TorchScript 解读(三):jit 中的 subgraph rewriter
目录
子图重写
词法分析
子图构建
子图匹配
子图替换
试一试
小伙伴们好呀,TorchScript 解读系列教程又来啦~在解读(一),我们带领大家初步了解了TorchScript;在解读(二)中,我们介绍 TorchScript 通过 trace 来记录数据流的生成方式,同时分享使用该机制实现的 ONNX 导出过程。接下来,就让我们进入今天的正题吧~
现代的深度学习推理框架通常遵循编译器的范式,将模型的中间表示(IR)会分为两部分:包括与硬件、环境等无关的前端(frontend)以及针对特定环境的后端(backend),比如 TVM 的 Relay 和 tir 就是一个典型的例子。在 PyTorch 的 jit 中源码中,也包含前端与后端的部分(不过后端部分的更新似乎不是很频繁)。frontend 目录下有对 Graph IR 的定义,function_schema 的解析工具,以及将 torchscript 转换成 SSA(static single assignment)形式的转换器等等。
同样根据编译器的习惯,对 IR 的变换通常被组织成 pass。所谓 pass 就是指对 IR 的一次遍历,通过这次遍历完成某种对 IR 的变换。比如上一讲中提到的ToONNX就会将 torchscript Graph 变换成 ONNX Graph。
PyTorch 本身定义了非常多的 pass,用来解决各种问题。这当中,有一个范式非常常见,就是子图重写,下面将会重点介绍这个机制。
子图重写
子图替换如其名字所示,根据特定的子图模式 P,对计算图 G 进行匹配,将找到的子图实例替换为另一种模式 R 的实例。如果对上的介绍摸不到头脑,那么可以看看一个实际的例子:
void UnpackAddMM(std::shared_ptr& graph) {
// TensorRT implicitly adds a flatten layer in front of FC layers if necessary
// 用于匹配的模式
std::string addmm_pattern = R"IR(
graph(%b, %x, %w, %beta, %alpha):
%out: Tensor = aten::addmm(%b, %x, %w, %beta, %alpha)
return (%out))IR";
// 用于替换的模式
std::string mm_add_pattern = R"IR(
graph(%b, %x, %w, %beta, %alpha):
%mm: Tensor = aten::matmul(%x, %w)
%bias: Tensor = aten::mul(%b, %beta)
%out: Tensor = aten::add(%bias, %mm, %alpha)
return (%out))IR";
// 创建子图重写器并注册匹配模式和替换模式
torch::jit::SubgraphRewriter unpack_addmm;
unpack_addmm.RegisterRewritePattern(addmm_pattern, mm_add_pattern);
// 遍历graph,完成重写
unpack_addmm.runOnGraph(graph);
LOG_GRAPH("Post unpack addmm: " << *graph);
}
上图是项目 Torch-TensorRT 中的代码片段,这是一个用于支持 torchscript 到 TensorRT 转换的项目。上面的代码用于将addmm运算展开成数个算子,方便后续映射 TensorRT 算子。
重写器完成了数项工作,包括:
- 读取并解析匹配图与替换图的 pattern 定义,生成匹配图 P 和替换图 R 的图结构
- 根据生成的匹配图 P,对计算图 G 进行匹配
- 将匹配到的计算图 G 进行替换
这个功能在 PyTorch 中 被大量使用,下面将会展开介绍上述步骤。
词法分析
我们的首要任务自然是从给定的 pattern 字符串中创建匹配图 P 与替换图 R。从字符串创建图的过程与编译器生成中间代码的方式很相似,我们首先需要一个工具:词法分析器。
词法分析器的作用是通过“字符序列”生成 token。token 是一个二元组,形如(记录了这个字符序列类型以及字符串本身。PyTorch 在 lexer.h 中提供了一个词法分析器Lexer,其中能生成的 token 大致可以分成四类:
- 数字类 token,通常代表一个数字常量,比如
(TK_NUMBER,3.14159) - 字符串类 token,通常代表一个字符串常量,由双引号或三个双引号组成,比如
(TK_STRINGLITERAL,"OpenMMLab is so cool!!!") - 标识符类 token,由数字、字母、下划线组成,第一位不能是数字,并且不是预定义的关键字。这类 token 可能是是变量名、函数名、类型名等,比如
(TK_IDENT,x),(TK_IDENT,matmul) - 预定义的关键字 token,比如控制流里的
iffor,运算符+<=等都是这一类,比如(TK_IF_EXPR, if),(TK_RETURN,return),(+,+)等。
为了方便进行关键字类型 token 的检索,Lexer 中会维护一个查找树,以<,<=,<<等符号为例:
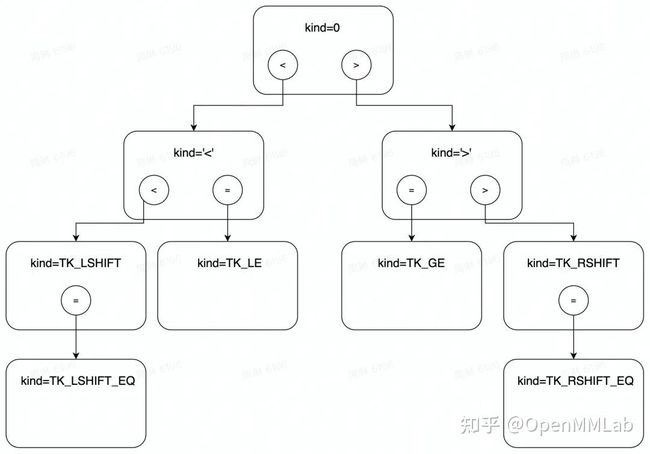
当拿到一个非数字或字符串常量的字符序列时,会从树根起沿着路径前进,比如>=的话,首先是访问根节点,读到>号后向右侧节前前进,再读到=号时向左侧前进,得到 token 类型 为TK_GE。
为了方便后续构建子图的分析过程,Lexer 提供了数个函数帮助生成 token 以及做必要的检查:
// 读取字符串中一个token,然后将准备下一个token,作用相当于一个迭代器
Token next();
// 与next类似,不过会检查当前返回的token是不是制定的类型,不满足则抛出异常
Token expect(int kind);
// 查看next即将返回的那个token
Token& cur();
下面是一个例子,比如说我们希望解析形如%TK_RETURN TK_IDENT(% TK_IDENT)这样的句式,可以:
// 待查询的字符串为 return abs(%x)
lexer.expect(TK_RETURN); // 检查并返回token(TK_RETURN, "return")
lexer.next(); // 返回token(TK_IDENT, "abs")
lexer.expect(int('(')); // 检查并返回token(int('('), '(')
lexer.next(); // 返回token(TK_IDENT, "x")
lexer.expect(int(')')); // 检查并返回token(int(')'), ')')
这些查询到的 token 以及检查工具给子图构建打下了基础。
子图构建
有了词法分析器 Lexer 作为工具,就可以开始解析 pattern 字符串生成Graph了。PyTorch 实现了一个递归下降分析器 irparser 来完成这个过程,下面会以一个简单的例子来介绍分析过程。
graph(%b, %x, %w, %beta, %alpha):
%mm: Tensor = aten::matmul(%x, %w)
%bias: Tensor = aten::mul(%b, %beta)
%out: Tensor = aten::add(%bias, %mm, %alpha)
return (%out)
# 对应的token序列
TK_IDENT(%TK_IDENT, %TK_IDENT, %TK_IDENT, %TK_IDENT, %TK_IDENT):
%TK_IDENT: TK_IDENT = TK_IDENT::TK_IDENT(%TK_IDENT, %TK_IDENT)
%TK_IDENT: TK_IDENT = TK_IDENT::TK_IDENT(%TK_IDENT, %TK_IDENT)
%TK_IDENT: TK_IDENT = TK_IDENT::TK_IDENT(%TK_IDENT, %TK_IDENT, %TK_IDENT)
TK_RETURN (%TK_IDENT) 分析器的入口是parse()函数。创建了初始的空的Graph后,会按次序调用下面的三个 parse 过程:
1)parseGraphInputs:负责解析 Graph 的输入(1,8)
2)parseOperatorsList:负责解析 Graph 中的各个 Ops(2-4,9-11)
3)parseReturnOperator:负责解析 Graph 的输出(5,12)
三个 parse 处理的就是上面内容中与代码块中的行数一致的部分。用Node和Value填充Graph,直到完成建图。另外,还会创建一个类型为std::unordered_map的vmap对象,把Graph中的Value和它对应 pattern 中的名字映射起来,方便后续的检索与替换。
parseGraphInputs
这个解析函数使用词法分析器解析(%TK_IDENT, %TK_IDENT, ....)这样格式的 token 序列。对于每个读到的TK_IDENT类型的 token,创建Value对象,插入Graph中作为图的输入,然后填充 vmap。
parseOperatorsList
这一步所有形如 %TK_IDENT: TK_IDENT = TK_IDENT::TK_IDENT(%TNIDENT, ...)的 token 序列,调用parseOperator 函数来生成对应的 Node 以及 Value。
parseOperator 的过程如下所示:
%mm: Tensor = aten::matmul(%x, %w)
# 对应的token序列(保留空格方便阅读)
%TK_IDENT: TK_IDENT = TK_IDENT::TK_IDENT(%TK_IDENT, %TK_IDENT) - parseOperatorOutputs:负责解析 operator 的输出,注意冒号后的内容是输出的 type,可以省略
- parseOperatorName:负责解析 domain 以及运算类型
- parseOperatorInputs:负责解析 operator 输入
对应代码块中的函数负责解析对应的部分。根据 2 和 3,我们可以创建出对应这个 operator 的Node,以及在vmap中查找这个Node的输入Value。而后我们会根据 1 把Node的输出Value填充进vmap中。
parseReturnOperator
完成 operator 的解析并且确认下一个 token 为TK_RETURN后,就可以开始返回值的解析。返回值的解析方法与 GraphInputs 很像,解析到输出的 name 后,就可以查找vmap,得到对应的Value,注册成 Graph 的输出。
至此,通过这一系列 parse 函数,例子中的 token 序列就可以被转换成对应的 Graph。这里由于篇幅原因进行了一定的简化,实际还有可能存在Node中包含Block的情况,感兴趣的可以阅读源码了解更多细节。
子图匹配
有了上面的 parser,就可以创建检索用的匹配图 P,查找计算图 G 中匹配的子图实例。匹配的入口为findPatternMatches,大致过程如下。
- 初始化
Match队列为空队列 - 对于 G 中每个节点:
-
- 选择一个尚未被选为
anchor的Node,如果没有则跳到步骤 3 - 将该节点选为
anchor,作为 n1,匹配图中产出返回值的 Node 当作 n2 - 比较 n1 与 n2 的 kind、输入输出数量、属性等是否相同,如果不匹配则回到 a
- 将这次匹配中 G 与 P 中对应的 Node 记录在
Match中写入Match队列,回到 a
- 选择一个尚未被选为
-
- 匹配结束,返回
Match队列
下面再举一个例子来让大家有一个直观的概念

左图与右图分别为计算图 G 与匹配图 P,为了方便描述对节点添加了标记。
- 首先是节点 1 被选为 anchor,与匹配图中节点 c 进行比较,不匹配,跳过,节点 2 也同理跳过。
- 节点 3 为 anchor 时与节点 c 匹配成功,然后是 2 和 b、1 和 a 的比较,全部成功,创建新
Match({a:1, b:2, c:3}),加入 Match 队列。 - 4 和 5 由于 anchor 匹配失败会被跳过,6 的 anchor 可以匹配成功,但是在进行 1 和 a 的 weight 匹配时失败(注意,weight 通常是一个 constant Node)因此也会被跳过。
- 7~11由于 anchor 匹配失败都会被跳过,12 尽管anchor匹配成功,但是 11 和 b 匹配失败,因此跳过。
- 最终,输出 Match 队列
[Match({a:1, b:2, c:3})]。
子图替换
在上面的工具的帮助下,我们就可以定义自己的 pattern 来编辑计算图了。PyTorch 中管理图替换的接口为SubgraphRewriter类,该类提供了注册 pattern 以及替换子图的方法,下面将一一介绍这些方法:
RegisterRewritePattern
这个方法可以帮助我们注册匹配图 P 与替换图 R 的 pattern、以及一个value_name_pairs。value_name_pairs对象是一个pair的数组,用来将替换图 R 中的 Node 映射到匹配图 P中。后续介绍替换过程时会展开。
注册过程仅仅是将他们保存在一个名为RewritePatternDescr的结构体中,保存下来方便后续使用。注册过程可以重复执行,注册多组 pattern,之后会一起进行匹配。
注意:注册之间存在先后顺序,先替换的子图可能会影响后续其他的替换。
rewriteSinglePatternOnGraph
实际用于替换的接口方法为runOnModule或runOnGraph,分别对 Module 或 Graph 进行子图替换,他们实际会按照注册时的顺序,挨个使用RewritePatternDescr中的 pattern 调用rewriteSinglePatternOnGraph进行替换,因此这里重点介绍这个方法。
这个函数接收 3 个参数,计算图 graph,匹配与替换用 pattern,以及一个用于过滤匹配结果的 filter。具体步骤:
- 解析 pattern,生成匹配图 P 与替换图 R,以及他们的 vmap 对象(名字与
Value的映射) - 如果注册时
value_name_pairs非空,则生成pattern_node_map对象 - 对图进行匹配, 进行必要的检查,记录哪些 Value 需要被重写,哪些 Node 需要被删除等等
- 根据 3 中记录的信息,进行重写以及删除
-解析pattern
解析 pattern 以及生成 vmap 在上面子图构建章节已经介绍过,如果记不起来的话可以复习一下。
-匹配与检查
匹配的过程就和之前子图匹配章节一样。在得到匹配结果后,需要对匹配结果进行检查,以确定匹配是否满足需求,具体检查的内容包括:
- 是否能够满足所有 MatchFilter
- 该 Match 结果是否未被先前的 Match 所使用
- 查找替换图的插入点以及替换图在计算图中的输入节点,并确认插入点是否合法
在上述的检查全部通过,并且正确设置 Node 的属性后,就可以用之前找到的插入点,将替换图 R 插入计算图 G。注意插入后 R 还处于“悬空”状态,R 的输出尚未与 G 连接。因此还要记录 R 的输出节点应该连接的位置values_to_rewrite,以及需要删除的节点nodes_to_delete_。
-重写及删除
到这里为止 G 处于匹配图 P 与替换图 R 共存的状态,为了完成替换,需要进行一些清理工作:
- 将
values_to_rewrite中记录的 R 的输出连接到 G 中 - 断开
nodes_to_delete_中节点与 G 的输入连接 - 删除
nodes_to_delete_中的节点
至此,替换正式完成。
试一试
如果到这里还有点云里雾里摸不着头脑的话,可以用下面的小例子做一下实验。首先我们构建一个简单的网络并生成 jit 模型:
import torch
def origin_func(x):
x = x**2
x = x**3
return x
x = torch.rand(1, 2, 3, 4)
jit_model = torch.jit.trace(origin_func, x)
print(jit_model.graph)
# graph(%x.1 : Float(1, 2, 3, 4, strides=[24, 12, 4, 1], requires_grad=0, device=cpu)):
# %1 : int = prim::Constant[value=2]() # rewriter_test.py:5:0
# %x : Float(1, 2, 3, 4, strides=[24, 12, 4, 1], requires_grad=0, device=cpu) = aten::pow(%x.1, %1) # rewriter_test.py:5:0
# %3 : int = prim::Constant[value=3]() # rewriter_test.py:6:0
# %4 : Float(1, 2, 3, 4, strides=[24, 12, 4, 1], requires_grad=0, device=cpu) = aten::pow(%x, %3) # rewriter_test.py:6:0
# return (%4)
可以看到,运算节点 2 是aten::pow(%x, %1)。如果因为某些原因我们不希望使用平方计算,就可以尝试用乘法来替换平方。
子图的定义很容易写,以 graph (...)开头,return (...)结尾,中间每一个变量都以百分号%开头,每行一个计算 Node。如果 Node 存在一些固定的属性,则加在 Node 名后的方括号内。
我们定义了两个子图,一个用于匹配,一个用于替换:
# 匹配用的子图定义,注意常量必须为[value=2]属性
pattern = """
graph(%x):
%const_2 = prim::Constant[value=2]()
%out = aten::pow(%x, %const_2)
return (%out)
"""
# 替换用的子图定义
replacement = """
graph(%x):
%out = aten::mul(%x, %x)
return (%out)
"""
然后调用替换接口,PyTorch 提供了 python 侧的封装_jit_pass_custom_pattern_based_rewrite_graph。
# 使用刚才定义的 pattern与replacement来编辑graph
torch._C._jit_pass_custom_pattern_based_rewrite_graph(pattern, replacement,
jit_model.graph)
# 结果可视化,pow(x,2)被正确替换为mul(x,x),pow(x,3)则保留原样不受影响。
print(jit_model.graph)
# graph(%x.1 : Float(1, 2, 3, 4, strides=[24, 12, 4, 1], requires_grad=0, device=cpu)):
# %5 : Tensor = aten::mul(%x.1, %x.1)
# %3 : int = prim::Constant[value=3]() # rewriter_test.py:7:0
# %4 : Float(1, 2, 3, 4, strides=[24, 12, 4, 1], requires_grad=0, device=cpu) = aten::pow(%5, %3) # rewriter_test.py:7:0
# return (%4) 大家也可以尝试自己定义一些 pattern 与 replacement 来优化自己的网络,一起试一试吧。
MMDeploy 已添加对 TorchScript 模型的支持,欢迎大家来 MMDeploy GitHub 主页体验。
github.com/open-mmlab/mmdeploygithub.com/open-mmlab/mmdeploy
如果我们的分享给你带来一定的帮助,欢迎点赞收藏关注,比心~
