GRAPHSPEECH: SYNTAX-AWARE GRAPH ATTENTION NETWORK FOR NEURAL SPEECH SYNTHESIS论文阅读

摘要
\quad 基于Attention的端到端语音合成在很多方面已经超过传统的统计方法。 其中,基于Transformer的TTS利用自注意力机制很好地对语音帧序列进行建模,但是并没有从句法的角度将输入的文本和输出的音频关联起来。因此提出了一种新的基于图神经网络结构的TTS模型(GraphSpeech)。GraphSpeech显式地对输入句子词汇的句法关系进行编码,然后将这些信息整合到模型中,获取句法驱动的character embedding 给TTS的attention。实验表明GraphSpeech 在韵律等方面比 Transformer TTS 都更好。
关键词
TTS, 图神经网络, 语法
简介
在Graph-to-sequence 学习中,我们可以在图神经网络的架构下构建自注意力网络, token序列可以当成未标注的全连接图(每个token是一个节点),自注意力机制看成是一个特殊的信息传递方案。因此我们提出了一个新的TTS模型,称为GraphSpeech,它采用 两个编码模块: Relation Encoder 和 Graph encoder。Relation Encoder从输入的文本中提取句法树, 然后将句法树转为图结构,编码任意两个token在图中的关系。Graph Encoder 提出 一种基于语法感知的图注意力机制(syntax-aware graph attention mechanism),不仅能够注意到tokens, 同时注意到他们之间的关系,从而受益于句子结构知识。
这篇文章的主要贡献
- 提出了一个新的TTS结构
- 将语法树扩展到语法图, 并对 字符级的关系进行编码
- 提出了一个基于语法感知的图注意力机制, 能够将语言知识融入到注意力的计算。
- GraphSpeech 能够在韵律和频谱方面超过Transformer TTS
- 这是在Transformer-TTS中首次实现了基于图神经网络视角的句法信息注意机制
GraphSpeech
在NLP中图结构扮演着一个重要的角色, 它通常作为语法,语义和知识的中心表示形式。我们将相关的图建模方法引入到TTS的结构中,如图一所示:

在GraphSpeech中,输入到encoder模块的信息包括文本和语法知识。 语言中的韵律和句子中的句法结构是紧密联系的,在GraphSpeech中,将以句法树形式的句法信息来扩充语音合成输入,以期改善输入文本的语言表示。
Relation Encoder
Relation encoder的作用是 将输入文本的语法树转成语法图, 能够更好地表示输入token之间的全局关系。句法依存树是分析词语之间语法依赖性的一个传统方法,在树的结构中,句子中只有那些直接联系的词语之间才有连接,为了能够挖掘句子中任意两个词之间的句法关系,我们希望能够将语法树的拓扑结构扩展到完全连接的关系。(如图二)

我们的想法是通过添加反向连接将单向连接改为双向连接。此外,我们还为每个单词引入带有特定标签的自循环(self-loop)边。这样,句子中的单词就用节点来表示,它们之间的连接用边来表示。这样一个词就能接收和发送信息到另一个节点,不论他们是否直接相连。
为了建立两个节点之间的关系模型,节点对之间的关系被描述为它们之间的最短关系路径。我们使用了GRU将关系序列转换为分布表示,节点i和节点j之间的最短关系路径 s p i → j = [ s p 1 , s p 2 , . . . s p n = 1 ] = [ e ( i , k 1 ) , e ( k 1 , k 2 ) , . . . , e ( k n , j ) ] sp_{i \rightarrow j} = [sp_1,sp_2,...sp_{n=1}]=[e(i,k_1),e(k_1,k_2),...,e(k_n,j)] spi→j=[sp1,sp2,...spn=1]=[e(i,k1),e(k1,k2),...,e(kn,j)], 这里的 e ( . , . ) e(.,.) e(.,.)表示边, k 1 : n k_{1:n} k1:n表示中继节点, i,j是起始节点。使用双向的GRU来对路径序列进行编码:
s t → = G R U f ( s t − 1 → , s p t ) s t ← = G R U b ( s t + 1 ← , s p t ) \mathop{s_t}\limits ^{\rightarrow}=GRU_f(\mathop{s_{t-1}}\limits ^{\rightarrow}, sp_t) \\ \mathop{s_t}\limits ^{\leftarrow}=GRU_b(\mathop{s_{t+1}}\limits ^{\leftarrow}, sp_t) st→=GRUf(st−1→,spt)st←=GRUb(st+1←,spt)
最后的关系编码表示两个词之间的语言关系。在TTS中,句子中最基础的单元是character token,这里我们将词级别的关系编码扩展到字符级别,如果两个字符属于同一个词,我们使用self-loop的边 r i i r_{ii} rii来定义他们的关系;如果两个词属于不同的词语,那么我们直接使用 r i j r_{ij} rij来表示。
关系编码为模型提供了一个关于如何收集和分发信息的全局视图,即在何处参与。接下来,我们将讨论所提出的图编码器,它被设计成将句法关系编码融入到一个自我注意机制中来表示字符关系。
Graph Encoder
图形编码器的目的是将输入的字符embedding和relation encoding转换成一系列相应的语法驱动字embedding。我们将两个节点之间的显式关系表示引入到attention计算中,记做为语法感知图注意(syntax-awared graph sttention)。
relation encoding 只编码了两个字符之间的最短路径,为了在计算attention的时候对连接的方向也进行编码,首先将relation encoding中的前向relation encoding r i → j r_{i \rightarrow j} ri→j 和 反向relation encoding r j → i r_{j \rightarrow i} rj→i分离开来: [ r i → j ; r j → i ] = W r r i j [r_{i \rightarrow j};r_{j \rightarrow i}] = W_{r}r_{ij} [ri→j;rj→i]=Wrrij; 之后将语法感知图注意力引用到注意力score的计算中(基于字符表示和双向 关系表示):
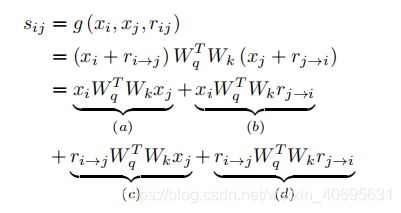
(a)项: content-based attention中的一项
(b)项:forward relation bias
(c)项: backward relation bias
(d)项: universal relation bias
实验
语法依存树提取:Stanza【Python的一个工具】
relation encoder: 使用长度为200的GRU
graph encoder: N=6 blocks; 注意力头 heads=4
decoder: N= 6 blocks;自注意力头heads = 4
input text: 编码为256维的 character embedding
实验结果

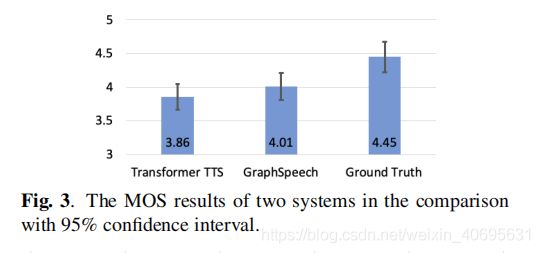
音频链接: https://ttslr.github.io/GraphSpeech/