【论文阅读笔记】Multi-modal Knowledge Graphs for Recommender Systems
Multi-modal Knowledge Graphs for Recommender Systems
1.背景
现有的推荐系统主要分为两种方法,基于内容和协同过滤。
基于内容的方法是针对user-item的历史交互信息进行推荐的,协同过滤利用user-item群体的行为交互数据进行推荐,然而协同过滤会存在数据稀疏和冷启动的问题。
因此,近几年的研究将知识图谱引入推荐系统,提供高阶特性,丰富一些隐藏的连接,增强推介系统的可解释性。然而现有的知识图谱仅利用了知识图谱的结构化数据,只关注节点和节点关系,忽略了多模态知识图谱信息。
本文的贡献
开发了新的MKGAT模型,利用多模态知识图谱上的信息传播来获得更好的实体嵌入来进行推荐
通过两个大规模真实数据集进行的实验证明了模型的合理性和有效性
相关工作
作者将多模态信息加入到了知识图谱,并总结了前人使用多模态信息的方法:
基于特征的方法
将模态信息作为实体的辅助特征。通过考虑视觉表示来扩展TransE。可以从知识图谱实体相关联的图像中提取视觉表示。三元组的能量是根据知识图谱的结构和实体的视觉表示来定义的。因此,每个实体必须包含图像属性。该方法忽略了有些实体不包含多模态信息,缺乏部分实际场景的考虑,无法广泛应用
基于实体的方法
将不同的模态信息作为结构化知识的关系三元组,而不是预先确定的特征。在这些著作中,多模态信息被认为是知识图谱的一等公民,然后采用基于实体的方法,利用CNN的KGE方法训练知识图谱嵌入,然而现有的基于实体的方法独立处理三元组,忽略了多模态信息融合,对多模态组不友好
2.模型框架
提出了一种新的模型,多模态知识图谱注意力网络(MKGAT),主要由两个子模块组成(多模态知识图嵌入模块和推荐模块)
在子模块中还是用了两个关键组件:多模态知识图谱编码器和多模态知识图谱注意层。

3.Multi-modal Knowledge Graph Embedding
3.1 Multi-modal Knowledge Graph Entity Encoder(多模态知识图谱实体编码器)
使不同的编码器嵌入每种特定的数据类型
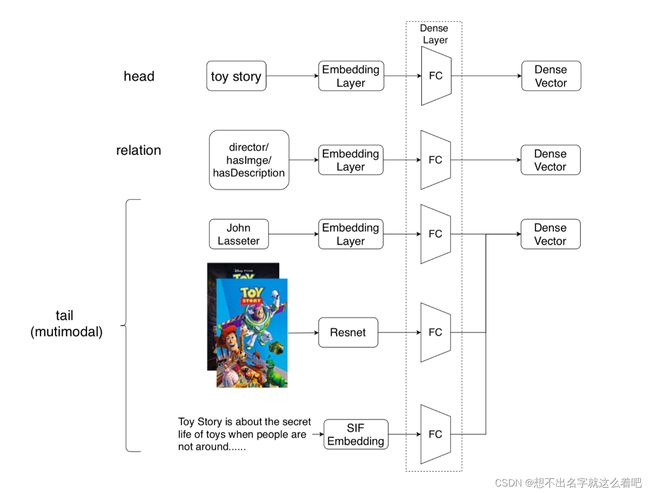
Structured knowledge
考虑以(h,r,t)形式存在的三元组信息。为了将head entity,tail entity和relation r表示为独立的嵌入向量,通过嵌入层传递实体id或关系id来生成密集向量
Image
为了嵌入图像,使编码能够表示这些语义信息,我们使用了ResNet50的最后一层隐藏层,该模型由Imagenet预训练得到。
Texts
文本信息与内容高度相关,以便捕获用户偏好。对于文本实体,我们使用Word2Vec训练词向量,然后应用SIF(Smooth Inverse Frequency,SIF)模型得到一个句子的词向量的加权平均,通过句子向量来表示文本特征。该模型相比使用LSTM对句子编码具有更好的性能。
3.2Multi-modal Knowledge Graph Attention Layer(多模态知识图谱注意层)
沿高阶连接性递归地传播嵌入,此外还利用图注意网络(GATs)的思想,生成级联传播的注意权值,以揭示这种连通性的重要性,由于GATs忽略了KGs之间的关系,不适用于KGs,因此对GATs进行修改,考虑了KGs关系嵌入

Propagation layer(传播层)
通过TransE模型学习知识图谱的结构化表示,将实体h的多模态邻接实体聚合到实体h,丰富实体h的表示。
N h 表示与 h 相连的三元组集合。 e a g g 是一个聚合邻居实体信息的表示向量,是每个三元组表示的线性组合 e a g g = ∑ ( h , r , t ) ∈ N h Π ( h , r , t ) e ( h , r , t ) e ( h , r , t ) 是每个三元组的嵌入,而 Π ( h , r , t ) 是每个 e ( h , r , t ) 的注意力分数,控制 e ( h , r , t ) 的信息量 (1) N_h表示与h相连的三元组集合。e_{agg}是一个聚合邻居实体信息的表示向量,是每个三元组表示的线性组合 e_{agg}=\sum_{(h,r,t)\in{N_h}}Π(h,r,t)e(h,r,t) \tag{1} \\ e(h,r,t)是每个三元组的嵌入,而Π(h,r,t)是每个e(h,r,t)的注意力分数,控制e(h,r,t)的信息量 Nh表示与h相连的三元组集合。eagg是一个聚合邻居实体信息的表示向量,是每个三元组表示的线性组合eagg=(h,r,t)∈Nh∑Π(h,r,t)e(h,r,t)e(h,r,t)是每个三元组的嵌入,而Π(h,r,t)是每个e(h,r,t)的注意力分数,控制e(h,r,t)的信息量(1)
为了学习三元组关系的嵌入,通过对实体h,t,关系r嵌入串联进行线性变换来学习这种嵌入:
e ( h , r , t ) = W 1 ( e h ∣ ∣ e r ∣ ∣ e t ) (2) e(h,r,t)=W_1(e_h||e_r||e_t) \tag{2} e(h,r,t)=W1(eh∣∣er∣∣et)(2)
通过关系注意机制实现Π(h,r,t):
Π ( h , r , t ) = L e a k y R e L U ( W 2 e ( h , r , t ) ) (3) Π(h,r,t)=LeakyReLU(W_2e(h,r,t)) \tag{3} Π(h,r,t)=LeakyReLU(W2e(h,r,t))(3)
采用LeakyReLU作为非线性激活函数,然后采用softmax函数对与h相连的所有三元组的系数进行归一化:
Π ( h , r , t ) = e x p ( Π ( h , r , t ) ) ∑ ( h , r ‘ , t ‘ ) ∈ N h e x p ( Π ( h , r ‘ , t ‘ ) ) (4) Π(h,r,t)=\frac{exp(Π(h,r,t))}{\sum(h,r^`,t^`) \in{N_h}exp(Π(h,r`,t`))} \tag{4} Π(h,r,t)=∑(h,r‘,t‘)∈Nhexp(Π(h,r‘,t‘))exp(Π(h,r,t))(4)
Aggregation layer(聚合层)
将实体表示 e h 和对应的 e a g g 聚合为实体 h 的新表示。本文通过两种方法实现聚合函数 f ( e h , e a g g ) 将实体表示e_h和对应的e_agg聚合为实体h的新表示。本文通过两种方法实现聚合函数f(e_h,e_{agg}) 将实体表示eh和对应的eagg聚合为实体h的新表示。本文通过两种方法实现聚合函数f(eh,eagg)
1)ADD聚合
f a d d = W 3 e h + e a g g W 3 为权重矩阵 (5) f_{add}=W_3e_h+e_{agg} \tag{5} \\ W_3为权重矩阵 fadd=W3eh+eaggW3为权重矩阵(5)
2)Concatenation聚合
使用线性转换将实体和聚合实体连接在一起:
f c o n c a t = W 4 ( e h ∣ ∣ e a g g ) W 4 是可训练的模型参数 (6) f_{concat}=W_4(e_h||e_{agg}) \tag{6} \\W_4是可训练的模型参数 fconcat=W4(eh∣∣eagg)W4是可训练的模型参数(6)
3.3 Knowledge Graph Embedding
使用知识图谱嵌入中广泛使用的平移评分函数来训练知识图谱嵌入,当三元组有效时,通过优化平移原则学习如何嵌入每个实体和关系,其中e_h和e_t是来自MKGs注意层的新实体嵌入。三元组(h,r,t)的分数表示:
s c o r e ( h , r , t ) = ∣ ∣ e h + e r − e t ∣ ∣ 2 2 (7) score(h,r,t)=||e_h+e_r-e_t||_2^2 \tag{7} score(h,r,t)=∣∣eh+er−et∣∣22(7)
4.Recommendation
与知识图谱嵌入模块类似,推荐模块也使用MKGs注意层来聚合邻居实体信息。
5.模型影响和效果
对比KGAT和MKGAT模型在大众点评数据集上的实验结果
具有多模态特征的方法优于具有单模态特征的方法
视觉模态在推荐效果上比文本模态更重要
与KGAT相比,MKGAT模型更好地利用图像信息提高推荐性能,因为MKGAT能更好地将图像实体的信息聚合成item实体
6.结论
本文提出了一种创新型地将多模态知识图谱引入到推荐系统中基于知识图谱的推荐系统——多模态知识图谱注意网络(multimodal Knowledge Graph Attention Network, MKGAT),该模型通过学习实体间关系,并将相邻实体信息聚合到自身,可以更好地利用多模态实体信息,并在实验中验证了模型地合理性和有效性。