在Mnist数据上使用k折交叉验证训练,pytorch代码到底怎么写
前言
最近学到了K折交叉验证,已经迫不及待去实验一下他的效果是不是如老师讲的一样好,特此写下本文。
本文运行环境为:sklearn、pytorch 、jupyter notebook
在Mnist数据上使用k折交叉验证训练,pytorch代码到底怎么写
k折交叉验证
baseline
导入包
设定一些初始值
加载数据集
visualization数据集
【output】
加载模型、优化器与损失函数
训练函数
测试函数
train and test baseline
【output】
k fold cross validation[1-10]
【重点:fold的数据集处理】
一是将这个Mnist数据集的训练集和测试集合并,这一块的坑不少。
二是使用Sklearn中的KFold进行数据集划分,并且转换回pytorch类型的Dataloader。
对于KFold:
参数介绍:
【output】
设定K值为[2,10]进行训练
【小实验】
【参考文献】
k折交叉验证
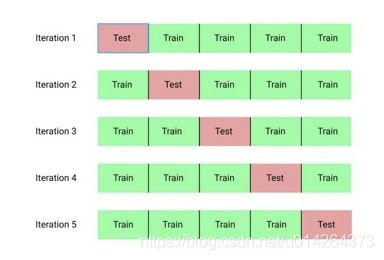
五折交叉验证: 把数据平均分成5等份,每次实验拿一份做测试,其余用做训练。实验5次求平均值。如上图,第一次实验拿第一份做测试集,其余作为训练集。第二次实验拿第二份做测试集,其余做训练集。依此类推~
baseline
先看一个最简单的,朴实无华,什么tricks都没加的基础模型。
导入包
#---------------------------------Torch Modules --------------------------------------------------------
from __future__ import print_function
import numpy as np
import pandas as pd
import torch.nn as nn
import math
import torch.nn.functional as F
import torch
import torchvision
from torch.nn import init
import torch.optim as optim
from torchvision import datasets, transforms
from torchvision import models
import torch.nn.functional as F
from torch.utils import data
import matplotlib.pyplot as plt
import os
os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE"设定一些初始值
###-----------------------------------variables-----------------------------------------------
# for Normalization
mean = [0.5]
std = [0.5]
# batch size
BATCH_SIZE =128
Iterations = 1 # epoch
learning_rate = 0.01加载数据集
##-----------------------------------Commands to download and perpare the MNIST dataset ------------------------------------
train_transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean, std)
])
test_transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean, std)
])
train_loader = torch.utils.data.DataLoader(
datasets.MNIST('./mnist', train=True, download=True,
transform=train_transform),
batch_size=BATCH_SIZE, shuffle=True) # train dataset
test_loader = torch.utils.data.DataLoader(
datasets.MNIST('./mnist', train=False,
transform=test_transform),
batch_size=BATCH_SIZE, shuffle=False) # test datasettransforms是用来增强数据集的,例如:旋转,裁剪....等等
visualization数据集
#visualization
def show_images(imgs, num_rows, num_cols, titles=None, scale=1.5):
"""Plot a list of images."""
figsize = (num_cols * scale, num_rows * scale)
_, axes = plt.subplots(num_rows, num_cols, figsize=figsize)
axes = axes.flatten()
for i, (ax, img) in enumerate(zip(axes, imgs)):
if torch.is_tensor(img):
# Tensor Image
ax.imshow(img.numpy())
else:
# PIL Image
ax.imshow(img)
ax.axes.get_xaxis().set_visible(False)
ax.axes.get_yaxis().set_visible(False)
if titles:
ax.set_title(titles[i])
return axes
mnist_train = torchvision.datasets.MNIST(root="../data", train=True,
transform=train_transform,
download=True)
X, y = next(iter(data.DataLoader(mnist_train, batch_size=18)))
show_images(X.reshape(18, 28, 28), 2, 9)【output】
加载模型、优化器与损失函数
model = nn.Sequential(nn.Flatten(), nn.Linear(784, 256), nn.ReLU(),nn.Linear(256, 10))
def init_weights(m):
if type(m) == nn.Linear:
nn.init.normal_(m.weight, std=0.01)
model.apply(init_weights);
## Loss function
criterion = torch.nn.CrossEntropyLoss() # pytorch's cross entropy loss function
# definin which paramters to train only the CNN model parameters
optimizer = torch.optim.SGD(model.parameters(),learning_rate)训练函数
# defining the training function
# Train baseline classifier on clean data
def train(model, optimizer,criterion,epoch):
model.train() # setting up for training
for batch_idx, (data, target) in enumerate(train_loader): # data contains the image and target contains the label = 0/1/2/3/4/5/6/7/8/9
data = data.view(-1, 28*28).requires_grad_()
optimizer.zero_grad() # setting gradient to zero
output = model(data) # forward
loss = criterion(output, target) # loss computation
loss.backward() # back propagation here pytorch will take care of it
optimizer.step() # updating the weight values
if batch_idx % 100 == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))测试函数
# to evaluate the model
## validation of test accuracy
def test(model, criterion, val_loader, epoch,train= False):
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for batch_idx, (data, target) in enumerate(val_loader):
data = data.view(-1, 28*28).requires_grad_()
output = model(data)
test_loss += criterion(output, target).item() # sum up batch loss
pred = output.max(1, keepdim=True)[1] # get the index of the max log-probability
correct += pred.eq(target.view_as(pred)).sum().item() # if pred == target then correct +=1
test_loss /= len(val_loader.dataset) # average test loss
if train == False:
print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.4f}%)\n'.format(
test_loss, correct, val_loader.sampler.__len__(),
100. * correct / val_loader.sampler.__len__() ))
if train == True:
print('\nTrain set: Average loss: {:.4f}, Accuracy: {}/{} ({:.4f}%)\n'.format(
test_loss, correct, val_loader.sampler.__len__(),
100. * correct / val_loader.sampler.__len__() ))
return 100. * correct / val_loader.sampler.__len__() train and test baseline
test_acc = torch.zeros([Iterations])
train_acc = torch.zeros([Iterations])
## training the logistic model
for i in range(Iterations):
train(model, optimizer,criterion,i)
train_acc[i] = test(model, criterion, train_loader, i,train=True) #Testing the the current CNN
test_acc[i] = test(model, criterion, test_loader, i)
torch.save(model,'perceptron.pt')【output】

我们可以看到准确率不是很高,甚至可以说模型鲁棒性表现的不好,才83%。那么接下来就是我们的重头戏了,我们现在打算使用k折交叉验证,需要修改什么地方呢?
- Step1、修改数据集
- Step2、设定k值
- STep3、重新训练
k fold cross validation[1-10]
只需要在最下方插入这一行代码即可,会覆盖掉之前的变量,而且因为是在函数内部运行,与之前的代码没有冲突。
【重点:fold的数据集处理】
#!pip install sklearn -i https://pypi.mirrors.ustc.edu.cn/simple
from sklearn.model_selection import KFold
train_init = datasets.MNIST('./mnist', train=True,
transform=train_transform)
test_init = datasets.MNIST('./mnist', train=False,
transform=test_transform)
# the dataset for k fold cross validation
dataFold = torch.utils.data.ConcatDataset([train_init, test_init])
def train_flod_Mnist(k_split_value):
different_k_mse = []
kf = KFold(n_splits=k_split_value,shuffle=True, random_state=0) # init KFold
for train_index , test_index in kf.split(dataFold): # split
# get train, val
train_fold = torch.utils.data.dataset.Subset(dataFold, train_index)
test_fold = torch.utils.data.dataset.Subset(dataFold, test_index)
# package type of DataLoader
train_loader = torch.utils.data.DataLoader(dataset=train_fold, batch_size=BATCH_SIZE, shuffle=True)
test_loader = torch.utils.data.DataLoader(dataset=test_fold, batch_size=BATCH_SIZE, shuffle=True)
# train model
test_acc = torch.zeros([Iterations])
train_acc = torch.zeros([Iterations])
## training the logistic model
for i in range(Iterations):
train(model, optimizer,criterion,i)
train_acc[i] = test(model, criterion, train_loader, i,train=True) #Testing the the current CNN
test_acc[i] = test(model, criterion, test_loader, i)
#torch.save(model,'perceptron.pt')
# one epoch, all acc
different_k_mse.append(np.array(test_acc))
return different_k_mse上面这个代码,解决的重点有哪些呢?
一是将这个Mnist数据集的训练集和测试集合并,这一块的坑不少。
train_init = datasets.MNIST('./mnist', train=True,
transform=train_transform)
test_init = datasets.MNIST('./mnist', train=False,
transform=test_transform)
# the dataset for k fold cross validation
dataFold = torch.utils.data.ConcatDataset([train_init, test_init])二是使用Sklearn中的KFold进行数据集划分,并且转换回pytorch类型的Dataloader。
kf = KFold(n_splits=k_split_value,shuffle=True, random_state=0) # init KFold
for train_index , test_index in kf.split(dataFold): # split
# get train, val 根据索引划分
train_fold = torch.utils.data.dataset.Subset(dataFold, train_index)
test_fold = torch.utils.data.dataset.Subset(dataFold, test_index)
# package type of DataLoader
train_loader = torch.utils.data.DataLoader(dataset=train_fold, batch_size=BATCH_SIZE, shuffle=True)
test_loader = torch.utils.data.DataLoader(dataset=test_fold, batch_size=BATCH_SIZE, shuffle=True)对于KFold:
提供训练集/测试集索引以分割数据。将数据集拆分为k折(默认情况下不打乱数据。
参数介绍:
n_splits:int, 默认为5。表示拆分成5折
shuffle: bool, 默认为False。切分数据集之前是否对数据进行洗牌。True洗牌,False不洗牌。
random_state:int, 默认为None 当shuffle为True时,如果random_state为None,则每次运行代码,获得的数据切分都不一样,random_state指定的时候,则每次运行代码,都能获得同样的切分数据,保证实验可重复。random_state可按自己喜好设定成整数,如random_state=42较为常用。当设定好后,就不能再更改。
例子:
from sklearn.model_selection import KFold
import numpy as np
X = np.arange(24).reshape(12,2)
y = np.random.choice([1,2],12,p=[0.4,0.6])
kf = KFold(n_splits=5,shuffle=False) # 初始化KFold
for train_index , test_index in kf.split(X): # 调用split方法切分数据
print('train_index:%s , test_index: %s ' %(train_index,test_index))
【output】
train_index:[ 3 4 5 6 7 8 9 10 11] , test_index: [0 1 2]
train_index:[ 0 1 2 6 7 8 9 10 11] , test_index: [3 4 5]
train_index:[ 0 1 2 3 4 5 8 9 10 11] , test_index: [6 7]
train_index:[ 0 1 2 3 4 5 6 7 10 11] , test_index: [8 9]
train_index:[0 1 2 3 4 5 6 7 8 9] , test_index: [10 11]
注意:
设置shuffle=False,每次运行结果都相同
设置shuffle=True,每次运行结果都不相同
设置shuffle=True和random_state=整数,每次运行结果相同
设定K值为[2,10]进行训练
testAcc_compare_map = {}
for k_split_value in range(2, 10+1):
print('now k_split_value is:', k_split_value)
testAcc_compare_map[k_split_value] = train_flod_Mnist(k_split_value)testAcc_compare_map是将不同k值下训练的结果保存起来,之后我们可以通过这个字典变量,计算出rmse ,比较不同k值下,实验结果的鲁棒性。

【小实验】
我想发布一下小作业,试图帮助大家体悟k折交叉验证:
1.执行k倍交叉验证,选择k=1-10,绘制(a)平均列车对数rmse vs k(b)平均
对数rmse vs k〔20分〕
2.当你增加k的值时会发生什么?解释两次损失的行为
随着k的增加[20点]
【补充材料】
对于RMSE:

实验结果中ACC随着K值增大的变化如下【2=1就是baseline的结果,此处是k=[2,10]】:
【参考文献】
【1】五折交叉验证/K折交叉验证, python代码到底怎么写_Tina姐的博客-CSDN博客_五折交叉验证