全链路总结!推荐算法召回-粗排-精排
作者 | Salon sai 整理 | NewBeeNLP
https://zhuanlan.zhihu.com/p/463021052
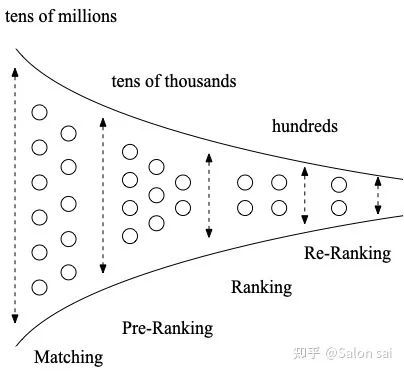
大家好,这里是NewBeeNLP。现在的推荐系统都是一个很大的漏斗,将整个推荐系统分为(recall -> pre-rank -> rank -> rerank)。
 推荐链路
推荐链路
因为当前的系统没有办法一次性对所有的候选item(量级上亿)去做预估,因此需要通过不同环节去处理庞大的候选池。每一层都是各司其职, 召回决定天花板,粗排为了性能效率,精排决定最终推荐精度 。而今年我将这三者都结合一起做。在此对工作做了些分享,也总结这一年的工作。
2. Recall
2.1 召回目的&工程pipeline大概设计
召回最重要的一点是 全面,覆盖所有的用户可能会消费的item ,它决定着整个推荐算法的天花板。而由于面对上亿级别的池子,因此recall是一个及其简单的模型/规则。这些规则是并行计算的, 保证recall的效率 。
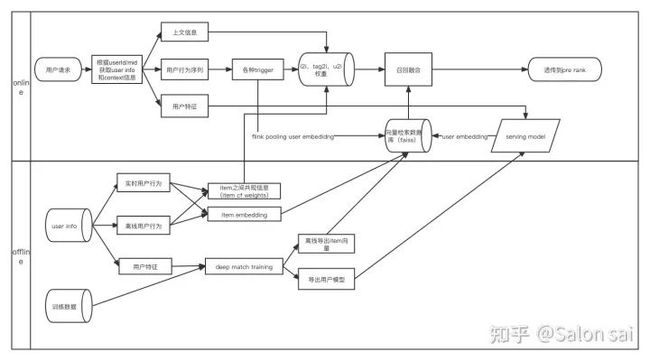
以下是召回系统pipeline的简单理解:
 召回工程流程图
召回工程流程图
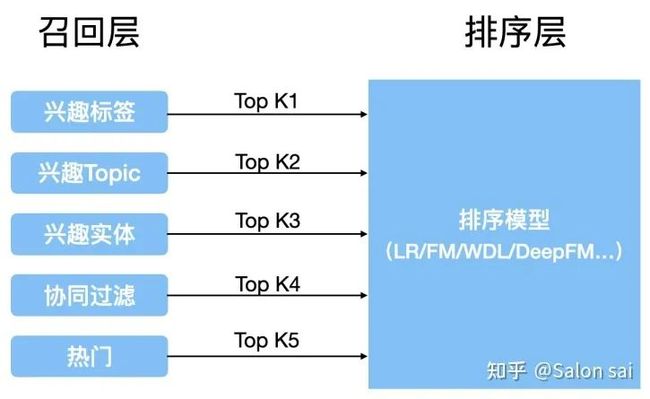
多通道召回当中,每个召回通道其实都是有偏。这就有点像 集成学习 的思想: 弱弱为强,各取所长,平衡误差
 多通道召回
多通道召回
2.2 常用的召回队列/方式
2.2.1 cf召回
I2i, tag2i, u2u2i这些其实本质就是熟悉的协同过滤算法,在离线生成一个矩阵存储item之间,tag与item之间,user与user之间的相关权值weight,在线上把用户的行为(item,tag记录)作为key去查相关的item,构造出候选池子。
2.2.2 embedding召回
通过用户的行为序列构建一张大的graph或者random walk得到序列,使用w2v技术去生成graph embedding。 使用item embedding对用户不同行为序列(click seq, order seq….)做聚合 ,在线实时生成user embedding,再通过faiss向量检索。
2.2.3 deepmatch
熟悉的模型像dssm,mind等。根据项目需要可以以多目标的形式去训练模型,线下t+1的时间窗口生成item embedding(要求实时性强的通过flink去做流式计算),并推动到faiss上。线上推理服务实时计算不同query embedding(user embedding),对于deep match训练,关键是 负采样(负样本为王),因为最大的问题是sample selection bias ,
2.3 负采样方式
deepmatch虽然在召回队列的quota只有10%左右,但 曝光占比却去到60% 。因为deepmatch在召回又举足轻重的地位,因此这里另外加多一节去简要说明其常用做法。
| 采样方式 | 说明 |
|---|---|
| 全局随机负采样 | 这种随机从全场景曝光过item采样,使用listwise存储负样本,能够最大程度保证数据分布一致,但随机采样的负样本有可能跟正样本差异大。对于一些hard negative sample能区分得好。 |
| in batch负采样 | 由于listwise样本存储空间大(negative sample可能上百),因此正样本内做batch内负采样,即batch内的user vector与item vector构建一个cosine对角线矩阵,对角线为正样本的cosine,其余作为负样本cosine。这种采样方式是有损的,但实验对比在可接受范围内,而且负样本都是其他正样本,因此具有一定热度打压的作用。 |
| Popularity随机选择负采样 | 基于随机负采样,加入热度item作为负样本。因为热门item没有作为正样本,那么极有可能该item是不相关或者用户不感兴趣。 |
| Hard负采样 | 模型在训练/serving时,总有部分item逃过模型的法眼,透传到粗排甚至精排当中。因此可以通过线上日志中找出有召回但粗排过滤的,有召回但没有曝光。又或者在训练过程当中,从item库中检索cosine值高于某一个theshold的items,并随机选取。此举可以提高模型的精度,过滤无关的item。 |
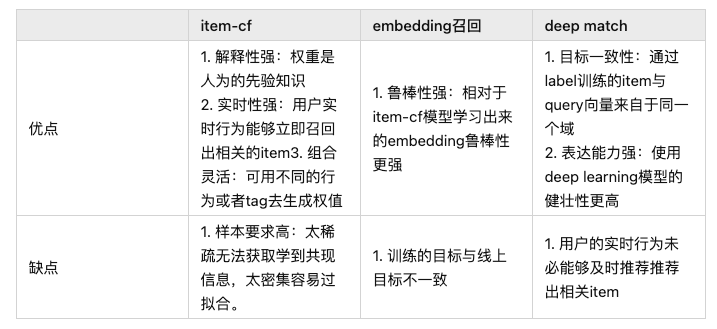
2.4 各种召回的优缺点
3. Pre-rank
粗排位置十分尴尬,位于精排前,召回后。实际上,由于精排的性能问题,它不可能将召回的结果全部排,所以需要一个模型提高排序的性能,因此粗排他就是 精排的影子,拟合精排结果的序 。在我这边的方案是:
3.1 精排的topN作为样本
粗排位置十分尴尬,位于精排前,召回后。实际上,由于精排的性能问题,它不可能将召回的结果全部排,所以需要一个模型提高排序的性能,因此粗排他就是 精排的影子,拟合精排结果的序 。在我这边的方案是:
3.1.1 精排多目标拟合
同时标记多个目标的item,将这些item做一个交集,并标记好item在每个精排目标上是否为topN。
3.1.2 精排线上最终预估分拟合
一般粗排的模型是单目标的(精排的序)而精排的线上预估分又依赖与商业需要调整,那么根据业务需要将精排多目标结果去构建预估分并按照其排序。
3.2 pairwise learning rank
使用交叉熵形式学习topN,其实是有损的,而最佳方式是学习当中的序。 那么从一个请求随机采样两个样本
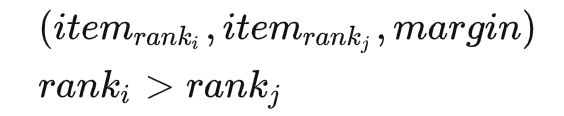
通过pairwise loss:
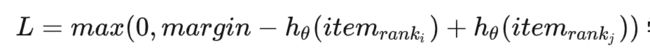
学习这两个item之间的序,而margin作为超参控制模型的学习难度,太小可能会让模型无法学习精排的序,太大模型难以收敛。
3.3 蒸馏精排
一直以来我们的目标都是拟合精排的序, 那么我们是否能够在精排训练的时候让粗排也跟着学习精排的得分 ,蒸馏也就应运而生。通过T温度参数调整logist,使teacher的logist的概率值具有更好的概率分布(最好符合高斯分布)。而对于student就能更好学习teacher的高预估分和低预估分的信息,序的信息也就能够学到了。
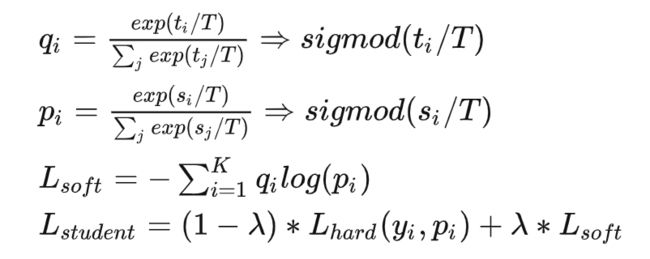
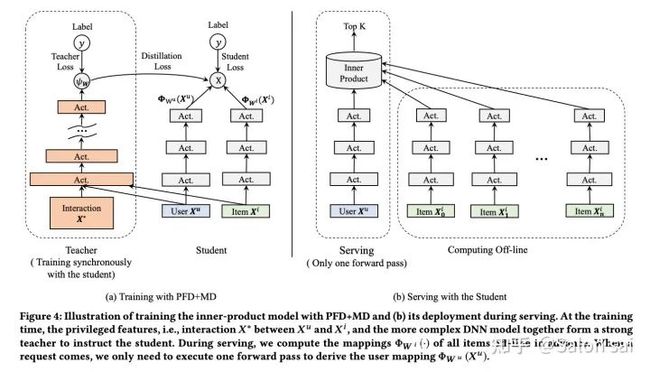 精排蒸馏召回模型
精排蒸馏召回模型
4. Rank
4.1 基础模型
一般来说,业务都是多目标,因此在这里都是使用esmm + mmoe方式去做模型。选择这两个模型的结合是有以下的原因:
Data sparse:cvr对应的点击样本(negative sample)远小于ctr曝光样本(negative sample)
Sample Selection Bias:cvr样本一般是指点击到转化的链路, 因此positive sample为订单样本,negative sample为点击未转化的样本 。然而线上预估的时候不是点击样本,这就是线上线下的 数据分布偏差 的问题。这种做法可以延续到更多具有数据分布偏差的问题:impression -> click -> watch time -> order (cvr)。
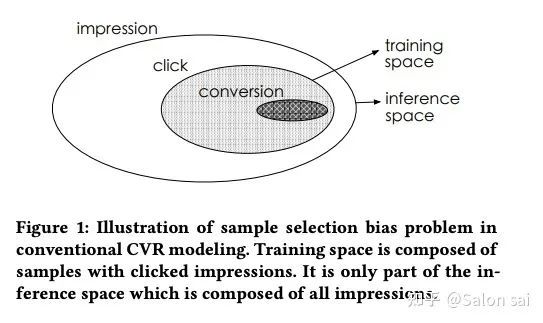 sample selection bias
sample selection bias 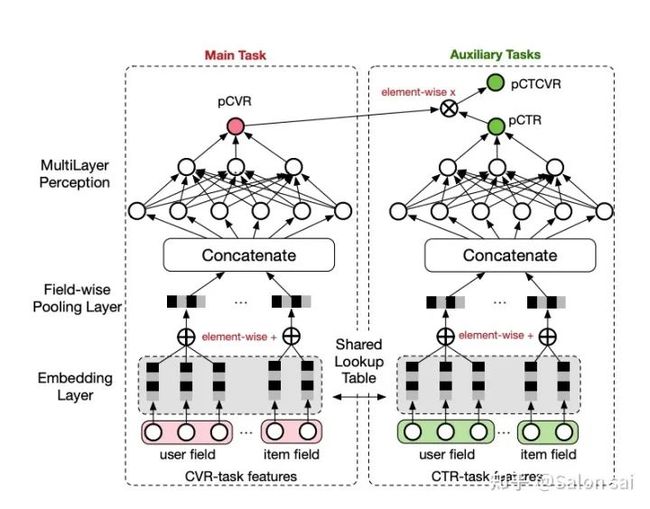 ESSM结构截图
ESSM结构截图
Ensemble learning:mmoe通过 n个独立expert network + 针对 m个task的gating network 每个gating network本质上就是对n个 expert network的概率分布(softmax) 。expert network + gating network就为每个task生成其需要的bottom,而n个独立expert network就是借鉴了** 集成学习(random forest) **的思想。
4.2 模型升级

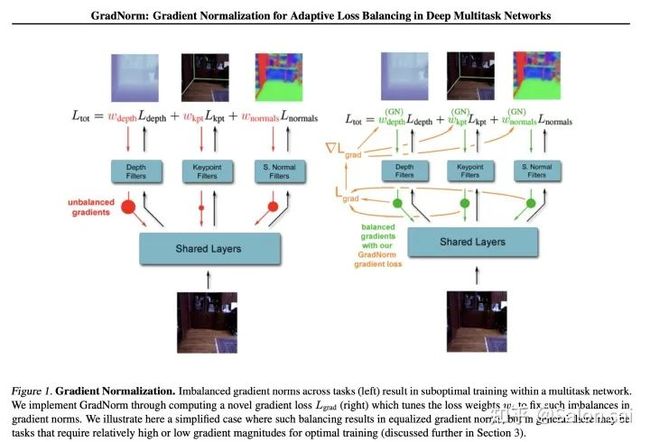 GradNorm调整不同loss的权重
GradNorm调整不同loss的权重
PLE:mmoe虽然有集成学习的思想,但是task与task存在差异与训练冲突。因此给每个task提供 独立一个或者多个expert network ,将其独特性学习出来。
5. Summary
以上是我和团队的小伙伴一起努力一些成果和积累。从召回到精排,每一层漏斗其实都是有损失的,而这个损失是因为现有算法工程限制。在召回的评价指标更着重于hitrate,粗排考虑auc/gauc/ndcg,精排考虑auc/gauc。要想做出 效果必须从上至下去优化 ,假如只是优化召回多样性,但粗排没有相应的特征召回的信息是无法透传到精排。 有些团队直接放弃粗排,只用召回和精排 ,这样效果也会更直接的体现,但也可能会出现我刚刚说的问题。
这一年来最大感触是: 推荐算法其实是需要工程和业务共同努力,不是仅仅靠怼特征,魔改模型就能够出效果 。没有好的工程系统,算法业务的发展会严重受限(如良好的推理框架,训练集群,离线平台,内存数据库等)。由于效果的提升需要涉及各个层面,因此阿里推出了,全链路一致性建模优化COLD[1]。这个也是我希望未来能够去尝试的一个思路和方向。