Pytorch 深度学习实践第8讲
七、加载数据集Dataset and DataLoader
课程链接:Pytorch 深度学习实践——加载数据集
1、Batch和Mini-Batch
Mini-Batch SGD是为了均衡BGD和SGD在性能和时间复杂度上的平衡需求。
2、Epoch、Batch-Size、Iterations
Epoch:所有训练样本进行一轮Forward和Backward的周期。
Batch-Size:进行一轮Forward和Backward的训练样本数量。
Iterations:Batch分成了多少份——内层一共迭代了多少次。
3、DataLoader
①Shuffle:随机打乱数据集
②Loader:将数据集进行分组迭代
4、定义数据集
#Prepare dataset
class DiabetesDataset(Dataset): #Dataset是一个抽象类,不能实例化,只能被其他类继承
def __init__(self, filepath): #初始化数据集
xy = np.loadtxt(filepath, delimiter=',', dtype=np.float32) #文件名,分隔符,数据类型
self.x_data = torch.from_numpy(xy[:, :-1])
self.y_data = torch.from_numpy(xy[:, [-1]])
self.len = xy.shape[0]
def __getitem__(self, index):
return self.x_data[index], self.y_data[index]
def __len__(self): #返回数据集的长度
return self.len
dataset = DiabetesDataset('diabetes.csv.gz')
train_loader = DataLoader(dataset=dataset, #数据集对象
batch_size=32, #一共有759行数据,batch-size为32,则一共有24组数据(可以在后面的training cycle输出中看到)
shuffle=True,
num_workers=2) #需要几个多线程并行化读取数据集
5、训练周期
# # windows在处理多线程时接口不匹配,解决方案:wrap the code with an if-clause to protect the code from executing multiple times
if __name__ == '__main__':
for epoch in range(100):
for i, data in enumerate(train_loader, 1):
#1、Prepare data
x, y = data
#2、Forward
y_pred = model(x)
loss = criterion(y_pred, y)
print(epoch, i, loss.item())
#3、Backward
optimizer.zero_grad()
loss.backward()
#4、Update
optimizer.step()
6、作业——Predict Titanic Dataset
#Titanic Dataset training
import torch
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from torch.utils.data import Dataset
from torch.utils.data import DataLoader
#Design Model
class Model(torch.nn.Module):
def __init__(self):
super(Model, self).__init__()
self.linear1 = torch.nn.Linear(7, 4)
self.linear2 = torch.nn.Linear(4, 1)
self.activate = torch.nn.ReLU()
self.sigmoid = torch.nn.Sigmoid()
def forward(self, x):
x = self.activate(self.linear1(x))
x = self.sigmoid(self.linear2(x))
return x
model = Model()
train_data = pd.read_csv('train.csv')
# 可以发现cabin有大量缺失,age有20%的缺失率
# embarked只有两条缺失
#考虑删除id,cabin,name,ticket
del train_data['PassengerId']
del train_data['Cabin']
del train_data['Name']
del train_data['Ticket']
#由于age缺失很少,我们使用年龄的平均值进行填充
train_data['Age'] = train_data['Age'].fillna(train_data['Age'].median())
## 统计出Embarked列各个元素出现次数
ans = train_data['Embarked'].value_counts()
# 返回最大值索引
fillstr = ans.idxmax()
train_data['Embarked'] = train_data['Embarked'].fillna(fillstr)
# 可以发现embarked无缺失了
#修改Sex和Embarked
train_data.replace(["female", "male"], [0, 1], inplace=True)
train_data.replace(["Q", "C", "S"], [0, 1, 2], inplace=True)
# train_data.info()
#改变age和fare的数据类型
train_data = train_data.astype(np.float32)
train_data.info()
print(train_data.describe())
#Prepare Dataset
train_data = np.array(train_data)
x_data = torch.from_numpy(train_data[:, 1:8])
y_data = torch.from_numpy(train_data[:, [0]])
#BCELoss类参数:size_average=True/False是否求均值、reduction=True/False是否降维
criterion = torch.nn.BCELoss(reduction='mean')
#优化器
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
epoch_list = []
loss_list = []
#---------------------------------traing cycle----------------------------------#
for epoch in range(25001):
#Forward
y_pred = model(x_data)
ans = y_pred.detach().numpy()
loss = criterion(y_pred, y_data)
#Backward
optimizer.zero_grad()
loss.backward()
#Update
optimizer.step()
if(epoch % 5000 == 0):
print('Epoch = ' + str(epoch) + '\t' + 'Loss = ' + str(format(loss.item(), '.4f')))
epoch_list.append(epoch)
loss_list.append(loss.item())
#绘制结果
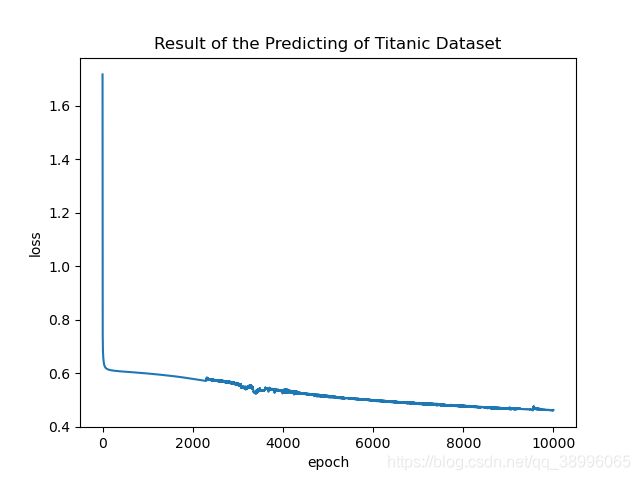
plt.plot(epoch_list, loss_list)
plt.xlabel('epoch')
plt.ylabel('loss')
plt.title('Result of the Predicting of Titanic Dataset')
plt.show()
ans[ans >= 0.5] = 1
ans[ans < 0.5] = 0
# 查看准确率
train_size = x_data.shape[0]
print(train_size)
cnt = 0
for i in range(train_size):
cnt += (ans[i].item() == y_data[i])
accuracy = cnt / train_size
print("准确率为: ", accuracy)
test_data = pd.read_csv('test.csv')
# 可以发现cabin有大量缺失,age有20%的缺失率
# embarked只有两条缺失
#----------------------------predict the test data-------------------------------#
#考虑删除cabin,name,ticket
del test_data['Cabin']
del test_data['Name']
del test_data['Ticket']
#由于age缺失很少,我们使用年龄的中位数值进行填充
test_data['Age'] = test_data['Age'].fillna(test_data['Age'].median())
## 统计出Embarked列各个元素出现次数
ans = test_data['Embarked'].value_counts()
# 返回最大值索引
fillstr = ans.idxmax()
test_data['Embarked'] = test_data['Embarked'].fillna(fillstr)
# 可以发现embarked无缺失了
#修改Sex和Embarked
test_data.replace(["female", "male"], [0, 1], inplace=True)
test_data.replace(["Q", "C", "S"], [0, 1, 2], inplace=True)
#改变age和fare的数据类型
test_data = test_data.astype(np.float32)
test = np.array(test_data)
x_test = torch.from_numpy(test[:, 1:8])
y_test = model(x_test)
y = y_test.data.numpy()
y[y >= 0.5] = 1
y[y < 0.5] = 0
# 导出结果
pIds = pd.DataFrame(data=test_data['PassengerId'].astype(int), columns=['PassengerId'], dtype=int)
preds= pd.DataFrame(data=y, columns=['Survived'], dtype=int)
result= pd.concat([pIds, preds], axis=1)
result.to_csv('titanic_survival_predictions.csv', index=False)
结果展示
Loss 曲线
训练集准确率
![]()
Kaggle Score
