图片速览 GroupViT: Semantic Segmentation Emerges from Text Supervision
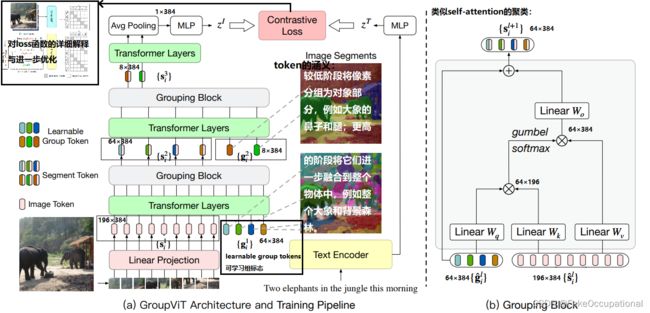
loss函数包含两部分 image-text loss + multi-label contrastive loss with text prompting
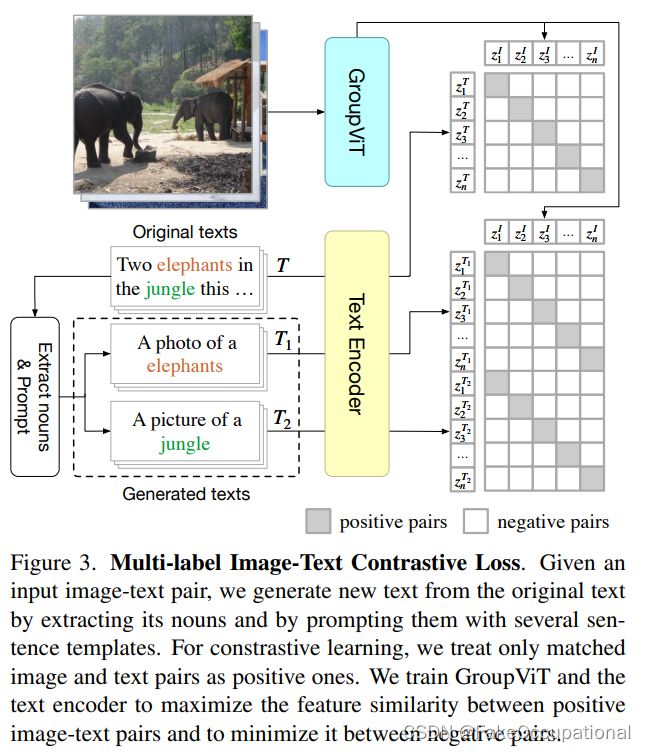
推理阶段
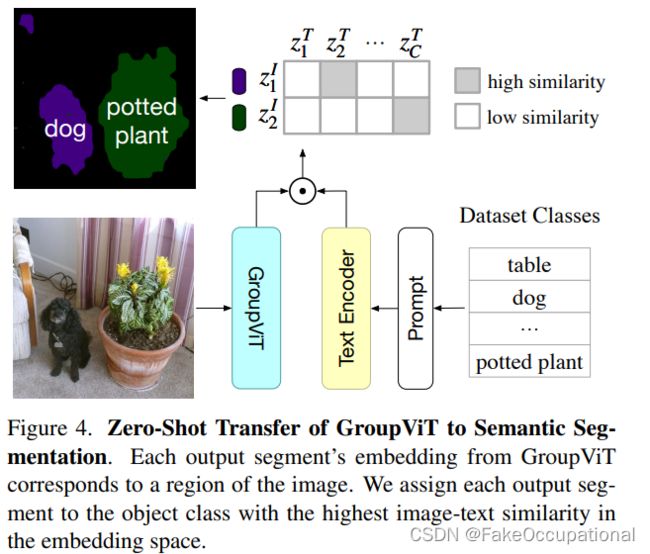
以下为更多参考与解释
- 传统的分割方法经常使用聚类的处理(grouup),这里也采用了一个Grouping Block
| paper | code | 相关 |
|---|---|---|
| 2022 CVPR https://arxiv.org/abs/2202.11094 | https://github.com/NVlabs/GroupViT | GroupViT: Semantic Segmentation Emerges from Text Supervision |
根据ViT[24]的设计,我们首先将输入图像分割成N个不重叠的块,并将每个块线性投影到一个潜在空间。我们将每个投影面片视为一个输入图像标记,并表示所有
其中 { p i } i = 1 N \{p_i\}^N _{i=1} {pi}i=1N。在每个分组阶段,除了图像标记外,我们连接一组可学习的组标记,并将它们输入到该阶段的Transformer中。
根据ViT[24]的设计,我们首先将输入图像分割成N个不重叠的块,并将每个块线性投影到一个潜在空间。我们将每个投影面片视为一个输入图像标记,并将它们的集合表示为 { p i } i = 1 N \{p_i\}^N _{i=1} {pi}i=1N。在每个分组阶段,除了图像标记外,我们连接一组可学习的组标记,并为该阶段将它们输入Transformer。
- Multi-stage Grouping
{ g ^ i l } , { s ^ i l } = T r a n s f o r m e r ( [ g i l ; s i l ] ) { s i l + 1 } = G r o u p i n g B l o c k ( g ^ i l , s ^ i l ) { s ^ i L + 1 } = T r a n s f o r m e r ( { s i L + 1 } ) 最终全局图像表示 z I = M L P ( A v g P o o l ( { s ^ i L + 1 } ) ) . \huge \{ \hat g^l_i\}, \{\hat s^l_i\} = Transformer([{g^l_i}; {s^l_i}])\\ \{s^{l+1}_i\} = GroupingBlock({\hat g^l_i}, {\hat s^l_i})\\ \{\hat s^{L+1}_i\} = Transformer(\{ s^{L+1}_i\})\\ 最终全局图像表示 z^I = MLP(AvgPool(\{\hat s^{L+1}_i\})). {g^il},{s^il}=Transformer([gil;sil]){sil+1}=GroupingBlock(g^il,s^il){s^iL+1}=Transformer({siL+1})最终全局图像表示zI=MLP(AvgPool({s^iL+1})).
代码
- models\group_vit.py
- 简单看一下 函数 forward 和 forward_image_head
def forward(self, x, *, return_feat=False, return_attn=False, as_dict=False):
x, group_token, attn_dicts = self.forward_features(x, return_attn=return_attn)
x_feat = x if return_feat else None
outs = Result(as_dict=as_dict)
outs.append(self.forward_image_head(x), name='x')
if return_feat:
outs.append(x_feat, name='feat')
if return_attn:
outs.append(attn_dicts, name='attn_dicts')
return outs.as_return()
def forward_image_head(self, x):
"""
Args:
x: shape [B, L, C]
Returns:
"""
# [B, L, C]
x = self.avgpool(x.transpose(1, 2)) # B C 1
x = torch.flatten(x, 1)
x = self.head(x)
return x
- 代码中给出了两种初始化position_embedding的方法
if pos_embed_type == 'simple':
self.pos_embed = self.build_simple_position_embedding()
elif pos_embed_type == 'fourier':
self.pos_embed = self.build_2d_sincos_position_embedding()
else:
raise ValueError
- 向前传递的方法
def forward_features(self, x, *, return_attn=False):
B = x.shape[0]
x, hw_shape = self.patch_embed(x)
x = x + self.get_pos_embed(B, *hw_shape)
x = self.pos_drop(x)
group_token = None
attn_dict_list = []
for layer in self.layers:
x, group_token, attn_dict = layer(x, group_token, return_attn=return_attn)
attn_dict_list.append(attn_dict)
x = self.norm(x)
return x, group_token, attn_dict_list
- 其中layer为:
layer = GroupingLayer(
dim=dim,
num_input_token=num_input_token,
depth=depths[i_layer],
num_heads=num_heads[i_layer],
num_group_token=num_group_tokens[i_layer],
mlp_ratio=self.mlp_ratio,
qkv_bias=qkv_bias,
qk_scale=qk_scale,
drop=drop_rate,
attn_drop=attn_drop_rate,
drop_path=dpr[sum(depths[:i_layer]):sum(depths[:i_layer + 1])],
norm_layer=norm_layer,
downsample=downsample,
use_checkpoint=use_checkpoint,
group_projector=group_projector,
# only zero init group token if we have a projection
zero_init_group_token=group_projector is not None)
self.layers.append(layer)