深度学习 Day 3——解决深度学习环境配置问题
深度学习 Day 3——解决深度学习环境配置问题
文章目录
- 深度学习 Day 3——解决深度学习环境配置问题
-
- 一、前言
- 二、问题:环境配置
- 三、解决问题
-
- 1、确定显卡驱动
- 2、安装
- 3、测试
- 4、不使用anaconda环境配置
- 5、补充一点
- 四、相关知识点补充
-
- 1、卷神经网络-CNN
-
- CNN的价值
- CNN的基本原理
- CNN的实际应用
- 2、卷积的计算
- 3、最大池化与平均池化的区别
- 五、最后我想说
活动地址:CSDN21天学习挑战赛
- 本文为365天深度学习训练营 中的学习记录博客
- 参考文章地址: 深度学习100例-卷积神经网络(CNN)天气识别 | 第5天
一、前言
在前面一期博客中我们已经跟着博主学习了一整个的过程,这一期博客我主要来说一下我在学习过程中遇到的一些疑惑和困难并如何去解决的,但并不是所有的疑惑我都解决完了,因为我也不可能学习的这么快,哈哈哈,其次也会在本期博客中添加一些深度学习相关的知识点介绍,都是我上网查阅总结的。
先说一点,问题的解决方法多种多样,在这里我只提供我的解决方法,仅供参考,如果你们按照我的方法不成功的话,那你们就需要自己上网查阅找到适合自己的解决办法了。
创作不易,谢谢支持!
好啦,废话不多说,我们开始今天的学习之旅!!!
二、问题:环境配置
如果你出现了这样的红色提示信息:
I tensorflow/core/platform/cpu_feature_guard.cc:193] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX AVX2
这个信息其实大家不必担心,Tensorflow 只是告诉我们,我们安装的版本可以使用 AVX 和 AVX2 操作,并且在某些情况下(例如在前向或反向矩阵乘法中)默认设置为这样做,这可以加快速度。这不是错误,它只是告诉我们它可以并且将利用我们的 CPU 来获得额外的速度。
其中出现的oneDNN是深度神经网络库,是用于深度学习应用的基本构建块的开源跨平台性能库。该库针对英特尔架构处理器、英特尔处理器显卡和基于 Xe 架构的显卡进行了优化。
其次,还会出现一个问题,如果你们使用的是PyCharm进行代码运行,那么很有可能在训练模型的时候出现这样的红色信息提示:
2022-08-06 13:43:30.496849: I tensorflow/stream_executor/cuda/cuda_dnn.cc:384] Loaded cuDNN version 8401
出现这样的提示信息,就说明你为 TensorFlow 和 NVIDIA CUDA 安装的版本可能不匹配所导致的,而且可能忘记安装包含gpu模块的tensorflow了。
不能直接使用命令pip install tensorflow-gpu来下载,对于我来说,这样下载之后还是解决不了问题的。
说啦这么多,你们可能现在想知道一个事,那就是如何查看自己的cuda和cudnn版本。
有很多方法可以查看,这里我提供一种利用Python语言的方法查看自己下载的版本:
import torch
print(torch.__version__)
print(torch.version.cuda)
print(torch.backends.cudnn.version())
print(torch.cuda.is_available())
它运行的结果是:
1.12.0+cpu
None
None
False
可以看出有问题,并且我们下载的还是cpu版本的。
解决问题前,我们需要查看自己的电脑支持的cuda版本,然后再去选择对应的版本安装。
首先打开NVIDIA控制面板,然后点击帮助,点击系统信息。

然后点击组件
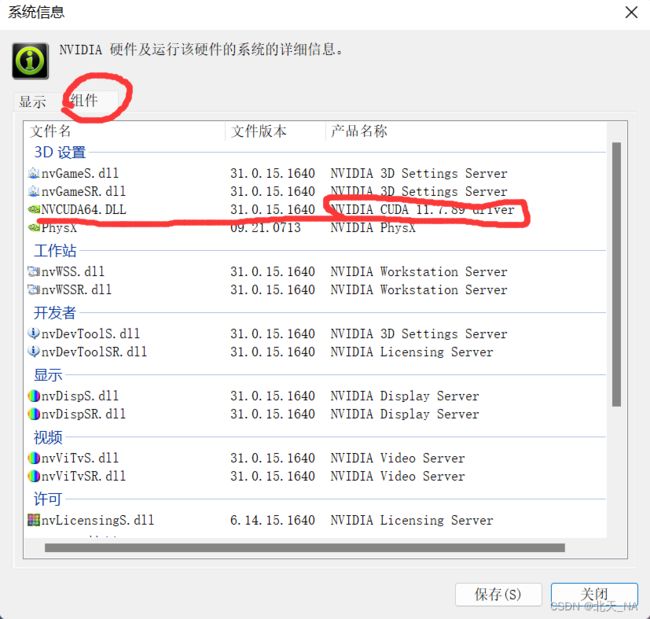
就可以看见自己电脑所支持的cuda最高cuda版本了。
三、解决问题
现在我们开始着手解决这个问题。
1、确定显卡驱动
打开cmd然后输入命令:nvidia-smi
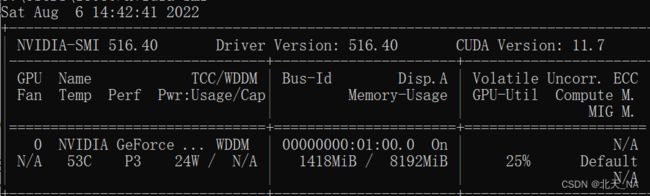
可以查看cuda的接口的最高版本,可以确定和之前的查看结果一样。
在这里顺便说一下,我们要到torch官网下载python版本的cuda和cudnn,如果去英伟达官网下载的话,是下载的C++版本,我们用不到,而且还会多占显存。
2、安装
我一开始并没有使用anaconda环境导致出现了很多问题,这也是我不太熟练的原因,其中不用anaconda也可以使用的,待会我再说。
安装anaconda我就不说了,大家可以自行上网去查一下安装教程很快的。
安装前需要注意的是我们需要关闭代理服务,如果开启会导致安装失败的。
安装好anaconda之后,这里建议利用anaconda新建一个Python环境,并且使用Python3.8版本最好,因为是最稳定的。
现在打开anaconda prompt然后输入如下命令:
conda create -n torch python=3.8.5
就建好了一个新的Python环境了,但是这样的Python环境是空的没有其他的包,我们还需要手动的去下载安装:
conda config --remove-key channels
conda config --add channels https://mirrors.ustc.edu.cn/anaconda/pkgs/main/
conda config --add channels https://mirrors.ustc.edu.cn/anaconda/pkgs/free/
conda config --add channels https://mirrors.bfsu.edu.cn/anaconda/cloud/pytorch/
conda config --set show_channel_urls yes
pip config set global.index-url https://mirrors.ustc.edu.cn/pypi/web/simple
如果下载的太慢可以换一下其他的安装源。
安装好之后就可以激活环境了:
conda activate torch
激活之后就可以去pytorch官网下载对应的版本了
官网地址:https://pytorch.org/get-started/previous-versions/

可以看见这里的cuda版本可选项很少,但是没关系,我们选择和自己电脑支持的版本接近就行,但是这里默认下载的是cpu版本,这会导致后面pytorch无法识别cuda,所以我们需要手动的去选择下载cup还是gpu。
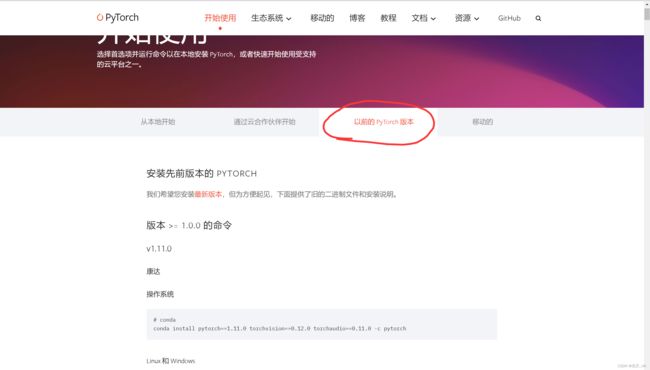
点击以前版本的pytorch版本,然后找到符合自己版本的而且是gpu的,然后复制命令到anaconda环境去下载即可:
pip install torch==1.11.0+cu113 torchvision==0.12.0+cu113 torchaudio==0.11.0 --extra-index-url https://download.pytorch.org/whl/cu113
3、测试
下载时间一般很长,等待一段时间之后,在Pycharm中打开设置,然后将项目的Python解释器换成我们刚刚配置的:
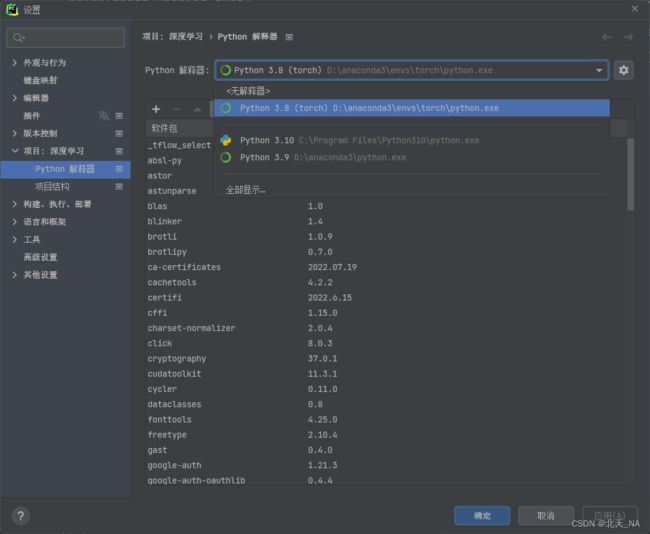
点击确定之后,再次刚刚测试的代码:
import torch
print(torch.__version__)
print(torch.version.cuda)
print(torch.backends.cudnn.version())
print(torch.cuda.is_available())
现在运行的结果是:
1.11.0
11.3
8200
True
现在我们就算是配置成功了,就可以愉快的跑我们的深度学习的项目了。
4、不使用anaconda环境配置
直接在Pycharm中新建项目,然后再最下面找到终端并打开它
![]()
之后再直接把上面的下载pytorch命令直接复制到这个终端里面,回车等待它的下载。
下载完之后我们再次使用上面测试的代码进行测试,你就会发现结果是一样的。
anaconda归根结底也是环境的一种,如果你的电脑上没有下载的话,也不用去花时间去重新配置它,所以安装pytorch并非一定要使用anaconda。
5、补充一点
当你下载哈皮cuda之后,最后测试的代码中:print(torch.cuda.is_available())还是显示False的话,原因有两个:
- cuda版本不匹配
- pytorch安装成了cup版本
问题大概就已经解决了,如果还有什么问题的话欢迎你们来问我!
四、相关知识点补充
1、卷神经网络-CNN
CNN的价值
卷积神经网络 – CNN 最擅长的就是图片的处理。它受到人类视觉神经系统的启发,目前 CNN 已经得到了广泛的应用,比如:人脸识别、自动驾驶、美图秀秀、安防等很多领域。
在CNN出现之前,图像对于人工智能来说是一个难题,因为一方面图像处理的数据量太大,导致成功很高,效率很低,另一方面,图像在数字化的过程中很难保留原有的特征,导致图像处理的准确率不高,CNN的出现很好的解决了这两大难题。
CNN的基本原理
- 卷积层 – 主要作用是保留图片的特征
- 池化层 – 主要作用是把数据降维,可以有效的避免过拟合
- 全连接层 – 根据不同任务输出我们想要的结果
简单的来说:卷积层负责提取图像中的局部特征;池化层用来大幅降低参数量级(降维);全连接层类似传统神经网络的部分,用来输出想要的结果。
CNN的实际应用
- 图片分类、检索
- 目标定位检测
- 目标分割
- 人脸识别
- 骨骼识别
我大致的总结一下有关CNN的相关知识,因为目前我的水平想要理解的很透彻很难,相关的知识点也需要你们的自行去查阅。
在这里我推荐几篇博客供你们去学习:
- https://easyai.tech/ai-definition/cnn/
- https://blog.csdn.net/v_JULY_v/article/details/51812459?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522165967468916780357279307%2522%252C%2522scm%2522%253A%252220140713.130102334…%2522%257D&request_id=165967468916780357279307&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2alltop_positive~default-2-51812459-null-null.142v39control,185v2control&utm_term=%E5%8D%B7%E7%A7%AF%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C&spm=1018.2226.3001.4187
- https://mtyjkh.blog.csdn.net/article/details/123730722?spm=1001.2014.3001.5502
2、卷积的计算
卷积(又名褶积)和反卷积(又名反褶积)是一种积分变换的数学方法,在许多方面得到了广泛应用,卷积是分析数学中一种重要的运算。
卷积的计算公式:
- 输入图片矩阵I大小:w×w
- 卷积核K:k×k
- 步长S:s
- 填充大小:p
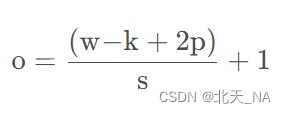
输出的图片大小为:o×o
具体的计算方法和举例可以去看一下k同学啊的博客或者可以自行上网去查阅一下,我在这里没有能说的实力,因为我还没有看懂,实在是太难了对于我这个小白来说。
他的对应博客地址:https://blog.csdn.net/qq_38251616/article/details/114278995
3、最大池化与平均池化的区别
最大池化:是取当前池化视野中所有元素的最大值,输出到下一层特征图中。
平均池化:是取当前池化视野中所有元素的平均值,输出到下一层特征图中。
它们的区别在于需要记录池化操作时到底哪个像素的值对大,因为这个变量是记录最大值所在的位置,在反向传播中需要用到,而在反向传播中国需要把梯度值传到对应最大值的位置。
五、最后我想说
深度学习,一个字难,在本科阶段实在是太难, 目前的目的就是接触并了解它,等我以后读研究生之后,再去深入的去了解它,目前来说读懂它还是太费精力,有苦不敢言哈哈哈哈。
这篇博客写完也就代表第一周的打卡任务成功了,后面还有两个周,再接再厉,后续我也会持续的更新跟着博主学习的过程以及在学习过程中遇见的困惑和困难,大家一起学习,一起共勉,一起营造良好的学习环境,这样的话学习起来就不会那么的累啦。
最后,还是那句话,谢谢能认真看的读者们,希望能得到你们的点赞收藏转发三连支持,非常感谢,你们的鼓励将是我创作的最大动力!!!
不见不散,各位。
