目标检测中的数据增强
random erasing data augmentation
论文说明
论文为CNN训练提出了一种新的数据增强方法。Random Erasing,在一张图片中随机的选择一个矩形框,在随机的位置上使用随机的值来擦除图片原来的像素。通过该方法能够给图片加入不同程度的遮挡,通过这样的训练数据,可以减少模型过拟合的风险同时对遮挡具有一定的鲁棒性。随机擦除和random cropping,random flipping一样可以作为数据增强的方法,在分类,检测和行人重识别领域能够取得不错的效果。
论文算法


从random Erasing算法中不难看出,主要包括了以下几个随机因素:
- Erasing probability p;决定算法是否对图片进行增强;
- areaRatio;填充区域的面积在整张图片中的占比,控制这个超参数,可以控制主要信息被覆盖;
- aspect ratio;填充区域的高宽比,控制这个因素在一定程度上也可以避免主要信息被覆盖;
- 像素值随机;
在这里,重新梳理一下该方法的不足之处:
- 随机的填充区域容易将目标覆盖;
- 使用随机的像素值,可能会改变数据的均值与方差;特别是模型使用BN时,超参数在模型推理时可能不太合适,从而导致模型在测试集中效果不理想。
- 与其他增强技术混用时,先后顺序比较重要;比如数据归一化应该在random Erasing之后,否则随机填充之后数据分布发生改变。
论文实验
论文提出的数据增强法法简洁实用,做的一些实验很值得我们以后利用,这也是之前一直只是用该方法却没有看该论文的遗憾,其实论文做了很多实验,分析了一些有用的东西。
image classification
作者参数设置为 p=0.5,sl=0.02,sh=0.4,r1=1r2=0.3 分类实验都是在加了random cropping 和flipping基础上做的,
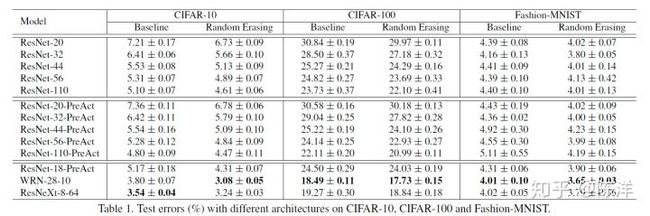
可以看到基本上加上random erasing对实验结果都是有提升的。
比较数据增强方法:

通过实验可以发现效果最好的是random cropping方法,其次是random flipping ,最后才是random erasing。但是三种一起使用确实能得到最好的效果。
Person re-identification

数据增强-Hide-and-Seek
1、技术原理
Hide-and-Seek本质上与RandomErasing,Cutout是一类方法,可以看做是这两者的扩充,核心原理就是把图像划分为若干小块的区域,然后随机删除。Hide-and-Seek的出发点是将一些区域进行填充,迫使模型通过其他区域的特征识别出物体,从而增强特征的表达能力,提高模型的泛化能力。下图较好的体现了这一思想,比如模型容易通过头来识别出这是一只狗,在训练过程中,将狗头等区域遮住,从而迫使模型通过腿或者毛等特征识别出这是一只狗。

2、增强图片展示

hide-and-seek图片增强效果
从图中可以看出,通过hide-and-seek增强图片后,模型通过目标的更多区域去识别目标,这对提升目标的召回率很有帮助,比如狗头不在图片中也能识别出是一只狗。
3、hide-and-seek算法
def hide_patch(img):
# get width and height of the image
s = img.shape
wd = s[0]
ht = s[1]
# possible grid size, 0 means no hiding
grid_sizes=[0,16,32,44,56]#格子的大小,相当于Cutout中正方形的边长
# hiding probability
hide_prob = 0.5#率遮掩当前格子区域的概率
# randomly choose one grid size
grid_size= grid_sizes[random.randint(0,len(grid_sizes)-1)]
# hide the patches
if(grid_size<>0):
for x in range(0,wd,grid_size):
for y in range(0,ht,grid_size):#这两个循环相当于将图片划分成格子
x_end = min(wd, x+grid_size)
y_end = min(ht, y+grid_size)
if(random.random() <= hide_prob):#以hide_prob的概率将区域填充
img[x:x_end,y:y_end,:]=0
return img对于这个算法在实际业务场景中的应用,应该做一下消融实验,看是否能涨点。本人觉得可能出现的问题如下:
- 对于非领域内的图片,有可能误识别为目标;比如识别狗和背景两个类别的任务,如果背景图片中出现一个四条腿的动物(不是狗),是否有可能被误识别为狗,而不是背景图片?
- 填充的区域多了,背景信息是否会取代目标信息。是否有可能遮住目标后,模型通过背景信息来识别物体?比如识别牛,周围一般有草地,而狗出现的场景一般没有草地。那么当一张草原上的风景图出现,是否会被识别为牛?特别是在数据集比较少的时候。
- 大量使用0填充区域,是否会改变数据的分布;需注意与其他增强技术的混用,比如normalize
因此,对于该方法,本人建议还是分析数据集,根据数据集的特点选择合适的超参数。
4、实验效果

从作者的实验来看,hide-and-seek数据增强方法是能够涨点的。在实际的场景中,也需要做一下消融实验。
Mixed Sample Data Augmentation (MSDA)
有很多数据增强的方式,比如传统的对图像进行旋转裁剪等,这里介绍几种新的且在图像任务中比较有效的数据增强方式,例如Cutmix、Mixup以及FMix
1 MSDA介绍
MSDA就是混合图像数据增强,主要分为两大类,一种是通过插值的方式进行,另一种是通过加mask的方式进行。
1.1 interpolation
对于第一种比较有名的是MixUp,它就是通过一定的比例将两张图象进行插值融合,网络的pipline如图1-1所示。

图1-1
Mixup算法的核心思想是按一定的比例随机混合两个训练样本及其标签。这种混合方式不仅能够增加样本的多样性,并且能够使不同类别的决策边界过渡更加平滑,减少了一些难例样本的误识别,模型的鲁棒性得到提升,训练时也比较稳定。
使用MixUp对图像进行增强的示例如图1-2所示。
图1-2
右图是将猫和狗进行一定比例的融合,这时候,标签也会变成软标签。
1.2 mask
另一种MSDA的方式是给图像加掩码,例如Cutmix,如图1-3所示。

图1-3
首先是随机生成box将图片一部分cut out出来,接下来用另一个数据的图像对这部分进行填充,生成新的图像
2、问题分析
2.1 图像增强的原则
在不破坏数据分布的前提下,尽可能的扩大数据空间。这里不破坏数据分布,我的理解就是这里说的一方面是整体的数据类别的分布,另一方面对于单张图片来说,数据增强不能破坏原有的像素之间关联信息的一个分布(就是自己的一个感觉,虽然cutmix直接把图像给扣了,但后面会解释一下)。
2.2 interpolation以及mask方法比对
在论文中通过实验,发现MixUp破坏了原有的数据分布,cutmix没有破坏数据的分布。论文中的解释是这样的:
Our principle finding is that the masking MSDA approach
works because it effectively preserves the data distribution in
a way that interpolative MSDAs do not, particularly in the
perceptual space of a Convolutional Neural Network (CNN).
This derives from the fact that each convolutional neuron at a
particular spatial position generally encodes information from
only one of the inputs at a time. This could also be viewed
as local consistency in the sense that elements that are close
to each other in space typically derive from the same data
point.
大致意思就是说,虽然在Cutmix中将图片扣出来一块,但是对于CNN来说有局部一致性,我理解的是,CNN处理MixUp的时候,因为像素是叠加的,因此对于CNN会破坏pixels的distribution,相反对于cutmix虽然扣掉一部分,但还是保留了原图的distribution。
2.3 Cutmix存在的问题
Cutmix都是用矩形框来cut out,会有一定的限制在里面。
2.4 是不是只要抠图不直接叠加像素都可以保持像素distribution不变
这个问题我觉得自己提的不错,论文中也给出了解释,应该是单一的连续的区域,才有这种效果。
3、FMix
经过上面的问题分析,mask要好于interpolation的方式,但是现在的Cutmix是存在一些问题的,因此FMix其实是对Cutmix的一种改进。
FMix就是通过对图像高低频进行划分,生成binary的两个区域,针对这两个区域进行填充,如图3-1所示。

图3-1
从上图中可以很清晰的看出来,FMix的整个过程
另外,结尾附上FMix工程链接,好用:GitHub - ecs-vlc/FMix: Official implementation of 'FMix: Enhancing Mixed Sample Data Augmentation'

参考文献
[1]Singh, Krishna Kumar, et al. "Hide-and-seek: A data augmentation technique for weakly-supervised localization and beyond."arXiv preprint arXiv:1811.02545(2018).
全新数据增强 | TransMix 超越Mix-up、Cut-mix方法让模型更加鲁棒、精度更高 - 腾讯云开发者社区-腾讯云 (tencent.com)
深入浅出Yolo系列之Yolox核心基础完整讲解 - 知乎 (zhihu.com)