Micro-Expression Classification based on Landmark Relations with Graph Attention Convolutional Networ
[2021CVPR] Micro-Expression Classification based on Landmark Relations with Graph Attention Convolutional Network
paper链接:https://openaccess.thecvf.com/content/CVPR2021W/AMFG/papers/Kumar_Micro-Expression_Classification_Based_on_Landmark_Relations_With_Graph_Attention_Convolutional_CVPRW_2021_paper.pdf
摘要:
面部微表情是面部肌肉表达个人真实情感的简短、快速、自发的动作。由于微表情的持续时间短、表达方式复杂,无论是人工还是机器都很难对这些微表情进行检测和分类。本文提出了一种新的方法,该方法利用了特征点和给定特征点的光流patch之间的关系。它由一个双流图注意卷积网络组成,该网络使用光流patch提取特征点和局部纹理之间的关系。建立了一个图结构,使用三个帧引出时间信息。一个流用于节点特征位置,另一个流用于光流patch信息。这两个流(节点信息流和光流流)被融合用于分类。结果显示在CASME II和SAMM上,用于三类和五类微表情。对于3类和5类微表情,所提出的方法优于最新方法。
Motivation:
微表情分类的挑战:(i)细微行为(低强度的面部表情),(ii)短暂且快速的变化,(iii)持续时间短。
另一个问题是缺乏足够和平衡的训练数据,使得端到端神经网络模型的训练更有挑战性,这导致了大多数类的更高准确率。
为了克服上述问题,本文提出了一种新的图结构的端到端训练方法,该方法利用三组帧来提取时间信息,并利用特征点位置信息和光流patch信息之间的关系建立了双流图注意卷积神经网络(GACNN)模型。为了解决数据样本不平衡的问题,我们使用来自同一类的其他数据集的视频来增加数据样本的数量。除了上述数据扩增方法,我们还使用EMM技术的各种扩增因子,增加较少数据样本表情类的样本数量,从而平衡数据集。
Contributions:
- 提出了一种端到端特征点辅助的双流图注意卷积网络,该网络将特征点位置和光流信息相结合,对面部微表情进行分类。
- 我们设计了一个图结构来提取时间信息使用三帧结构。我们使用一个双流图注意网络,一个用于节点位置,另一个用于光流patch信息,然后融和他们。我们描述了一种基于光流幅度从视频中自动选择高强度表情帧的方法。
方法:
1、概述
- 利用欧拉运动放大率(EMM)放大信号,提取放大后的输入视频。
- 定义了一种自动选择高强度表情帧的方法,并使用光流幅度阈值去除剩余的低强度帧。
- 使用dlib软件来检测面部上的特征点。基于检测到的特征点,构建我们的图,并计算出选定特征点的光流patch特征信息。
- 最后采用利用了特征点位置信息和光流patch信息的双流图注意CNN对微表情进行分类。
框架如下:
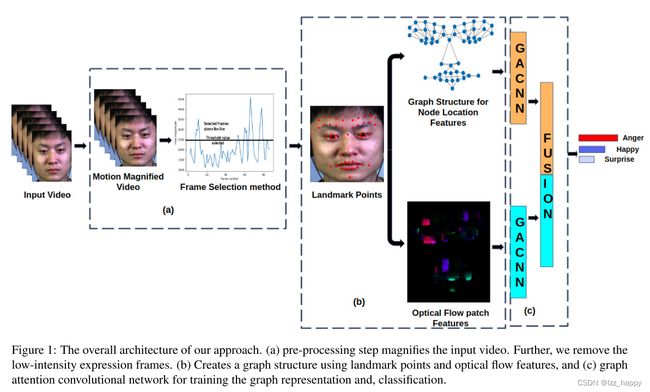
2、EMM
通过整合空间和时间处理对视频中的微小运动进行放大,以关注视频中的细微面部特征。EMM的优点如下:(1)放大视频有助于放大信号,使人脸更容易识别这些微表情。其次,为了平衡数据集,我们可以使用不同的放大因子α,并使用这些样本扩充训练集。选择合适的α值至关重要,由于α值越高,噪声放大,视频中的伪影就越多。因此选择较低的α值来放大视频。α的预设值为2~5。我们进行一个实验来确定最佳α值,实验发现当α为5时及以上时视频明显变形,最终选择α为4作为测试样本。为了在训练阶段平衡数据集,我们使用α=1、2、3、4和5。α值从1~4的EMM如下图:

3、帧选择方法
由于微表情是细微的且短暂的,因此我们只关注具有用于分类任务的高强度表情信息的帧。我们计算视频帧的光流,并得到每帧的光流幅度,光流幅值大小与帧数关系图如下:

接下来,提取前五个视频帧的平均光流幅值来计算阈值。最后,将平均光流幅值的1.25倍作为阈值,用来去除低强度帧。高于阈值的所有帧被选择,丢弃其他帧。我们需要至少3个帧(图从当前帧连接到前一帧和未来帧)来构造图结构以提取时间信息。之所以选择较高和严格的阈值的原因是为了减少用于训练和测试过程的帧的数目,因为图网络收敛较慢。
4、人脸特征点检测与节点特征提取
我们使用dlib软件获得68个特征点。但是,所有的特征点对于面部微表情的分类并不一定都是有用的。因此我们消除了沿面部轮廓区域的特征点,以及鼻子上的几个点和嘴的内部点。最后,68个特征点还剩下37个。如图4所示,我们在前额区域增加10个,面部嘴巴区域增加4个额外参考点。这些特征点是使用视频的开始帧来获得和添加的。这14个特征点用作所有视频帧的参考。这些点的意义在于,我们捕捉到前额区域和脸颊附近区域的细微变化。
我们获得的另一个重要信息是其他特征点是如何相对于这14个参考特征点移动的。现在,我们总共得到了51个人脸上的地标点,如图4所示。

在提取这些特征点之后,根据人脸结构对特征点进行连接。如上图。我们使用节点位置作为图网络第一流的特征向量。
对于图像特征,我们计算了各特征点处10×10patch的光流,如图5。选择10×10patch size的原因是不想错过特征点附近面部肌肉运动的任何变化。另一原因是我们对视频样本进行了运动放大。因此新的放大视频不再是微妙的。将10×10的光流特征矩阵展平处理,得到100×1的光流特征向量。将矩阵展平是为了提取边缘特征和减少计算量。光流特征向量是图网络第二个流的输入。

5、人脸图结构
图结构的基本构建块是节点数据和边数据,其:G=(N,E),其中N=Node,E=Edge。N为人脸特征点数量,在我们这N=n1,n2,…,n51。E是两个节点之间连接得到的边数,E = (12,13,24,…,ij),i和j表示节点。图表结构如图四所示。节点和边会根据面部肌肉运动而变化。每个微表情类别将具有不同的面部肌肉运动模式,节点和边的运动也会根据类的不同而不同。因此,图结构可用于面部微表情的分类。
我们设计了一中利用三个视频帧来提取时间信息的图结构。这里,当前帧连接前一帧和未来帧。整个视频被转换成一个单独的图结构,连接三个帧。
6、双流图注意卷积网络
为了从视频中提取时间特征,我们设计了一个新颖的双流图注意网络来训练图结构,如图6所示。整个视频被转换成单独的图形。我们提取节点特征和光流特征进行分类。
图注意网络(GAT)采用节点特征的自注意。该方法假设相邻节点对中心节点的贡献不相同,也不像图卷积网络(GCN)模型那样是预先确定的。GAT采用注意力机制学习两个相连节点之间的权值。
我们使用GAT和GCN来设计图网络,如图6。我们使用三个GACNN层,在前两层后使用ReLu激活函数,最后一个层后使用全局平均池化操作,最后使用dropout和全连接层。在两流网络的全连接层的末端,将两流网络的结果串接在一起,得到两流网络的图表示。最后,输出经过最后的全连接层和softmax进行分类。我们使用64个隐藏通道,连接操作是关闭的,并且GAT层的头数=1。对于第一个流,节点特征向量的大小等于x和y坐标,对于第二个流,节点向量的长度为100。我们使用Adam优化器,学习率等于0.001。学习速率每100个历元降低一半。

实验:
1、预处理
为了更好地提取面部特征,我们将图像帧对齐并调整大小为256x256。为了解决数据不平衡的问题,我们在训练视频样本数较少的类别时使用了来自另一个数据集的数据(Happy和Surprise),以提高训练精度。此外,我们使用不同的运动放大幅度(1、2、3、4和5)来增加数据样本,以克服训练期间数据集的类别不平衡。在评估过程中使用放大因子4,其他放大的样本用于增加样本数量最少的类别(快乐、惊讶、压抑和蔑视)的样本数量。
2、评估指标
我们使用未加权的F1分数来评估识别性能,并且还使用准确度作为度量。
3、SOTA对比
表3显示了我们方法和sota对CASME II和SAMM数据集三类表情的结果比较。
对于CASME II数据集,与其他方法相比,我们的方法获得的准确度结果高了1.38%,F1-Score低了0.02%。
对于SAMM数据集,与其他方法相比,我们的方法获得的准确度结果高了6.77%,F1-Score提高了10.62%。
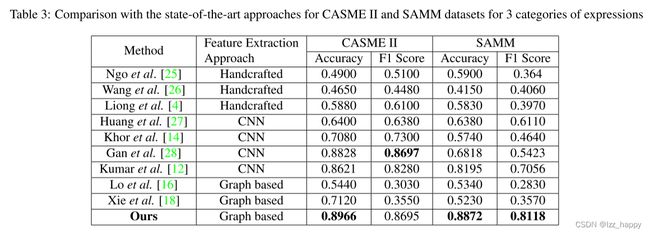
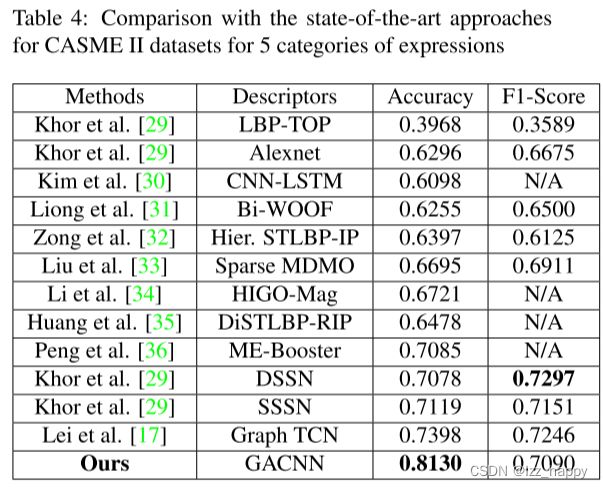
表4显示了我们方法和sota对CASME II数据集五类表情的结果比较。
对于CASME II数据集,与其他方法相比,我们的方法获得的准确度结果高了7.32%,F1-Score低了2.07%。
表5显示了我们方法和sota对SAMM数据集五类表情的结果比较。
对于SAMM数据集,与其他方法相比,我们的方法获得的准确度结果高了13.24%,F1-Score提高了12.94%。

4、消融实验
表6分别显示了CASME II和SAMM数据集的消融研究结果(3类)。我们观察到,当使用图卷积网络(GCN)和仅使用我们提出的视频帧选择过程时,CASME II数据集的F1评分准确度分别提高了4.14%和5.87%,SAMM数据集的F1评分准确度分别提高了2.25%和6.35%。当我们使用帧选择过程和注意网络时,我们的结果在CASME II数据集的F1得分上分别提高了9.66%和15.21%,在SAMM数据集的F1得分上分别提高了3.76%和7.37%。

总结:
在本文中,我们提出了一种双流图注意卷积神经网络,用于节点位置特征和光流特征向量,并借助三组帧来提取时间信息。我们定义了一个帧选择过程来丢弃低强度表情帧。将双流网络的结果进行融合,实现微表情的分类。我们对CASME II和SAMM数据集进行了3类和5类表情的综合评估。在CASME II数据集上,我们提出的方法在3个和5个类别上的准确率分别比现有方法高1.38%和7.32%。在SAMM数据集上,对于3类和5类表情,我们的方法分别将现有方法的准确率提高了6.77%和13.24%。我们的帧选择方法提高了ME分类的整体性能。我们观察到,在不使用注意网络的情况下,帧选择过程有助于提高准确率,对于3类CASME II和SAMM数据集,准确率分别提高了4.14%和2.25%。在未来,我们将致力于自动学习边连接以及边和节点特征之间的关系。