
1.循环神经网络
1.1循环神经网络大致结构
循环神经网络(Recurrent Neural Network ,RNN)是一类具有短期记忆能力的神经网络.在循环神经网络中,神经元不但可以接受其他神经元的信息,也可以接受自身的信息,形成具有环路的网络结构。
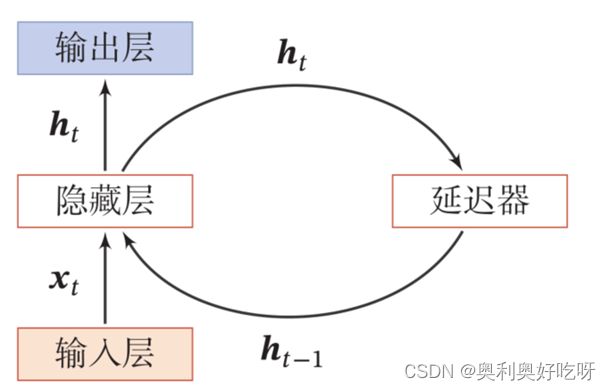
1.2延时神经网络(Time Delay Neural Network,TDNN)
循环神经网络如何形成短时记忆?
答:建立一个额外的延时单元,用来存储网络的历史信息(可以包括输入、输出、隐状态等)
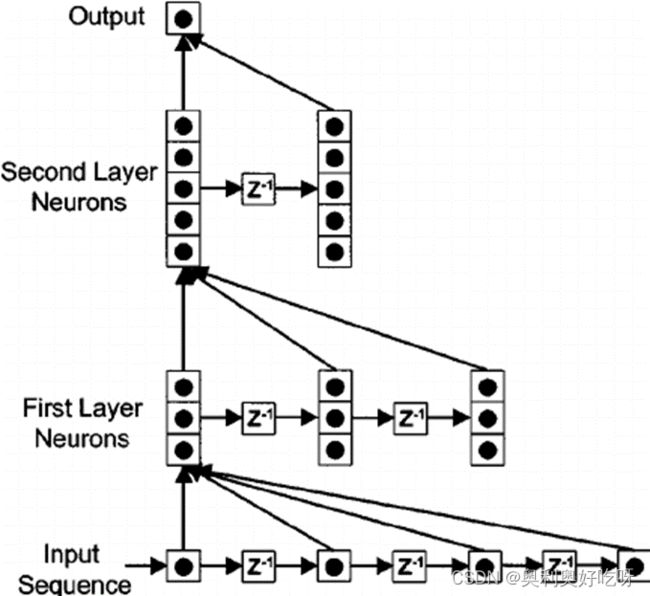
1.3按时间展开


可以从图中直观的看出影响
1.4反向传播


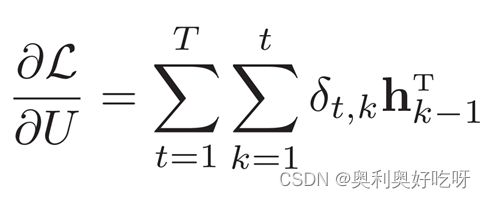
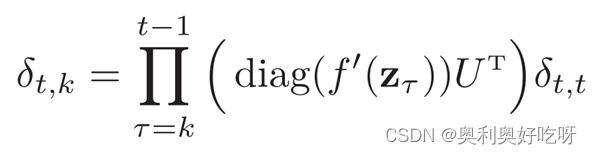
δt,k为第t时刻的损失对第k步隐藏神经元的净输入zk的导数
1.5 梯度消失,梯度爆炸
梯度 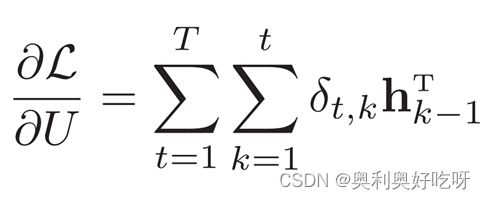

梯度爆炸问题: 梯度消失问题:
权重衰减 调整模型
梯度截断
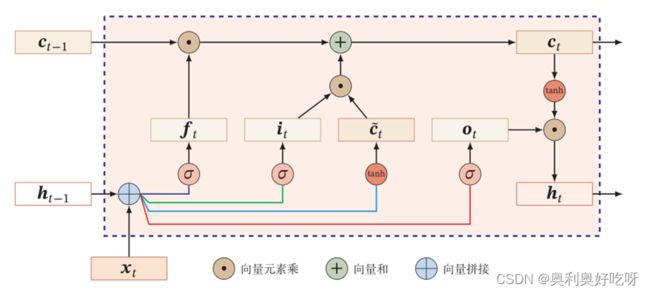
2.lstm门控原理

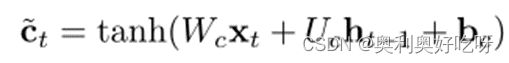
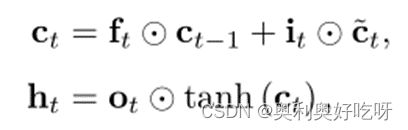
3Matlab实现
(1)加载序列数据
加载语音训练数据。 XTrain是一个包含270个12维可变长度序列的单元数组。 Y是标签“1”,“2”,… ,“9”,对应9个说话者。 XTrain中的条目是有12行(每个特性一行)和不同数量的列(每个时间步骤一列)的矩阵。
[XTrain,YTrain] = japaneseVowelsTrainData;
XTrain(1:5)(2)在绘图中可视化第一个时间序列。每行对应一个特征。
figure
plot(XTrain{1}')
xlabel("Time Step")
title("Training Observation 1")
numFeatures = size(XTrain{1},1);
legend("Feature " + string(1:numFeatures),'Location','northeastoutside')(3)准备要填充的数据
准备填充数据
在训练过程中,默认情况下,软件将训练数据分成小批量,并填充序列,使它们具有相同的长度。 过多的填充会对网络性能产生负面影响。
为了防止训练过程中添加过多的填充,可以按序列长度对训练数据进行排序,并选择一个迷你批大小,以便迷你批中的序列具有相似的长度。 下图展示了排序前后填充序列的效果。

获取每个观测值的序列长度。
numObservations = numel(XTrain); % 取样本个数
for i=1:numObservations
sequence = XTrain{i};
sequenceLengths(i) = size(sequence,2); %取序列长度个数
end(4)按序列长度对数据进行排序。排序为了把相似的放在一起使用小批量。
[sequenceLengths,idx] = sort(sequenceLengths);
XTrain = XTrain(idx);
YTrain = YTrain(idx);(5)在条形图中查看排序的序列长度。
figure
bar(sequenceLengths)
ylim([0 30])
xlabel("Sequence")
ylabel("Length")
title("Sorted Data")(6)选择小批量大小 27 以均匀划分训练数据,并减少小批量中的填充量。下图说明了添加到序列中的填充。因为数据总量是270个所以每十个一组使用小批量
miniBatchSize = 27;(7)定义 LSTM 网络架构
定义 LSTM 网络架构。将输入大小指定为序列大小 12(输入数据的维度)。指定具有 100 个隐含单元的双向 LSTM 层,并输出序列的最后一个元素。最后,通过包含大小为 9 的全连接层,后跟 softmax 层和分类层,来指定九个类。
如果您可以在预测时访问完整序列,则可以在网络中使用双向 LSTM 层。双向 LSTM 层在每个时间步从完整序列学习。如果您不能在预测时访问完整序列,例如,您正在预测值或一次预测一个时间步时,则改用 LSTM 层。
inputSize = 12;
numHiddenUnits = 100;
numClasses = 9;
layers = [ ...
sequenceInputLayer(inputSize) %输入层
bilstmLayer(numHiddenUnits,'OutputMode','last') %lstm结构和隐含层 last表示序列到标签分类
fullyConnectedLayer(numClasses) %全连接层设置类别
softmaxLayer %softmax多分类求每一类的概率
classificationLayer] 现在,指定训练选项。指定求解器为 'adam',梯度阈值为 1,最大轮数为 100。要减少小批量中的填充量,请选择 27 作为小批量大小。要填充数据以使长度与最长序列相同,请将序列长度指定为 'longest'。要确保数据保持按序列长度排序的状态,请指定从不打乱数据。
由于小批量数据存储较小且序列较短,因此更适合在 CPU 上训练。将 'ExecutionEnvironment' 指定为 'cpu'。要在 GPU(如果可用)上进行训练,请将 'ExecutionEnvironment' 设置为 'auto'(这是默认值)。
maxEpochs = 100; %设置迭代次数
miniBatchSize = 27; %设置小批量参数
options = trainingOptions('adam', ... %训练网络求解器 训练选项指定梯度和平方梯度移动平均值的衰减率。
'ExecutionEnvironment','cpu', ... %选择cpu,或者gpu
'GradientThreshold',1, ... % Adam 求解器的梯度移动平均衰减率,指定为小于 的非负标量1。梯度衰减率在Adam部分中表示。必须是 'adam'。默认值适用于大多数任务
'MaxEpochs',maxEpochs, ... % 迭代步数
'MiniBatchSize',miniBatchSize, ... %用于每次训练迭代的小批量的大小,指定为正整数。小批量是训练集的子集,用于评估损失函数的梯度并更新权重。提高性能增加泛化能力
'SequenceLength','longest', ... %序列长度
'Shuffle','never', ...
'Verbose',0, ... % 在命令窗口中显示训练进度信息的指示器,指定为 1(true) 或0(false)。
'Plots','training-progress'); % 绘制训练过程Shuffle用法
数据洗牌的选项,指定为下列之一:
'once'— 在训练之前对训练和验证数据进行一次洗牌。
'never'— 不要打乱数据。
'every-epoch'— 在每个训练 epoch 之前打乱训练数据,并在每个网络验证之前打乱验证数据。如果 mini-batch 的大小没有均匀地划分训练样本的数量,则trainNetwork丢弃不适合每个 epoch 的最终完整 mini-batch 的训练数据。为避免在每个 epoch 丢弃相同的数据,请将Shuffle训练选项设置为 'every-epoch'。
(8)训练 LSTM 网络
使用 trainNetwork 以指定的训练选项训练 LSTM 网络。
net = trainNetwork(XTrain,YTrain,layers,options); (9)测试 LSTM 网络
加载测试集并将序列分类到不同的说话者。
加载语音测试数据。XTest 是包含 370 个不同长度的 12 维序列的元胞数组。YTest 是由对应于九个说话者的标签 "1"、"2"、...、"9" 组成的分类向量。
[XTest,YTest] = japaneseVowelsTestData;
XTest(1:3)LSTM 网络 net 已使用相似长度的小批量序列进行训练。确保以相同的方式组织测试数据。按序列长度对测试数据进行排序。
numObservationsTest = numel(XTest);
for i=1:numObservationsTest
sequence = XTest{i};
sequenceLengthsTest(i) = size(sequence,2);
end
[sequenceLengthsTest,idx] = sort(sequenceLengthsTest);
XTest = XTest(idx);
YTest = YTest(idx);对测试数据进行分类。要减少分类过程中引入的填充量,请将小批量大小设置为 27。要应用与训练数据相同的填充,请将序列长度指定为 'longest'。
miniBatchSize = 27;
YPred = classify(net,XTest, ...
'MiniBatchSize',miniBatchSize, ...
'SequenceLength','longest');(10)计算预测值的分类准确度。
acc = sum(YPred == YTest)./numel(YTest)