【论文解读】Self-Explaining Structures Improve NLP Models
关键词:性能提升、文本分类、信息推理
发表期刊:arXiv 2020
原始论文:https://arxiv.org/pdf/2012.01786.pdf
代码链接https://github.com/ShannonAI/Self_Explaining_Structures_Improve_NLP_Models
浙大联合北大出了篇比较有意思的文章,从模型解释的角度设计了一个称为Self-Explaining的网络模型,该网络模型可以直接加在任何预训练模型之上,来提高模型的性能和准确率。现在让我们来看看这篇文章吧
一、Introduction
由于作者最近在研究文本分类方面的工作,因此本博客不过多介绍解释模型方面的内容,而是讲解该模型到底是怎么做的,为什么会提高模型性能。且作者发现Self-Explaining模型与Self-Attention模型非常的相似,因此还会介绍二者之间的联系与区别
二、Model
先看模型的整体架构

该模型主要分为两部分,下半部分的Intermediate Layer为预训练模型如Bert、Roberta。h1、h2、h3、h4等为预训练模型的出来的Tokens,[h1,h2,h3,h4]的尺寸为[batch,seq,hidden
_size]

上半部分为论文提出的Self-Explaining模型
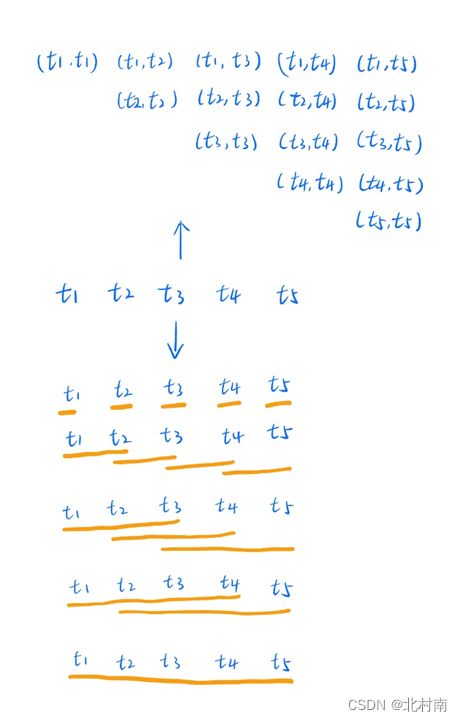
得到所有的Tokens之后,从这些Token中得到所有的Span

所有Span的提取方式也有点意思,比如下面例子,对象是5个token组成的句子,随后
以1个token为一组抽取span,可以得到5个span组
以2个token为一组抽取span,可以得到4个span组
以3个token为一组抽取span,可以得到3个span组
以4个token为一组抽取span,可以得到2个span组
以5个token为一组抽取span,可以得到1个span组
这样总共可以得到(1+N)N/2个span(N为token个数)
得到span之后,需要用一个向量来表示这个span,最简单的想法就是将其放到一个(hidden_size,1)的FFN网络中将span中所有token合并成一个token,这样的办法简单粗暴,但是有个问题是一个Span的时间复杂度就是O(![]() ),所有Span的时间复杂度是O(
),所有Span的时间复杂度是O(![]() ),这样的时间复杂度是非常恐怖的,因此作者做了一个小技巧,就是从h(i,j)中只取hi,hj,hj-hi,hi⊗hj,其中⊗指外积。
),这样的时间复杂度是非常恐怖的,因此作者做了一个小技巧,就是从h(i,j)中只取hi,hj,hj-hi,hi⊗hj,其中⊗指外积。
如此,每个span可以得到4个向量,将4个向量合并成一个新向量代表这个span,以下称为新h(i,j)
将新h(i,j)输入到Interpretation Layer中可得到α(i,j),其运算公式如下,其中![]() 论文中没有特别介绍,看了代码之后可以发现就是一个维度为(heiiden_sieze,1)的FFN
论文中没有特别介绍,看了代码之后可以发现就是一个维度为(heiiden_sieze,1)的FFN
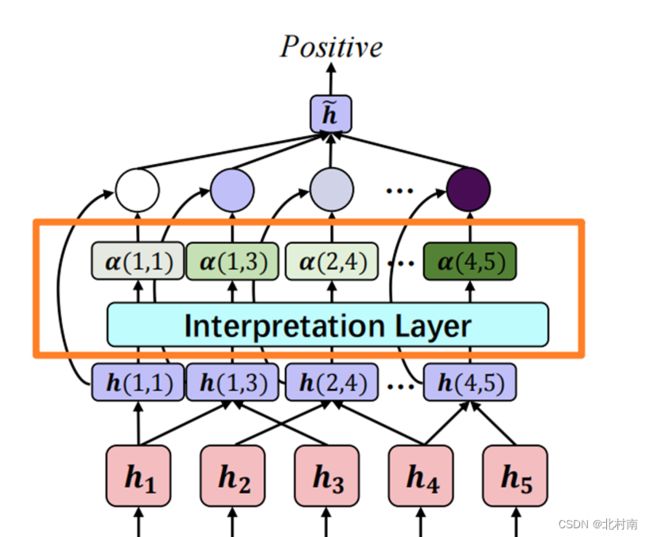

最后将每个h(i,j)与α(i,j)进行相乘,并将所有的相乘结果相加成一个维度为[1,hidden_size]的向量,和Bert直接出来的【CLS】的维度是一样的,因此可以理解为该模型最终可以得到一个增强版的【CLS】,最后接一个FNN进行文本分类即可

三、Loss
损失函数是标准交叉熵加一个设计过的正则项
设计这个正则项的原因是,如在情感分析中,我要判断一个句子的情绪尽量关注少数的几个span。当一个句子只关注一个span时,正则项为最大值即λ,当句子关注所有span时,正则为最小值即λ/N(N为所有span个数)

四、Experiment
到了最快乐的炼丹时间
在SST-5数据集做文本分类任务和在SNLI数据集做推理任务均达到了SOTA

五、Self-Attention <==> Self-Explaining
作者在看该模型的时候就发现它有点像Self-Attention,因此我将二者进行了对比
二者的第一个区别,Self-Attention中hi和hj只有hi⊗hj的关系,而Self-Explaining有hi和hj有4种关系
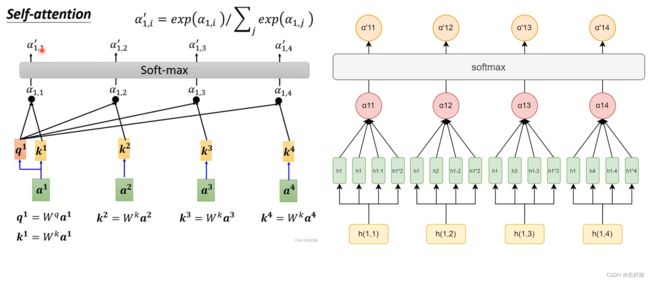

第二个区别是Self-Attention的输出有N个向量而Self-Explaining的输出只有一个向量

作者将模型换了一种画法
这里出现了第三个区别点,由于我们处理Span的策略是只取头和尾,因此Self-Attention也可以看做是一个个双向Span,而Self-Explaining是一个个单向的Span

六、Conclusion
1 该模型可以套到任何预训练模型之上,最终获得一个增强版的【CLS】,可能可以提高模型的性能和ACC
2 关于模型性能为什么提高,作者想可能是因为预训练模型都关注Token级数据,而该模型关注了Span级数据,获取的语义信息等进一步提高了
3 通过与Self-Attention对比发现他们非常的相似,因此我提出了几个新的想法,对Self-Attention的改写是否还有其他方法?Span的提取方式是否可变?Span合并的方式是否可变?与Bert本身有的12层的Transformers进行结合可以到12个Self-Explaining是否有其他操作,如放到TextCNN中?