图像分割笔记(一):基于PaddleSeg使用Transfomer模型对航空遥感图像分割
Transformer遥感图像分割
- 一、PaddleSeg
- 二、项目背景
- 三、数据集
-
- CCF BDCI
- UDD6
- 四、准备工作
- 五、训练步骤
-
- 先克隆PaddleSeg的项目
- 下载UDD6数据集
- 安装依赖
- 处理数据集
-
- crop数据化
- 生成训练和验证的txt
- 模型训练与预测
- 开始训练
- 查看损失函数和训练相关的图
- 开始验证
- 开始预测
- 六、参考
一、PaddleSeg
PaddleSeg是基于飞桨PaddlePaddle开发的端到端图像分割开发套件,涵盖了高精度和轻量级等不同方向的大量高质量分割模型。通过模块化的设计,提供了配置化驱动和API调用等两种应用方式,帮助开发者更便捷地完成从训练到部署的全流程图像分割应用
二、项目背景
论文来源:链接
语义分割领域发展迅速,目前更多的是UNet、UNet++、deeplab系列的语义分割网络,很少有研究Transformer的图像分割网络,所以参考了上述的论文所提模型来完成图像分割,网络名称为Seg-Former B3。如何对于transformer的原理不了解可以看看这篇文章:链接
三、数据集
CCF BDCI
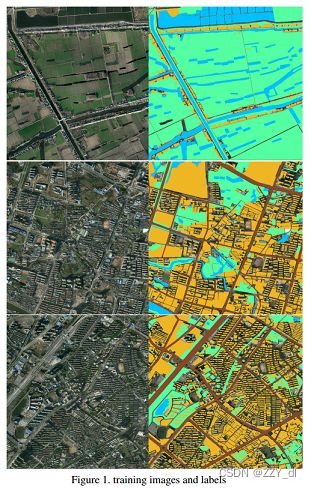
首先介绍一下数据,我们这次采用的数据集是CCF大数据比赛提供的数据(2015年中国南方某城市的高清遥感图像),这是一个小数据集,里面包含了5张带标注的大尺寸RGB遥感图像(尺寸范围从3000×3000到6000×6000),里面一共标注了4类物体,植被(标记1)、建筑(标记2)、水体(标记3)、道路(标记4)以及其他(标记0)。其中,耕地、林地、草地均归为植被类,为了更好地观察标注情况,我们将其中三幅训练图片可视化如下:蓝色-水体,黄色-房屋,绿色-植被,棕色-马路。更多数据介绍可以参看这里。
现在说一说我们的数据处理的步骤。我们现在拥有的是5张大尺寸的遥感图像,我们不能直接把这些图像送入网络进行训练,因为内存承受不了而且他们的尺寸也各不相同。因此,我们首先将他们做随机切割,即随机生成x,y坐标,然后抠出该坐标下256*256的小图,并做以下数据增强操作:
原图和label图都需要旋转:90度,180度,270度
原图和label图都需要做沿y轴的镜像操作
原图做模糊操作
原图做光照调整操作
原图做增加噪声操作(高斯噪声,椒盐噪声)
这里没有采用Keras自带的数据增广函数,而是使用opencv编写了相应的增强函数。
img_w = 256
img_h = 256
image_sets = ['1.png','2.png','3.png','4.png','5.png']
def gamma_transform(img, gamma):
gamma_table = [np.power(x / 255.0, gamma) * 255.0 for x in range(256)]
gamma_table = np.round(np.array(gamma_table)).astype(np.uint8)
return cv2.LUT(img, gamma_table)
def random_gamma_transform(img, gamma_vari):
log_gamma_vari = np.log(gamma_vari)
alpha = np.random.uniform(-log_gamma_vari, log_gamma_vari)
gamma = np.exp(alpha)
return gamma_transform(img, gamma)
def rotate(xb,yb,angle):
M_rotate = cv2.getRotationMatrix2D((img_w/2, img_h/2), angle, 1)
xb = cv2.warpAffine(xb, M_rotate, (img_w, img_h))
yb = cv2.warpAffine(yb, M_rotate, (img_w, img_h))
return xb,yb
def blur(img):
img = cv2.blur(img, (3, 3));
return img
def add_noise(img):
for i in range(200): #添加点噪声
temp_x = np.random.randint(0,img.shape[0])
temp_y = np.random.randint(0,img.shape[1])
img[temp_x][temp_y] = 255
return img
def data_augment(xb,yb):
if np.random.random() < 0.25:
xb,yb = rotate(xb,yb,90)
if np.random.random() < 0.25:
xb,yb = rotate(xb,yb,180)
if np.random.random() < 0.25:
xb,yb = rotate(xb,yb,270)
if np.random.random() < 0.25:
xb = cv2.flip(xb, 1) # flipcode > 0:沿y轴翻转
yb = cv2.flip(yb, 1)
if np.random.random() < 0.25:
xb = random_gamma_transform(xb,1.0)
if np.random.random() < 0.25:
xb = blur(xb)
if np.random.random() < 0.2:
xb = add_noise(xb)
return xb,yb
def creat_dataset(image_num = 100000, mode = 'original'):
print('creating dataset...')
image_each = image_num / len(image_sets)
g_count = 0
for i in tqdm(range(len(image_sets))):
count = 0
src_img = cv2.imread('./data/src/' + image_sets[i]) # 3 channels
label_img = cv2.imread('./data/label/' + image_sets[i],cv2.IMREAD_GRAYSCALE) # single channel
X_height,X_width,_ = src_img.shape
while count < image_each:
random_width = random.randint(0, X_width - img_w - 1)
random_height = random.randint(0, X_height - img_h - 1)
src_roi = src_img[random_height: random_height + img_h, random_width: random_width + img_w,:]
label_roi = label_img[random_height: random_height + img_h, random_width: random_width + img_w]
if mode == 'augment':
src_roi,label_roi = data_augment(src_roi,label_roi)
visualize = np.zeros((256,256)).astype(np.uint8)
visualize = label_roi *50
cv2.imwrite(('./aug/train/visualize/%d.png' % g_count),visualize)
cv2.imwrite(('./aug/train/src/%d.png' % g_count),src_roi)
cv2.imwrite(('./aug/train/label/%d.png' % g_count),label_roi)
count += 1
g_count += 1
经过上面数据增强操作后,我们得到了较大的训练集:100000张256*256的图片。

UDD6
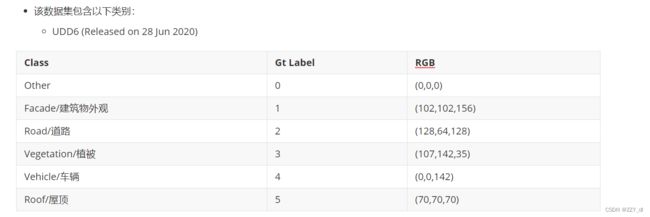
UDD6数据集是北京大学图形与交互实验室采集并标注的,面向航拍场景理解、重建的数据集。


四、准备工作
以UDD6为例
- 开始训练前需要克隆仓库,然后准备数据,最后安装依赖
- 注意:UDD6,图像大小为 (4096, 2160) 所以训练之前先进行crop处理成(1024, 1024)小块的图像以减少IO的占用
此数据集的分布:
–train文件
------gt:训练标签–png
------src: 训练图片–JPG
–val文件
------gt
------src

五、训练步骤
先克隆PaddleSeg的项目
git clone https://gitee.com/paddlepaddle/PaddleSeg
下载UDD6数据集
飞桨AI Studio - 人工智能学习与实训社区 (baidu.com)

下载UDD6即可
安装依赖
%cd /home/aistudio/PaddleSeg
pip install -r requirements.txt
处理数据集
crop数据化
对数据进行crop,具体细节可查看process_data.py的代码
work文件下有一个process_data.py,需要指定数据集的路径
运行:
python process_data.py --tag val #处理验证集
python process_data.py --tag train #处理训练集
如果显示内存不足,则调小下面这个

生成训练和验证的txt
需要指定dataset_root的路径还有images_dir_name和labels_dir_name和label_class。
修改一下format的默认,改成JPG和png
# 训练数据集txt生成
!python tools/split_dataset_list.py \
../work/UDD6 train_sub train_labels_sub \
--split 1.0 0.0 0.0 \
--format JPG png \
--label_class Other Facade Road Vegetation Vehicle Roof
!mv ../work/UDD6/train.txt ../work/UDD6/train_true.txt # 修改文件名
# 验证数据集txt生成
!python tools/split_dataset_list.py \
../work/UDD6 val_sub val_labels_sub \
--split 0.0 1.0 0.0 \
--format JPG png \
--label_class Other Facade Road Vegetation Vehicle Roof
!rm ../work/UDD6/train.txt #删除第二次运行生成的train.txt
!mv ../work/UDD6/train_true.txt ../work/UDD6/train.txt # 将文件名改回来
模型训练与预测
- 使用的模型为Transfomer系列的Segformer_b3
- 训练40000次迭代,共12个小时
新建.yml文件,然后将以下信息写入
#!touch configs/segformer_b3_UDD.yml
复制yml文件,并在文件中插入以下信息。
!touch configs/segformer_b3_UDD.yml - 在文件中插入以下信息
batch_size: 2
iters: 40000
train_dataset:
type: Dataset
dataset_root: ../work/UDD6/
train_path: ../work/UDD6/train.txt
num_classes: 6
transforms:
- type: ResizeStepScaling
min_scale_factor: 0.5
max_scale_factor: 2.0
scale_step_size: 0.25
- type: RandomPaddingCrop
crop_size: [1024, 1024]
- type: RandomHorizontalFlip
- type: RandomDistort
brightness_range: 0.4
contrast_range: 0.4
saturation_range: 0.4
- type: Normalize
mode: train
val_dataset:
type: Dataset
dataset_root: ../work/UDD6/
val_path: ../work/UDD6/val.txt
num_classes: 6
transforms:
- type: Normalize
mode: val
model:
type: SegFormer_B3
num_classes: 6
pretrained: https://bj.bcebos.com/paddleseg/dygraph/mix_vision_transformer_b3.tar.gz
optimizer:
type: sgd
lr_scheduler:
type: PolynomialDecay
learning_rate: 0.001
power: 0.9
loss:
types:
- type: CrossEntropyLoss
coef: [1]
开始训练
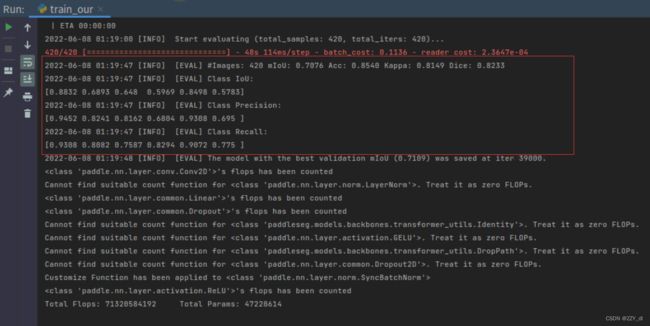
开始训练,模型权重保存在output文件夹中,output/best_model 文件夹中为性能最好的模型
!export CUDA_VISIBLE_DEVICES=0 # 设置1张可用的卡
windows下请执行以下命令
\# set CUDA_VISIBLE_DEVICES=0
!python train_our.py \
--config work/ddrnet23_udd6_1024x1024_120k.yml \
--do_eval \
--use_vdl \
--save_interval 500 \
--save_dir output
查看损失函数和训练相关的图
在终端输入
visualdl --logdir ./output --port 8080

端口号被占用:
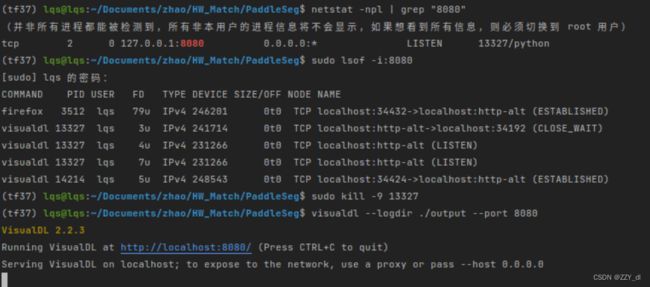
开始验证
修改config和model_path
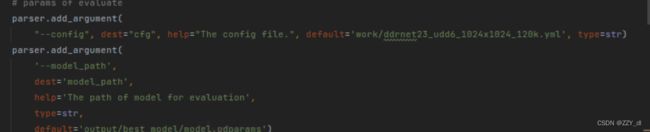
python val_our.py开始验证
开始预测
预测无人机拍的图
python predict.py
--config work/ddrnet23_udd6_1024x1024_120k.yml \
--model_path work/output/best_model/model.pdparams \
--image_path work/test \
--save_dir work/result \
--is_slide \
--crop_size 512 512 \
--stride 256 256
预测卫星图(如果用CCF BDCI数据集效果会非常不错,下面是用UDDB6数据集预测的效果不是很好)
六、参考
- https://www.cnblogs.com/skyfsm/p/8330882.html