何恺明的ResNet论文,被引量刚刚突破10万大关
「深度神经网络非常难以训练,我们提出的残差网络框架使得神经网络的训练变得容易很多。」文章摘要的开头如今已被无数研究者们细细读过。
这是一篇计算机视觉领域的经典论文。李沐曾经说过,假设你在使用卷积神经网络,有一半的可能性就是在使用 ResNet 或它的变种。
前几天,人们发现 ResNet 论文被引用数量悄然突破了 10 万加,距离论文的提交刚过去六年。欢迎关注、收藏、学习
《Deep Residual Learning for Image Recognition》在 2016 年拿下了计算机视觉顶级会议 CVPR 的最佳论文奖,相比 NeurIPS 最高热度论文《Attention is All You Need》,ResNet 的被引数多出了几倍。这一工作的热度如此之高,不仅是因为 ResNet 本身的久经考验,也验证了 AI 领域,特别是计算机视觉如今的火热程度。

论文链接:https://www.cv-foundation.org/openaccess/content_cvpr_2016/papers/He_Deep_Residual_Learning_CVPR_2016_paper.pdf
该论文的四位作者何恺明、张祥雨、任少卿和孙剑如今在人工智能领域里都是响当当的名字,当时他们都是微软亚研的一员。微软亚研是业内为数不多的,能够获得科技巨头持续高投入的纯粹学术机构。
说道论文本身,残差网络是为了解决深度神经网络(DNN)隐藏层过多时的网络退化问题而提出。退化(degradation)问题是指:当网络隐藏层变多时,网络的准确度达到饱和然后急剧退化,而且这个退化不是由于过拟合引起的。
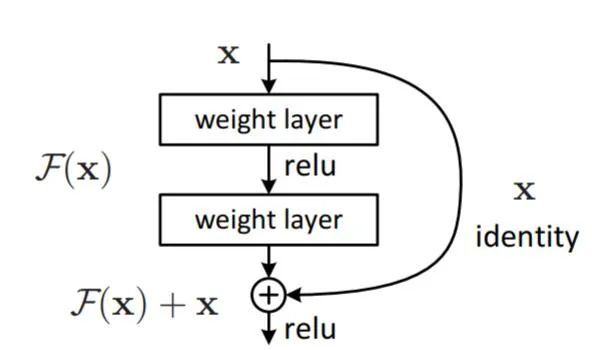
假设一个网络 A,训练误差为 x。在 A 的顶部添加几个层构建网络 B,这些层的参数对于 A 的输出没有影响,我们称这些层为 C。这意味着新网络 B 的训练误差也是 x。网络 B 的训练误差不应高于 A,如果出现 B 的训练误差高于 A 的情况,则使用添加的层 C 学习恒等映射(对输入没有影响)并不是一个平凡问题。
为了解决这个问题,上图中的模块在输入和输出之间添加了一个直连路径,以直接执行映射。这时,C 只需要学习已有的输入特征就可以了。由于 C 只学习残差,该模块叫作残差模块。
此外,和当年几乎同时推出的 GoogLeNet 类似,它也在分类层之后连接了一个全局平均池化层。通过这些变化,ResNet 可以学习 152 个层的深层网络。它可以获得比 VGGNet 和 GoogLeNet 更高的准确率,同时计算效率比 VGGNet 更高。ResNet-152 可以取得 95.51% 的 top-5 准确率。
ResNet 网络的架构和 VGGNet 类似,主要包括 3x3 的卷积核。因此可以在 VGGNet 的基础上在层之间添加捷径连接以构建一个残差网络。下图展示了从 VGG-19 的部分早期层合成残差网络的过程。
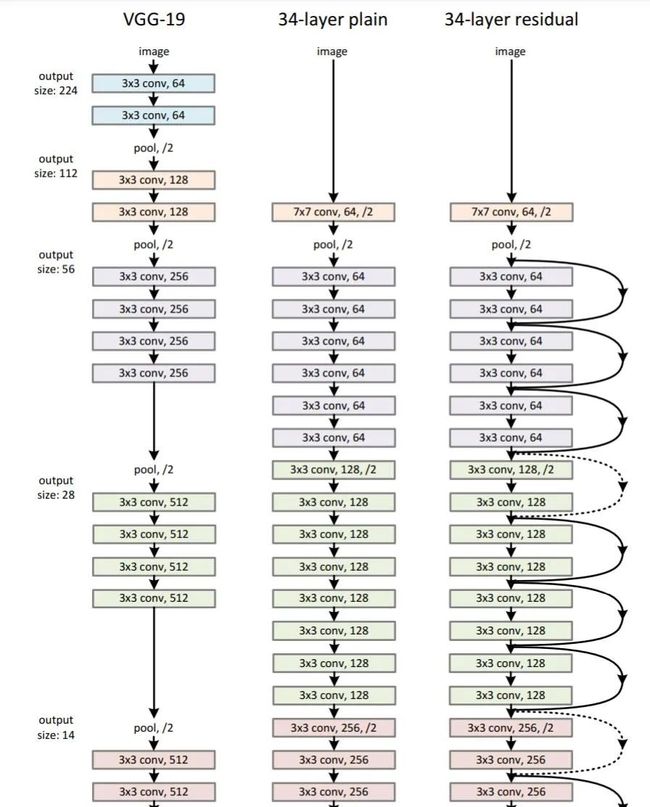
ResNet 的部分结构。很多人说,何恺明的论文非常易懂,光看插图就能读懂思想。
ResNet 因其强大的表征能力,除图像分类以外,包括目标检测和人脸识别在内的许多计算机视觉应用都得到了性能提升。自 2015 年 问世以后,领域内许多研究者都试图对该模型做出一些改进,以衍生出一些更适合特定任务的变体。这也是 ResNet 超高引用量的重要原因之一。
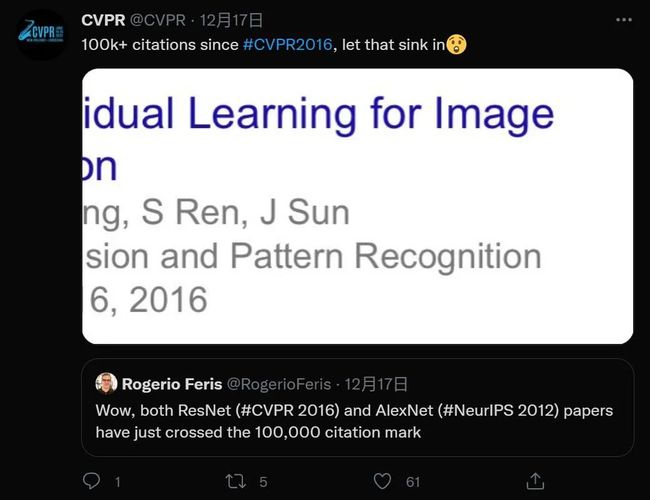
在 ResNet 引用突破十万大关时,另一篇经典论文,2012 年的 AlexNet 被引量也突破了十万。
AlexNet 是 2012 年 ImageNet 竞赛冠军获得者 Alex Krizhevsky 设计的卷积神经网络,最初是与 CUDA 一起使用 GPU 支持运行的。该网络的错误率与前一届冠军相比减小了 10% 以上,比亚军高出 10.8 个百分点。图灵奖获得者 Geoffrey Hinton 也是 AlexNet 的作者之一,多伦多大学 SuperVision 组的 Ilya Sutskever 是第二作者。

论文链接:https://papers.nips.cc/paper/2012/file/c399862d3b9d6b76c8436e924a68c45b-Paper.pdf
Alexnet 网络包含 6000 万个参数和 65000 万个神经元,8 层结构中包含 5 层卷积层和 3 层全连接层。Alexnet 首次在卷积神经网络中成功应用了 ReLU、Dropout 和 LRN 等 Trick。

一篇 CVPR 2016 的文章,和一篇 NeurIPS 2012 的文章双双突破 10 万引用,凸显了 AI 领域近年来的火热。另外值得一提的是,AlexNet 是 2012 年 ImageNet 图像识别竞赛的冠军,而 ResNet 是 2015 年的冠军。
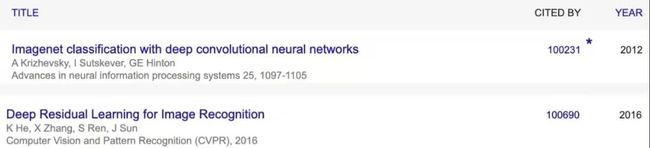
根据 Google Scholar 的统计,ResNet 第一作者何恺明(Kaiming He)一共发表了 69 篇论文,H Index 数据为 59。

何恺明是我们耳熟能详的 AI 领域研究者。2003 年他以标准分 900 分获得广东省高考总分第一,被清华大学物理系基础科学班录取。在清华物理系基础科学班毕业后,他进入香港中文大学多媒体实验室攻读博士学位,师从汤晓鸥。何恺明曾于 2007 年进入微软亚洲研究院视觉计算组实习,实习导师为孙剑。2011 年博士毕业后,他加入微软亚洲研究院工作,任研究员。2016 年,何恺明加入 Facebook 人工智能实验室,任研究科学家至今。
何恺明的研究曾数次得奖,他曾于 2009 年拿到国际计算机视觉顶会 CVPR 的 Best Paper,2016 年再获 Best Paper 奖,2021 年有一篇论文是最佳论文的候选。何恺明还因为 Mask R-CNN 获得过 ICCV 2017 的最佳论文(Marr Prize),同时也参与了当年最佳学生论文的研究。
他最近一次被人们关注的研究是 11 月份的《Masked Autoencoders Are Scalable Vision Learners》,提出了一种泛化性能良好的计算机视觉识别模型,有望为 CV 的大模型带来新方向。