【论文笔记】2021精彩论文
目录
论文推荐
1、DALL-E:Zero-Shot Text-to-Image Generation,来自OpenAI
2、Swin Transformer: Hierarchical Vision Transformer Using Shifted Windows
3、StyleCLIP: Text-driven manipulation of StyleGAN imagery
4、GitHub Copilot & Codex: Evaluating Large Language Models Trained on Code
5、Taming Transformers for High-Resolution Image Synthesis
6、Thinking Fast And Slow in AI
7、Automatic detection and quantification of floating marine macro-litter in aerial images
8、Generative Adversarial Transformers
9、Barbershop: GAN-based Image Compositing using Segmentation Masks
10、CVPR 2021 Best Paper Award: GIRAFFE - Controllable Image Generation
11、Image Synthesis and Editing with Stochastic Differential Equations
12、Sketch Your Own GAN
13、(Style)CLIPDraw: Coupling Content and Style in Text-to-Drawing Synthesis
14、SwinIR: Image restoration using swin transformer
15、EditGAN: High-Precision Semantic Image Editing
参考github
论文推荐
1、DALL-E:Zero-Shot Text-to-Image Generation,来自OpenAI

论文地址: https://arxiv.org/pdf/2102.12092.pdf
- Short Video Explanation:

- Short read: OpenAI’s DALL·E: Text-to-Image Generation Explained
- Paper: Zero-Shot Text-to-Image Generation
- Code: Code & more information for the discrete VAE used for DALL·E
DALL-E是一个Transformer语言模型。它同时接收文本和图像作为单一数据流,其中包含多达1280个token,并使用最大似然估计来进行训练,以一个接一个地生成所有的token。能利用文本生成图像。
2、Swin Transformer: Hierarchical Vision Transformer Using Shifted Windows

论文地址:https://arxiv.org/pdf/2103.14030.pdf
Transformers 会取代计算机视觉中的 CNNs 吗?在不到 5 分钟的时间内,您将通过一篇名为 Swin Transformer 的新论文了解如何将 Transformer 架构应用于计算机视觉。
- Short Video Explanation:

- Short read: Will Transformers Replace CNNs in Computer Vision?
- Paper: Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
- Click here for the code
Transformer解决计算机视觉问题的挑战主要来自两个领域:图像的比例差异很大,而且图像具有很高的分辨率。像素级的密集预测对于Transformer来说是难以处理的,因为其self-attention的计算复杂度与图像大小成二次关系。

为克服问题,Swin Transformer构建了分层Transformer特征图,并采用移位窗口计算。移位窗口方案通过将self-attention计算限制在不重叠的局部窗口(用红色标出),同时还允许跨窗口连接,带来了更高的效率。
Swin Transformer通过从小尺寸的面片(用灰色勾勒)开始,并逐渐合并更深的Transformer层中的相邻面片来构建分层表示。这种分层体系结构可以灵活地在各种尺度上建模,并且在图像大小方面具有线性计算复杂度。线性计算复杂度是通过在分割图像的非重叠窗口(用红色标出)内局部计算自我注意来实现的。 每个窗口中的面片数量是固定的,因此复杂度与图像大小成线性关系。
3、StyleCLIP: Text-driven manipulation of StyleGAN imagery

论文地址:https://arxiv.org/pdf/2103.17249.pdf
- Short Video Explanation:

- Short read: Manipulate Real Images With Text - An AI For Creative Artists! StyleCLIP Explained
- Paper: Styleclip: Text-driven manipulation of StyleGAN imagery.
- Click here for the code
- Colab demo
使用基于人工智能的生成对抗性网络对照片进行超逼真的修改,并且只需要让用户输入他们想要的东西的描述即可,无需输入特定的图片。

4、GitHub Copilot & Codex: Evaluating Large Language Models Trained on Code

论文地址:https://arxiv.org/pdf/2107.03374.pdf
- Short Video Explanation:

- Short read: OpenAI's New Code Generator: GitHub Copilot (and Codex)
- Paper: Evaluating Large Language Models Trained on Code
- Click here for the code
GPT-3使用了在2019年之前的互联网上的几乎所有公开的书面文本进行训练,所以它对于自然语言是有一定理解能力的,能作诗、聊天、生成文本等等。

Codex基于GPT-3进行训练,接受了从GitHub中提取的TB级公开代码以及英语语言示例的训练。
只要你对Codex发号施令,它就会将英语翻译成代码。
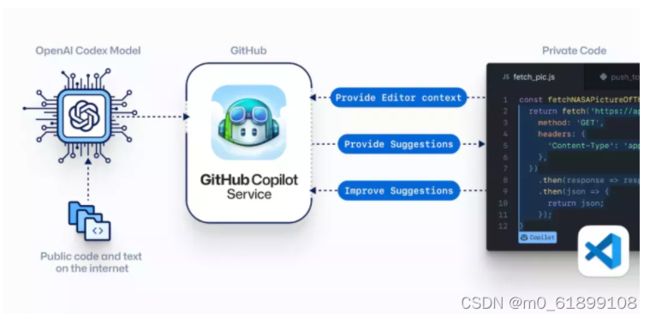
Copilot正是建立在OpenAI强大的Codex算法之上,获得了「海纳百川」的代码积累和前所未有的代码生产能力。Copilot不仅仅可以模仿它见过的代码,而且还会分析利用函数名、方法名、类名和注释的上下文来生成和合成代码,为开发人员提供编辑器中整行代码或函数的建议。还能帮忙编写测试代码。
5、Taming Transformers for High-Resolution Image Synthesis
Tl;DR:他们将 GAN 和卷积方法的效率与转换器的表达能力相结合,为语义引导的高质量图像合成提供了一种强大且省时的方法。
- Short Video Explanation:

- Short read: Combining the Transformers Expressivity with the CNNs Efficiency for High-Resolution Image Synthesis
- Paper: Taming Transformers for High-Resolution Image Synthesis
- Code: Taming Transformers
6、Thinking Fast And Slow in AI
从人类能力中汲取灵感走向更通用和更值得信赖的人工智能和人工智能研究社区的 10 个问题。
- Short Video Explanation:

- Short read: Third Wave of AI | Thinking Fast and Slow
- Paper: Thinking Fast And Slow in AI
7、Automatic detection and quantification of floating marine macro-litter in aerial images
Odei Garcia-Garin 等人。来自巴塞罗那大学的研究人员开发了一种基于深度学习的算法,能够从航拍图像中检测和量化漂浮的垃圾。他们还制作了一个面向网络的应用程序,允许用户在海面图像中识别这些垃圾,称为漂浮海洋垃圾,或 FMML。
- Short Video Explanation:
- Short read: An AI Software Able To Detect and Count Plastic Waste in the Ocean
- Paper: Automatic detection and quantification of floating marine macro-litter in aerial images: Introducing a novel deep learning approach connected to a web application in R, Environmental Pollution
- Click here for the code
8、Generative Adversarial Transformers
他们基本上利用了强大的 StyleGAN2 架构中变压器的注意力机制,使其更加强大!
- Short Video Explanation:

- Short read: GANsformers: Scene Generation with Generative Adversarial Transformers
- Paper: Generative Adversarial Transformers
- Click here for the code
9、Barbershop: GAN-based Image Compositing using Segmentation Masks
这篇文章本身并不是关于一项新技术。相反,它是关于 GAN 的一个令人兴奋的新应用。确实,你看到了标题,它不是点击诱饵。这个 AI 可以转移你的头发,看看它在做出改变之前的样子……
- Short Video Explanation:

- Short read: Barbershop: Try Different Hairstyles and Hair Colors from Pictures (GANs)
- Paper: Barbershop: GAN-based Image Compositing using Segmentation Masks
- Click here for the code
10、CVPR 2021 Best Paper Award: GIRAFFE - Controllable Image Generation
使用修改后的 GAN 架构,他们可以在不影响背景或其他对象的情况下移动图像中的对象!
- Short Video Explanation:

- Short read: CVPR 2021 Best Paper Award: GIRAFFE - Controllable Image Generation
- Paper: GIRAFFE: Representing Scenes as Compositional Generative Neural Feature Fields
- Click here for the code
11、Image Synthesis and Editing with Stochastic Differential Equations
告别复杂的 GAN 和用于图像生成的转换器架构!Chenling Meng 等人的这种新方法。来自斯坦福大学和卡内基梅隆大学的研究人员可以从任何基于用户的输入中生成新图像。即使像我这样的艺术技能为零的人现在也可以从快速草图中生成漂亮的图像或修改...
- Short Video Explanation:
- Short read: Image Synthesis and Editing from Sketches: SDEdit. No more tedious training needed!
- Paper: Image Synthesis and Editing with Stochastic Differential Equations
- Click here for the code
- Colab demo
12、Sketch Your Own GAN
通过按照草图生成图像,让每个人都可以更轻松地进行 GAN 训练!事实上,借助这种新方法,您可以根据您可以提供的最简单的知识类型来控制 GAN 的输出:手绘草图。
- Short Video Explanation:

- Short read: Make GANs Training Easier for Everyone : Generate Images Following a Sketch
- Paper: Sketch Your Own GAN
- Click here for the code
13、(Style)CLIPDraw: Coupling Content and Style in Text-to-Drawing Synthesis
你有没有想过把照片的风格,比如左边这个很酷的TikTok绘画风格,应用到你选择的新照片上?嗯,我做到了,而且从未如此简单。事实上,您甚至可以仅从文本中实现这一点,并且可以立即尝试使用这种新方法及其适用于所有人的 Google Colab 笔记本(请参阅参考资料)。简单的拍一张你要复制的样式的图片,输入你要生成的文字,这个算法就会从中生成一张新的图片!回头看看上面的结果,真是进步了一大步!结果非常令人印象深刻,特别是如果您认为它们是由一行文本制成的!
- Short Video Explanation:

- Short read: Text-to-Drawing Synthesis With Artistic Control | CLIPDraw & StyleCLIPDraw
- Paper (CLIPDraw): CLIPDraw: exploring text-to-drawing synthesis through language-image encoders
- Paper (StyleCLIPDraw): StyleCLIPDraw: Coupling Content and Style in Text-to-Drawing Synthesis
- CLIPDraw Colab demo
- StyleCLIPDraw Colab demo
14、SwinIR: Image restoration using swin transformer
您是否曾经有过您非常喜欢的图像,但只能设法找到它的一个小版本,看起来像左下方的这张图像?如果你能拍下这张照片并让它看起来一样好,那该有多酷?这很棒,但如果你能把它的清晰度提高四到八倍呢?现在我们正在谈论,看看那个。
在这里,我们将图像的分辨率提高了四倍,这意味着我们有四倍的高度和宽度像素来获取更多细节,使其看起来更加平滑。最好的是,这可以在几秒钟内完成,完全自动,并且几乎可以处理任何图像。哦,你甚至可以通过他们提供的演示自己使用它......
- Short Video Explanation:
- Short read: SwinIR: Image restoration using swin transformer
- Paper: SwinIR: Image restoration using swin transformer
- Click here for the code
- Demo
15、EditGAN: High-Precision Semantic Image Editing
从快速草稿中控制任何功能,它只会编辑您想要的内容,保持图像的其余部分不变!NVIDIA、MIT 和 UofT 基于 GAN 的草图模型的 SOTA 图像编辑。
- Short Video Explanation:
- Short read: NVIDIA EditGAN: Image Editing with Full Control From Sketches
- Paper: EditGAN: High-Precision Semantic Image Editing
- Click here for the code (will be released soon)
参考github
GitHub - louisfb01/best_AI_papers_2021: A curated list of the latest breakthroughs in AI by release date with a clear video explanation, link to a more in-depth article, and code. [work in progress]
推荐一个经常分享AI文章的博客:
Louis Bouchard
本文文章也来自于该博客,文中视频可以去github查看,都发布于youtube上。