Vision Transformer这两年

作者|Maximilian Schambach
OneFlow编译
翻译|胡燕君、杨婷
在NLP领域取得巨大成功后,Transformer架构在计算机视觉方面的作用日渐凸显,成为越来越普遍的CV工具。自2020年10月Vision Transformer模型推出以来,人们开始高度关注Transformer模型在计算机视觉上的应用。
![]() 图 1:各类Vision Transformer模型的推出时间(此处以论文在arXiv平台上的发表时间为准)
图 1:各类Vision Transformer模型的推出时间(此处以论文在arXiv平台上的发表时间为准)
恰逢Vision Transformer推出两周年之际,借此机会我们对其稍作介绍,并讨论这两年来发展出的多种Vision Transformer模型变体以及Transformer在计算机视觉应用方面面临的各种挑战。本文由OneFlow社区编译。
1
自注意力机制和Transformer架构
从NLP说起,2017年,Attention is all you need一文提出了Transformer架构(Vaswani et al. 2017)。Transformer架构的本质是一个序列到序列模型:输入的是一种称为token的序列,token在NLP中是指对句子的数学表示。将句子转化为序列,要将句子中的每个词(或子词)映射为一个向量表示,该向量表示称为对应词的embedding(嵌入)。
生成的embedding token序列由Transformer编码器在几个自注意力层和全连接层中处理,然后输出一个与输入长度相同的高级token表示序列。翻译等任务需要使用完整的输出序列,而分类等任务则只需用到单个表示。在分类任务中,要为整个句子或整个段落生成单个表示用于分类,通常会为序列附加一个特殊的可学习嵌入向量 Class_Token([CLS] token)。可以将[CLS] token的表示传入classfier head(分类器头)。
下图是Transformer架构的总览,图左展示了Transformer编码器。自注意力机制是Transformer架构的关键。自注意力层中的所有中间token表示会通过计算成对相似性(pairwise similarities)进行互动,这些成对相似性会成为上一层相应token表示的权重。
 图 2:Transformer编码器和自注意力机制(图片来自原论文)
图 2:Transformer编码器和自注意力机制(图片来自原论文)
为了计算成对相似性,通常会通过简单可学习的线性层从embedding中计算query (Q)、key (K)和value (V)向量,然后所有K和Q之间进行双向softmax自注意力计算,获得各自的相似性,然后将相似性与V相乘。也就是说,在自注意力层中,每个token都通过各自K和Q的简单点积与其他token进行比较,随后再运行(scaled) softmax操作。
如图2右边所示,为了能够在每个阶段学习不同形式的自注意力,Transformer架构使用了多个self-attention head(自注意力头)。具体来说,每个head都映射了来自输入表示的不同Q、K、V向量。例如,在Transformer的某个固定级别,不同的attention head可以关注token之间的短、长距离或语义和句法关系。不同的attention head的输出由线性层进行连接和处理,以便重新获得通过skip connection传递的输入表示的维度。不熟悉Transformers基本概念的读者可以参考原论文获取更多详细信息(https://proceedings.neurips.cc/paper/2017/hash/3f5ee243547dee91fbd053c1c4a845aa-Abstract.html)。
2
Vision Transformer模型
从Transformer架构被引进NLP到它在计算机视觉领域(ImageNet图像识别任务)取得SOTA性能,中间隔了3年,这和深度学习研究的迅猛进展相比显得较为缓慢。但从抽象的角度讲,这并不令人意外。毕竟Transformer是序列模型,无法直接兼容图像和视频等高维且近似连续的输入数据类型。与序列不同,图像和视频可被视为从底层连续信号中离散采样的数据。
此外,Transformer模型没有局部性(locality)和平移不变性(translational equivariance)等归纳偏置(inductive bias),但归纳偏置在处理图像等数据时十分有用。要让Transformer模型习得这些属性,需要使用大量的训练数据。相反,卷积神经网络(CNN)实行归纳偏置,CNN过去十年在视觉领域取得的成功很大程度归功于此。
不过,也有观点认为,没有归纳偏置可以让Transformer架构更具通用性。例如,Transformer模型的浅层即可提取全局信息,但CNN由于感受野(receptive field)较小,只能在神经网络的深层提取全局信息。
从实践角度讲,Transformer模型在计算机视觉领域应用进展缓慢的另一个原因是:Transformer模型的输入序列长度缺乏可扩展性。由于标准的双向自注意力机制中所有token表示都是成对比较的,所以标准的Transformer模型中,随着input token序列变长,计算所需时间和内存会呈二次方增长。因此,即使是分辨率只有256 × 256的小型图像,每个像素点为一个input token,总共就形成含65,000个token的超长序列,导致操作可行性极低。
为了解决上述难题,Dosovitskiy等人提出了Vision Transformer模型(ViT,图3),该模型使用的是一种“简单粗暴”的方法:
首先,一张大小为X × X × C的输入图像被分成M × M个图像块(patch),每个图像块为固定大小P × P(为了简化问题,此处假定输入图像都是正方形)。每个图像块(P × P × C)被展平(flatten)为一个形状为P ⋅ P ⋅ C的向量,然后运用可训练的线性层将该向量映射为一个维度为D的embedding。展平得到的向量为图像块embedding,即input token,其中包含了每个图像块的信息。
最后,一个M × M的图像块embedding阵列被展平为一个长度为N = M ⋅ M的token序列,然后喂入Transformer模型中。可以将分块、展平和线性映射操作视为一个如下的2D卷积操作:使用D个形状为P × P × C 的卷积核(kernel),步长(stride)为(P, P),无填充(padding)。
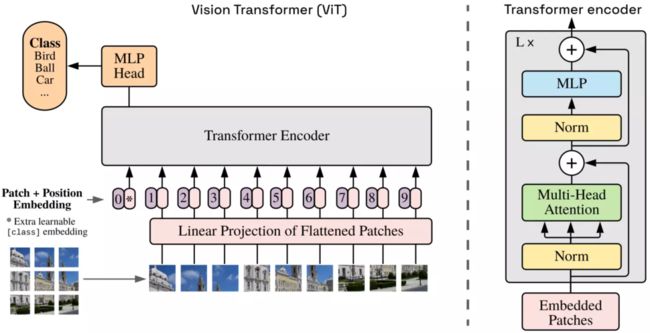 图3:ViT模型架构。仅[CLS] token的输出表示被用于分类任务和有监督训练(图源:https://openreview.net/forum?id=YicbFdNTTy)
图3:ViT模型架构。仅[CLS] token的输出表示被用于分类任务和有监督训练(图源:https://openreview.net/forum?id=YicbFdNTTy)
与NLP领域的标准Transformer模型相同,embedding token和附加的[CLS] token一起传入Transformer编码器,编码器(图3右)包含几个多头自注意力机制(multi-headed self-attention)与MLP层。标准的ViT中,潜在的维度D从头到尾都是固定的。[CLS] token的输出被输入到classification head中,[CLS] token的输出表示包含输入图像的所有必要信息,即[CLS] token的输出表示被用作潜在图像表征,与CNN自编码器中的瓶颈表征(bottleneck representation)相似。[CLS] token在有监督分类任务中训练时需要与高度依赖图像的token embedding交互。
标准的ViT (ViT-B)中,图像块大小为P = 16,因此一张大小为64 × 64 × 3的RGB图像会被分为16个图像块。每个图像块被展平为一个长度为16 ⋅ 16 ⋅ 3 = 768的向量,向量被线性层映射为一个维度D = 768的向量。长度为1 + 16的input token序列被传入包含12层组件的编码器中进行处理,每个自注意力模块有12个head。ViT模型中约有8600万参数,更大型的ViT模型变体,如ViT-L和ViT-H分别有3亿和6亿参数。基础ViT模型的大小相当于标准ResNet-152模型(6000万参数),而SOTA CNN模型的大小则相当于ViT-L和ViT-H。Dosovitskiy等人在论文中将ViT与ResNet-152x4和Efficientnet-L2这两种CNN模型对比,前者有9亿参数,后者有5亿参数。
总体而言,ViT模型,特别是ViT-L和ViT-H,在JFT-300M大型数据集上预训练,然后迁移到ImageNet和CIFAR等中小型数据集上,都取得了SOTA性能表现。与基于CNN的视觉领域大型主干网络(backbone)相反,ViT需要的训练资源较少。不过,即便是相对较少的训练资源,中小型研究机构也难以负担。此外,虽然上述方法在原理上能使Transformer模型更好地应用于视觉领域,但还存在其他难点,ViT原始论文和后续论文也提出了相应的解决方法。
3
Transformer模型在视觉领域的应用难点
第一个难点是,Transformer模型无法区分input token的排列位置变化。也就是说,Transformer模型不能理解input token之间的位置关系。在NLP任务中,token在序列中的1D位置信息非常重要,因为位置信息代表了语序,对此,Transformer的解决方法是对token embedding进行位置编码。
将位置信息编码到一个token embedding,即为每个token的位置信息单独生成一个维度为D的向量,称为positional embedding,然后将它添加到token embedding中,再传入Transformer模型。Positional embedding可能是可学习的,也可能是固定的,它的生成方式是根据相应token的位置在不同频率的正弦曲线上的不同位置采点(Vaswani et al. 2017)。
Positional embedding也称为傅里叶特征。通过上述方法,可以为任意长度的序列生成positional embedding,因此,Transformer模型可以处理任意长度的句子。
然而,ViT模型更为棘手,因为它需要恢复图像块的2D位置信息——即该图像块截取自原图像的哪一个区域。要做到这一点,ViT对每N个input token使用可学习的1D positional embedding,由N个可学习的维度为D的向量组成。训练时,对positional embedding没有显式监督,也就是说,ViT并不能理解input token之间的实际2D关系。
不过,Dosovitzky等人通过计算每对positional embedding之间的相似性后发现,ViT习得的positional embedding确实包含相应图像块的2D位置信息。这一重大发现证明了Transformer架构的强大性能和通用性。
然而,这种方法需要在训练中将输入序列的长度N调整为固定值。图像块的大小也需要固定(否则就会影响linear embedding层),这意味着要将输入图像调整为固定分辨率才能用于训练,因为小批次训练要求每批次中所有输入图像的分辨率相同,在CNN模型中则不需要这样做。在ViT模型中,推理时也需要调整图像块大小,即调整输入图像的分辨率,因为分辨率过大会导致input token序列过长。
如图4中的例子,图像块大小依然是前面提到的16 × 16,那么一张大小为128 × 128的图像就会被分为64个图像块。前面提到,训练时一张大小为64 × 64的图像被分成16个图像块,那么ViT模型就只习得16个positional embedding,这时模型需要将这16个positional embedding泛化从而适应不同的分辨率,同时保证它们所代表的2D位置信息依然完整。
好在,代表同一2D位置关系的各个positional embedding具有相似性,因此可以采用2D插值(interpolation)将它们泛化,以适应任意分辨率,同时保留所习得的位置信息(图4)。这一方法由Dosovitskiy等人提出,它看似可行,但原始论文并没有对这种方法进行量化估计。原始论文中,所有用于训练的图像被降低至常用的224 × 224分辨率,用于微调(fine-tuning)的图像则调至更高分辨率。
 图4:将positional embedding从4 × 4个图像块重采样为8 × 8个图像块
图4:将positional embedding从4 × 4个图像块重采样为8 × 8个图像块
其次,这种方法会导致每个图像块内像素点之间的位置关系丢失,还会导致密集预测(dense prediction)任务只能在图像块层次完成。例如语义分割中的逐像素点分类任务。这就要求我们在表现力和吞吐量之间做出取舍:图像块尺寸较小(最小尺寸为1 × 1 px)可以更大程度地保留原图像的底层空间关系,获得密集的潜在表征(latent representation),但会导致吞吐量变小,所需内存空间也会大得难以实现。
为了解决这个问题,一些早期论文提出将注意力机制限制在本地像素邻域中(http://proceedings.mlr.press/v80/parmar18a.html),或者采用下采样(downsampling),将输入图像的分辨率调整得非常小(http://proceedings.mlr.press/v119/chen20s.html;https://openreview.net/forum?id=HJlnC1rKPB)。如果图像块大小达到最高限制,即单个图像块即包含整张原图,则没有可用的位置信息,这时token embedding层就会成为模型架构中的瓶颈,严重影响模型性能。
同样,各图像块边缘的邻近像素点之间的位置关系也会丢失。分块操作不受图像内容的影响,也就是说,图像的分块方式是随意的,有可能导致分出的每个图像块中各个像素点之间的情境关联并不大,进而导致从输入图像中习得的重要特征无法直接应用到图像块上,需要通过相应的token embedding进行重组。这就增加了下游任务(downstream task)的难度,也对patch embedding层提出了更高要求,还导致难以实现平移不变性。
最后,如前所述,标准的Transformer架构中,随着输入序列变长,运行所耗费的时间和内存空间都会呈二次方增长。因此,ViT模型不适合处理高分辨率图像和其他高维数据,也不宜将图像块设置得太小。为了解决以上难题,ViT模型首度公开不久后就出现了许多变体。
4
Vision Transformer模型发展现状
接下来我们将介绍一些ViT模型变体,它们进一步推动了计算机视觉的SOTA性能,并解决了部分上述提到计算机视觉应用难题。
DeiT模型(Data-Efficient Image Transformer)
Touvron等人通过数据增强(data augmentation)等精细训练策略,在不依靠大型专有数据集的情况下实现了出色的模型性能(依然以ImageNet图像分类任务为衡量标准),这一点与原始ViT模型相反,ViT模型是在Google的JFT-300M闭源数据集上训练的。
Touvron等人还使用一种专门针对Transformer模型的蒸馏(distillation)技术进一步改进ViT模型。将一个性能强大,但可能庞大而难以训练的teacher模型“蒸馏”为一个基于Transformer架构的student模型,做法和Hinton等人提出的”知识蒸馏“相似(Hinton et al. 2014)。这种模型称为DeiT模型(Data-Efficient Image Transformer)。
与图5所示相似,distillation token的输出表示被输入到额外的classification head中用于预测teacher模型的输出标签。[CLS] token按照惯常做法被传入(另一个)classifier head获得真实分类标签。总损失函数是使用真实标签计算出的常规交叉熵损失的加权平均值和基于distillation classifier head的logit输出与teacher模型logit输出的KL散度(Kullback Leibler divergence)的损失项。这样,Transformer中,student模型就可以借助teacher模型来提升自身的训练速度和质量。
 图5: DeiT的特征蒸馏(图片来自相应论文)
图5: DeiT的特征蒸馏(图片来自相应论文)
此外,更强的数据增强可能会导致图片不符合其真实标签,例如当裁剪出的图像块没有包含原图标签所指物体(图6)。为了缓解这个问题,可以使用一个不仅基于真实标签,而且基于teacher模型所预测标签的损失。此外,一些图像的分类标签可能不够明确,因为尽管图像可能包含多种物体,但每张图像只关联一个标签。
他们使用强大的CNN分类器显著提高了student模型的基准表现,这可能是利用了teacher模型中包含的归纳偏置,采用这种方式可以在不需要太多的训练数据的情况下从头开始训练Transformer模型。事实上,蒸馏得出的模型性能优于teacher模型,并在ImageNet图像分类任务上取得了SOTA性能,缩小了Transformer模型和CNN模型之间的差距。
DeiT模型加快了训练速度,用ImageNet训练DeiT只需4块GPU训练3天。虽然它的性能不如那些在JFT-300M等更大型数据集上预训练的ViT模型,但它的计算成本要小得多。
 图6:来自ImageNet数据集的示例图像(左),对其进行裁剪会产生不同的标签(右)
图6:来自ImageNet数据集的示例图像(左),对其进行裁剪会产生不同的标签(右)
Swin Transformer模型 (Shifted Windows Transformer)
为了解决ViT模型中图像块边缘空间信息部分丢失和计算复杂度二次方增长的问题,Liu等人引入了一种基于分层特征图和移位窗口(shifted window, Swin)的ViT模型(Liu et al. 2021)。Swin Transformer有两个核心贡献,如图7所示。
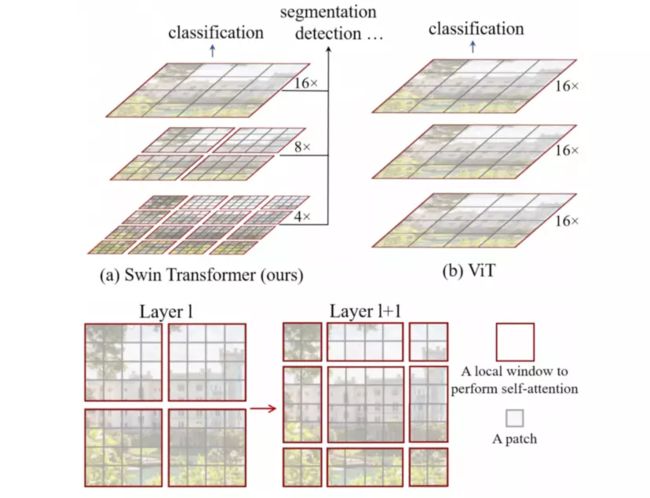 图7:Swin中的分级特征图(上)与后续神经网络层窗口移位(下)(图源:https://openaccess.thecvf.com/content/ICCV2021/html/Liu_Swin_Transformer_Hierarchical_Vision_Transformer_Using_Shifted_Windows_ICCV_2021_paper.html)
图7:Swin中的分级特征图(上)与后续神经网络层窗口移位(下)(图源:https://openaccess.thecvf.com/content/ICCV2021/html/Liu_Swin_Transformer_Hierarchical_Vision_Transformer_Using_Shifted_Windows_ICCV_2021_paper.html)
首先,为了降低计算复杂度,自注意力机制的计算范围限制在非重叠层本地窗口内,每个窗口默认包含7×7个图像块。(图3为了方便图解,将窗口描绘为4×4个图像块。)Swin Transformer模型共有4个阶段,为了处理输入图像中的非本地大型空间关系信息,图像块序列经过每个阶段时都会被下采样。下采样由可训练的线性层完成,将2×2个图像块连接起来进行下采样,将特征维度扩大2倍,使下采样效率提升2倍。
由此形成了一个特征金字塔,可以用在需要密集本地计算和全局特征的任务中,与传统U-Net架构中生成的特征金字塔相似(Ronneberger et al. 2015)。与特征金字塔类似,SIFT和SURF等经典图像处理算法中会使用图像金字塔来获取尺度不变特征(scale-invariant feature)。默认情况下,Swin Transformer并不处理[CLS] token,而是将最后一个阶段已平均的特征喂入classification head,后者用于根据ImageNet数据集对模型进行有监督训练。
此外,每个阶段中,基于移位窗口有两种不同的图像块切分方式(图7)。此处,移位窗口包含之前已分离且不参与自注意力机制计算的图像块。论文显示,在ImageNet图像分类任务、COCO目标检测任务和ADE20k语义分割任务中使用移位窗口,都可以实现比静态窗口高得多的性能。总体而言,由于每个窗口的图像块数量固定,因此Swin Transformer的内存和计算复杂度从二次方增长降低为线性增长,性能比原始ViT模型和DeiT模型更加出色。
除了Swin Transformer,NLP和计算机视觉领域还有很多方法可以基于标准双向softmax自注意力机制降低Transformer模型的计算复杂度,包括使用softmax自注意力机制的稀疏近似或低秩近似(low-rank approximation)(Wang et al. 2020, Zaheer et al. 2020, Kitaev et al. 2020, Choromanski et al. 2021),调整注意力机制(Ali et al. 2021, Jaegle et al. 2021, Lu et al. 2021, Jaegle et al. 2022),优化标准方法——例如优化IO操作等(Dao et al 2022)。为了对不同的Transformer架构进行深度比较,我们使用的是Long Range Arena这一较新的评估基准(Tay et al. 2021)。
DINO模型(Self-distillation with no labels)
目前谈及的ViT模型都经过有监督的分类任务(预)训练。Caron等人从另一个方向进行研究,在DeiT的基础上构建了一种自监督训练ViT模型,也取得了良好成果。这种模型无需使用DeiT所用的显式teacher模型,而是引入了一种无标签自蒸馏(self-distillation with no labels, DINO,https://openaccess.thecvf.com/content/ICCV2021/html/Caron_Emerging_Properties_in_Self-Supervised_Vision_Transformers_ICCV_2021_paper.html)方法。
图8:DINO架构。图源Meta AI文章
如图8所示,teacher模型被定义为student模型的指数移动平均值(EMA),student模型是一个标准的ViT模型。NLP领域常见的自监督训练方法使用遮罩(masking)和input token序列补全方法来避免模型坍塌(Devlin et al. 2019, Brown et al. 2020),而视觉领域的自监督学习通常使用的是对比损失(contrastive loss)。在对比学习框架中,两个版本的神经网络处理相同(或不同)的增强图像,经过训练努力输出相同(或不同)的表示。
然而,与近来的BYOL (Grill et al. 2020)、Barlow Twins (Zbontar et al. 2021)和VICReg (Bardes et al. 2022)等自监督学习方法相似,DINO并不通过对比损失显式利用负样本。相反,DINO将同一输入图像的两个增强版本分别传入student模型和teacher模型,teacher模型处理一张原图像的全局裁剪(涵盖输入图像的较大区域),student模型处理一张原图像的局部裁剪(涵盖输入图像的较小区域)。使用简单的MLP projection head从[CLS] token的输出表示中得到预测的softmax logit,然后用交叉熵损失与teacher模型中的logit进行比较。梯度只在student模型网络中传播。
还有其他工程方法可以避免模型坍塌,这些方法的核心概念都是使student模型预测出一个与teacher模型的预测结果相似的图像表示——teacher模型处理的输入图像与student模型的略有不同——这样可以提升从局部到全局的关联性。用ImageNet图像和自蒸馏方法训练DINO(不使用标签),结果发现DINO可以在无监督的情况下为同一标签下的图像生成相似的表示。DINO通过简单的KNN分类器和潜在图像表征就在无监督ImageNet图像分类任务上取得了出色表现。
论文还显示,DINO可以高效学习包含输入图像语义分割信息的表示(图9)。为了提供合理分辨率的语义分割映射,DINO中的图像块尺寸为4×4,比ViT和DeiT的都小得多。基于DINO表示的自然语义集群,近期一些论文还探讨了自监督语义分割(Hamilton et al. 2022)。
 图9:标准视觉主干网络无监督训练得到的分割图(上)DINO无监督训练得到的分割图(下)(图片来自相应论文)
图9:标准视觉主干网络无监督训练得到的分割图(上)DINO无监督训练得到的分割图(下)(图片来自相应论文)
5
总结
多年来,Transformer模型成为NLP的首选模型,如今,Transformer也逐渐取代CNN成为计算机视觉领域的SOTA模型。ViT-L和ViT-H等大型Transformer模型也被视为基础模型,它们在作为通用型视觉主干网络使用时也表现出优异性能,特别是利用大型数据集训练之后。
然而,Transformer模型应用于图像和视频时还存在不少难点,业内正在进行积极研究。我们还须探索高样本效率的自监督学习策略和使Transformer模型更适应特定领域或数据集的方法,相信也会引发更多应用型计算机视觉研究。
许多主流的Vision Transformer架构都由Google (原始ViT)、Microsoft (Swin)、Huawei (TNT)、 OpenAI (iGPT)、Meta (DINO)等科技巨头研发,需要使用大量计算资源。为了降低从零开始训练Vision Transformer的计算复杂度、硬件要求和数据要求,业内进行了大量研究。本文介绍了一部分但未能穷举。相信Vision Transformer在视觉领域的运用将会越来越成功。
(本文经授权后由OneFlow编译发布,译文转载请联系OneFlow获得授权。原文:1. https://medium.com/merantix-labs-insights/a-brief-history-of-vision-transformers-revisiting-two-years-of-vision-research-26a6bd3251f3;2. Merantix Momentum GitHub: https://github.com/merantix-momentum)
直播现在约!!!
大模型训练难于上青天?今晚19:00,OneFlow工程师教你训练技巧,欢迎围观。
其他人都在看
-
机器学习编译器的前世今生
-
OneFlow-ONNX v0.6.0正式发布
-
更快的YOLOv5问世,附送全面中文解析教程
-
李白:你的模型权重很不错,可惜被我没收了
-
Stable Diffusion半秒出图;VLIW的前世今生
-
大模型狂潮背后:AI基础设施“老化”与改造工程
-
OneEmbedding:单卡训练TB级推荐模型不是梦
欢迎Star、试用OneFlow最新版本:https://github.com/Oneflow-Inc/oneflow