Tensorflow Keras中的masking与padding的学习笔记
Tensorflow Keras中的masking与padding
- 1. 背景
- 2. padding填充序列数据例子
- 3. 遮盖(masking )
-
- 3.1 添加一个 keras.layers.Masking 层。
- 3.2 使用 mask_zero=True 配置一个 keras.layers.Embedding 层。
- 3.3. 在调用支持 mask 参数的层(如 RNN 层)时,手动传递此参数。
- 4 编写需要掩码信息的层
1. 背景
Masking的作用是告知序列处理层输入中有某些时间步骤丢失,因此在处理数据时应将其跳过。
padding是Masking的一种特殊形式,其中被Masking的步骤位于序列的起点或开头。填充是出于将序列数据编码成连续批次的需要:为了使批次中的所有序列适合给定的标准长度,有必要填充或截断某些序列。
2. padding填充序列数据例子
在处理序列数据时,各个样本常常具有不同长度。请考虑以下示例(文本被切分为单词):
[ ["Hello", "world", "!"], ["How", "are", "you", "doing", "today"], ["The", "weather", "will", "be", "nice", "tomorrow"], ]
进行embedding查询后,数据可能会被向量化为整数,例如:
[ [71, 1331, 4231] [73, 8, 3215, 55, 927], [83, 91, 1, 645, 1253, 927], ]
此数据是一个嵌套列表,其中各个样本的长度分别为 3、5 和 6。由于深度学习模型的输入数据必须为单一张量(例如在此例中形状为 (batch_size, 6, vocab_size)),短于最长条目的样本需要用占位符值进行填充(或者,也可以在填充短样本前截断长样本)。
Keras 提供了一个效用函数来截断和填充 Python 列表,使其具有相同长度:tf.keras.preprocessing.sequence.pad_sequences。
raw_inputs = [
[711, 632, 71],
[73, 8, 3215, 55, 927],
[83, 91, 1, 645, 1253, 927],
]
padded_inputs = tf.keras.preprocessing.sequence.pad_sequences(
raw_inputs, padding="post"
)
print(padded_inputs)
[[ 711 632 71 0 0 0]
[ 73 8 3215 55 927 0]
[ 83 91 1 645 1253 927]]
3. 遮盖(masking )
既然所有样本现在都具有了统一长度,那就必须告知模型,数据的某些部分实际上是填充,应该忽略。这种机制就是遮盖。
在 Keras 模型中引入输入掩码有三种方式:
3.1 添加一个 keras.layers.Masking 层。
import tensorflow as tf
import tensorflow.keras.layers as layers
raw_inputs = [
[711, 632, 71],
[73, 8, 3215, 55, 927],
[83, 91, 1, 645, 1253, 927],
]
inputs = tf.keras.preprocessing.sequence.pad_sequences(
raw_inputs, padding="post"
)
masking_layer = layers.Masking()
# Simulate the embedding lookup by expanding the 2D input to 3D,
# with embedding dimension of 10.
unmasked_embedding = tf.cast(
tf.tile(tf.expand_dims(inputs, axis=-1), [1, 1, 10]), tf.float32
)
masked_embedding = masking_layer(unmasked_embedding)
print(masked_embedding._keras_mask)
tf.Tensor(
[[ True True True False False False]
[ True True True True True False]
[ True True True True True True]], shape=(3, 6), dtype=bool)
3.2 使用 mask_zero=True 配置一个 keras.layers.Embedding 层。
import tensorflow as tf
import tensorflow.keras.layers as layers
raw_inputs = [
[711, 632, 71],
[73, 8, 3215, 55, 927],
[83, 91, 1, 645, 1253, 927],
]
inputs = tf.keras.preprocessing.sequence.pad_sequences(
raw_inputs, padding="post"
)
embedding = layers.Embedding(input_dim=5000, output_dim=16, mask_zero=True)
masked_output = embedding(inputs)
print(masked_output._keras_mask)
tf.Tensor(
[[ True True True False False False]
[ True True True True True False]
[ True True True True True True]], shape=(3, 6), dtype=bool)
3.3. 在调用支持 mask 参数的层(如 RNN 层)时,手动传递此参数。
import tensorflow as tf
import tensorflow.keras.layers as layers
raw_inputs = [
[711, 632, 71],
[73, 8, 3215, 55, 927],
[83, 91, 1, 645, 1253, 927],
]
inputs = tf.keras.preprocessing.sequence.pad_sequences(
raw_inputs, padding="post"
)
class MyLayer(layers.Layer):
def __init__(self, **kwargs):
super(MyLayer, self).__init__(**kwargs)
self.embedding = layers.Embedding(input_dim=5000, output_dim=16, mask_zero=True)
self.lstm = layers.LSTM(4, return_sequences=True)
def call(self, inputs):
x = self.embedding(inputs)
# Note that you could also prepare a `mask` tensor manually.
# It only needs to be a boolean tensor
# with the right shape, i.e. (batch_size, timesteps).
mask = self.embedding.compute_mask(inputs)
output = self.lstm(x,mask=mask) # The layer will ignore the masked values
return output
layer = MyLayer()
print(layer(inputs))
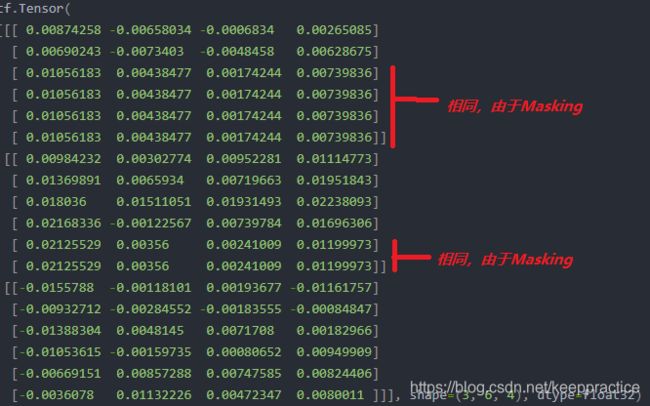
其实上面的代码你完全可以不要自己调用 上一层的compute_mask()得到mask传递给LSTM, 因为你如果在Embedding里设置了mask_zero=True. 那么LSTM会自动调用compute_mask方法的。只是有些深度网络或激活函数没有实现,如果这样的话你只能自己获取mask了。
import tensorflow as tf
import tensorflow.keras.layers as layers
raw_inputs = [
[711, 632, 71],
[73, 8, 3215, 55, 927],
[83, 91, 1, 645, 1253, 927],
]
inputs = tf.keras.preprocessing.sequence.pad_sequences(
raw_inputs, padding="post"
)
print(inputs)
x = layers.Embedding(input_dim=5000, output_dim=5, mask_zero=True)(inputs)
x = tf.nn.relu(x)
x = layers.LSTM(4, return_sequences=True)(x)
print(x)
tf.Tensor(
[[[-0.00853076 -0.0027577 0.00382648 -0.00217819]
[-0.00701238 -0.00343913 0.0032082 -0.0011041 ]
[-0.00747839 -0.00233405 0.00432012 -0.00373881]
[-0.0137679 -0.00557745 0.00911791 -0.00396027]
[-0.01824936 -0.00863818 0.01233672 -0.00297129]
[-0.02145157 -0.01128308 0.01439027 -0.00143419]]
[[-0.0079427 -0.00146676 0.00085193 -0.00298749]
[-0.01137889 -0.00377863 0.00144354 -0.00350932]
[-0.0115746 -0.00302937 -0.00108732 -0.001251 ]
[-0.01822513 -0.00597077 -0.00068765 0.00095661]
[-0.02203784 -0.00890452 0.00246888 0.00270562]
[-0.02512554 -0.01110168 0.00644199 0.00187145]]
[[ 0. 0. 0. 0. ]
[-0.0061018 -0.00086632 -0.00171513 -0.0001184 ]
[-0.01114718 -0.00349189 0.00514382 -0.00568866]
[-0.01592513 -0.00512891 0.00192113 0.00023104]
[-0.01553659 -0.00651678 0.00391222 -0.00226363]
[-0.01969725 -0.00938978 0.00616115 0.00070853]]], shape=(3, 6, 4), dtype=float32)
可以看到masking经过Relu后失效了。没有吗mask传递到lstm层
所以要做一定的修改,此处有两种方法,
方法一
封装Relu方法,设置属性supports_masking=True, 代码如下:
class MyActivation(keras.layers.Layer):
def __init__(self, **kwargs):
super(MyActivation, self).__init__(**kwargs)
# Signal that the layer is safe for mask propagation
self.supports_masking = True
def call(self, inputs):
return tf.nn.relu(inputs)
方法二
利用_keras_mask方法得到embedding层的mask传递给lstm. 代码如下:
import tensorflow as tf
import tensorflow.keras.layers as layers
raw_inputs = [
[711, 632, 71],
[73, 8, 3215, 55, 927],
[83, 91, 1, 645, 1253, 927],
]
inputs = tf.keras.preprocessing.sequence.pad_sequences(
raw_inputs, padding="post"
)
print(inputs)
x = layers.Embedding(input_dim=5000, output_dim=5, mask_zero=True)(inputs)
mask = x._keras_mask
x = tf.nn.relu(x)
x = layers.LSTM(4, return_sequences=True)(x, mask=mask)
print(x)
tf.Tensor(
[[[-1.11592971e-02 1.13475965e-02 1.22134504e-03 4.27628960e-03]
[-1.17472848e-02 1.37128066e-02 3.33235669e-03 4.49653203e-03]
[-1.18236477e-02 1.50292199e-02 -1.04225962e-03 6.14795834e-03]
[-1.18236477e-02 1.50292199e-02 -1.04225962e-03 6.14795834e-03]
[-1.18236477e-02 1.50292199e-02 -1.04225962e-03 6.14795834e-03]
[-1.18236477e-02 1.50292199e-02 -1.04225962e-03 6.14795834e-03]]
[[-3.03814257e-03 3.01474496e-03 -2.19832035e-03 1.65364845e-03]
[-3.02985404e-03 -2.74110964e-04 -8.03735293e-03 7.56251905e-03]
[-4.05789400e-03 6.13932591e-03 -7.65458029e-03 9.17674601e-03]
[-1.01635903e-02 1.46681387e-02 -2.00540805e-03 1.00620193e-02]
[-9.56059992e-03 1.74404141e-02 -2.37406185e-03 1.30043132e-02]
[-9.56059992e-03 1.74404141e-02 -2.37406185e-03 1.30043132e-02]]
4 编写需要掩码信息的层
有些层是掩码使用者:他们会在 call 中接受 mask 参数,并使用该参数来决定是否跳过某些时间步骤。
要编写这样的层,您只需在 call 签名中添加一个 mask=None 参数。与输入关联的掩码只要可用就会被传递到您的层。
下面是一个简单示例:示例中的层在输入序列的时间维度(轴 1)上计算 Softmax,同时丢弃遮盖的时间步骤。
class TemporalSoftmax(keras.layers.Layer):
def call(self, inputs, mask=None):
broadcast_float_mask = tf.expand_dims(tf.cast(mask, "float32"), -1)
inputs_exp = tf.exp(inputs) * broadcast_float_mask
inputs_sum = tf.reduce_sum(inputs * broadcast_float_mask, axis=1, keepdims=True)
returcn inputs_exp / inputs_sum
inputs = keras.Input(shape=(None,), dtype="int32")
x = layers.Embedding(input_dim=10, output_dim=32, mask_zero=True)(inputs)
x = layers.Dense(1)(x)
outputs = TemporalSoftmax()(x)
model = keras.Model(inputs, outputs)
y = model(np.random.randint(0, 10, size=(32, 100)), np.random.random((32, 100, 1)))