CLIPstyler: Image Style Transfer with a Single Text Condition(2022 CVPR)(单文本风格转换)
1.CLIPstyler: Image Style Transfer with a Single Text Condition(2022 CVPR)(单文本风格转换)
机构:Dept. of Bio and Brain Engineering1, Kim Jaechul Graduate School of AI2, KAIST

2.GitHub地址:https://github.com/cyclomon/CLIPstyler
3.介绍和摘要:
我们提出了一个新的框架,该框架可以 “不带” 样式图像进行样式转换,只使用所需样式的文本描述。使用预训练文本图像嵌入模型CLIP,我们演示了仅在单个文本条件下对内容图像样式的调制。具体来说,我们提出了一种具有多视图增强功能的补丁式文本图像匹配损失,以实现逼真的纹理传输。
摘要:
现有的神经样式转换方法需要参考样式图像来将样式图像的纹理信息转换到内容图像。但是,在许多实际情况下,用户可能没有参考样式图像,但仍然对仅通过想象样式来转移样式感兴趣。为了处理此类应用程序,我们提出了一个新的框架,该框架可以 “不带” 样式图像进行样式传输,但只能使用所需样式的文本描述。使用剪辑的预训练文本图像嵌入模型,我们演示了仅在单个文本条件下对内容图像样式的调制。具体来说,我们提出了一种具有多视图增强功能的补丁式文本图像匹配损失,以实现逼真的纹理传输。广泛的实验结果证实了具有反映语义查询文本的逼真纹理的成功图像样式传输
4.method
我们框架的目的是通过预先训练的文本-图像嵌入模型CLIP 将目标文本tsty的语义样式转移到内容图像Ic。与现有方法的主要区别在于,在我们的模型中,没有样式图像可作为参考。
我们有几个技术问题需要解决:
1)如何从 CLIP 模型中提取语义“纹理”信息并将纹理应用于内容图像.
2)如何对训练进行正则化,以使输出图像不受到质量损害.
我们引入了一个 CNN 编码器-解码器模型 f,它可以捕获内容图像的层次视觉特征,同时在深度特征空间中对图像进行风格化,以获得逼真的纹理表示。因此,我们的风格化图像 Ics 为 f(Ic),我们的最终目标是优化 f 的参数,使其输出具有目标纹理。
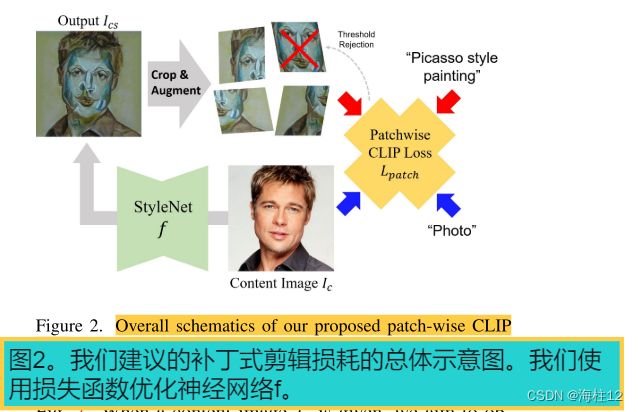
5.Loss function
为了引导内容图像遵循目标文本的语义,最简单的基于 CLIP 的图像处理方法 是最小化全局CLIP损失函数
CLIP loss:

其中 ![]() 是 CLIP 空间余弦距离。该损失函数将整个输出图像转换为遵循文本条件的语义。然而,当使用这种全局 CLIP 损失时,输出质量往往会受到破坏,并且在优化过程中稳定性较低.
是 CLIP 空间余弦距离。该损失函数将整个输出图像转换为遵循文本条件的语义。然而,当使用这种全局 CLIP 损失时,输出质量往往会受到破坏,并且在优化过程中稳定性较低.
为了解决这个问题,StyleGAN-NADA 提出了一种定向 CLIP 损失,它将源和输出的文本图像对之间的 CLIP 空间方向对齐。因此,我们也采用了定向 CLIP 损失。
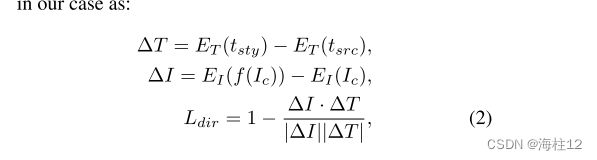
其中![]() 和
和![]() 分别是CLIP的图像和文本编码器;而
分别是CLIP的图像和文本编码器;而![]() 、
、![]() 分别是样式目标和输入内容的语义文本。当我们使用自然图像作为内容时,tsrc 被简单地设置为“照片”。
分别是样式目标和输入内容的语义文本。当我们使用自然图像作为内容时,tsrc 被简单地设置为“照片”。
PatchCLIP loss:
结果还表明,在我们的框架中仅使用Ldir会降低输出的质量,为了解决这个问题,传递空间上不变的信息,我们发现通过最小化片段损失函数可以获得类似的效果,该片段损失函数是从任意位置的Ics中提取的。
我们从Ics中随机裁剪足够数量的补丁。在此阶段,裁剪后的图像的大小是固定的。对于Ics中的所有N个裁剪补丁,在计算CLIP定向损失之前,我们将随机几何增强应用于裁剪补丁.
使用透视增强,引导所有块为相同的语义,从而可以将 CLIP 模型的语义信息重构为更类似于 3D 的结构.
由于补丁采样和增强的随机性,我们的方法经常遭受过度风格化的影响,其中样式网络f在易于使损失得分最小化的特定补丁上进行了优化。为了缓解该问题,我们包括正则化以拒绝优化可以快速降低损失的patch补丁。
在给定阈值 τ 的情况下,我们简单地使相应补丁的计算损失无效

其中,“![]() ” 是来自输出图像的第i个裁剪补丁,增强是随机透视增强,R(·,·) 表示阈值函数。
” 是来自输出图像的第i个裁剪补丁,增强是随机透视增强,R(·,·) 表示阈值函数。
total loss
对于总体损失函数,我们使用四种不同的损失。首先,我们使用标准的定向剪辑丢失Ldir来调制内容图像的整个部分 (例如色调,全局语义)。其次,我们添加了建议的PatchCLIP loss Lpatch以进行局部纹理样式化。除了剪辑丢失函数之外,为了保持输入图像的内容信息,我们还包括内容丢失Lc,计算从预先训练的VGG-19网络中提取的内容和输出图像的特征之间的均方误差,类似于Gatys等人 [7] 的现有工作。最后,为了减轻不规则像素的侧面伪影,我们包括了总变化正则化损失Ltv。因此,我们的总损失函数公式化为

6.Results

7.Comparison with baselines

8.conclusion
在本文中,我们提出了一种新颖的图像风格转移框架,仅使用文本条件来转移语义纹理信息。使用新颖的 patchCLIP 损失和增强方案,我们通过简单地更改文本条件而不需要任何样式图像来获得逼真的样式转换结果。实验结果表明,我们的框架产生了最先进的图像风格迁移。