Mega-Nerf学习笔记
Mega-NeRF:Scalable Construction of Large-Scale NeRFs for Virtual Fly-Throughs
主页:https://meganerf.cmusatyalab.org/
论文:https://meganerf.cmusatyalab.org/resources/paper.pdf
代码:https://github.com/cmusatyalab/mega-nerf
效果展示
摘要
We use neural radiance fields (NeRFs) to build interactive 3D environments from large-scale visual captures spanning buildings or even multiple city blocks collected primarily from drones. In contrast to single object scenes (on which NeRFs are traditionally evaluated), our scale poses multiple challenges including (1) the need to model thousands of images with varying lighting conditions, each of which capture only a small subset of the scene, (2) prohibitively large model capacities that make it infeasible to train on a single GPU, and (3) significant challenges for fast rendering that would enable interactive fly-throughs. To address these challenges, we begin by analyzing visibility statistics for large-scale scenes, motivating a sparse network structure where parameters are specialized to different regions of the scene. We introduce a simple geometric clustering algorithm for data parallelism that partitions training images (or rather pixels) into different NeRF submodules that can be trained in parallel. We evaluate our approach on existing datasets (Quad 6k and UrbanScene3D) as well as against our own drone footage, improving training speed by 3x and PSNR by 12%. We also evaluate recent NeRF fast renderers on top ofMega-NeRF and introduce a novel method that exploits temporal coherence. Our technique achieves a 40x speedup over conventional NeRF rendering while remaining within 0.8 db in PSNR quality, exceeding the fidelity ofexisting fast renderers.
译文:
我们使用神经辐射场 (nerf) 从大规模的视觉捕获中构建交互式3D环境,这些捕获跨越建筑物,甚至是主要从无人机收集的多个城市街区。与单个对象场景 (传统上对nerf进行评估) 相反,我们的规模提出了多个挑战,包括 (1) 需要对具有不同照明条件的数千个图像进行建模,每个图像仅捕获场景的一小部分,(2) 令人望而却步的大模型容量,使其无法在单个GPU上进行训练,并且 (3) 快速渲染将实现交互式飞行的重大挑战。为了解决这些挑战,我们首先分析大规模场景的可见性统计信息,从而激发稀疏的网络结构,其中参数专门用于场景的不同区域。我们介绍了一种用于数据并行性的简单几何聚类算法,该算法将训练图像 (或更确切地说是像素) 划分为可以并行训练的不同NeRF子模块。我们在现有数据集 (Quad 6k和UrbanScene3D) 以及我们自己的无人机镜头上评估我们的方法,将训练速度提高3倍,将PSNR提高12%。我们还在mega-NeRF之上评估了最近的NeRF快速渲染器,并介绍了一种利用时间一致性的新颖方法。我们的技术比传统的NeRF渲染实现了40倍的加速,同时保持在0.8 db以内的PSNR质量,超过了现有快速渲染器的保真度。
IDEA
- 关键见解是将训练像素几何划分为与每个子模块相关的小数据分片,这对于有效的训练和高精度至关重要。
- Mega-NeRF采用了前景/背景划分,我们进一步限制了前景和采样范围。
- Mega-NeRF利用几何可见性推理来分解训练像素的集合,从而允许从遥远的相机捕获的像素仍然影响空间单元,如下图:

Related Works
-
Fast rendering
- Plenotree [45],SNeRG [13] 和FastNeRF [12];
- 优化:
- 将预先计算的非视图相关模型输出存储到单独的数据结构;
- 单独的较小的多层感知器 (MLP) 或通过球形基计算来计算最终的与视图相关的辐射度;
- 难题
- 缓存结构的有限容量;
- 难以大规模捕获低级细节;
- 优化:
- DeRF 通过空间Voronoi分区将场景分解为多个单元,每个单元格都使用较小的MLP独立渲染(较nerf快3倍);
- KiloNeRF 将场景分为数千个甚至更小的网络;
- DONeRF 显着减少每条射线查询的样本数量来加速渲染,但采样基本在物体表面;
- Plenotree [45],SNeRG [13] 和FastNeRF [12];
-
Unbounded scenes
- NeRF [48] 通过将空间划分为包含所有相机姿势的单位球体前景区域和覆盖倒置球体补体的背景区域来处理无界环境 ;
- NeRF in the Wild [21] 通过额外的瞬态和外观作为输入强化渲染效果,更好地解释图像之间的照明差异和瞬态遮挡;
- Urban Radiance Fields [30] (URF),CityNeRF [43] 、和BlockNeRF [34] ;
- 以城市规模的环境为目标
- URF的输入为激光雷达
- CityNeRF用多尺度数据建模
-
Training speed
- 合并从类似数据集中学到的先验知识
- PixelNeRF [46] 、IBRNet [40] 和GRF [38]通过预测图像特征影响NeRF
- Tancik et al. [35]使用meta-learning初始化良好的权重,加速收敛
-
Graphics
-
Large-scale SfM
Method
3.1 模型架构
3.2 训练过程
3.3 时间相干性的新颖渲染器
Model Architecture
NeRF
NeRF模型以其基本形式将三维场景表示为由神经网络近似的辐射场。辐射场描述了场景中每个点和每个观看方向的颜色和体积密度。这写为:
F ( x , θ , φ ) → ( c , σ ) , ( 1 ) F\left( x,\theta ,\varphi \right) →\left( c,\sigma \right) ,(1) F(x,θ,φ)→(c,σ),(1)
其中 x = ( x , y , z ) x = (x,y,z) x=(x,y,z) 是场景内坐标, ( θ , φ ) (θ,φ) (θ,φ) 表示方位角和极视角, c = ( r , g , b ) c = (r,g,b) c=(r,g,b) 表示颜色, σ σ σ表示体积密度。该5D函数由一个或多个多层预加速器 (MLP) 近似,有时表示为f Θ。两个视角 ( θ , φ ) (θ,φ) (θ,φ)通常由 d = ( d x , d y , d z ) d = (dx,dy,dz) d=(dx,dy,dz)表示,这是一个3D笛卡尔单位向量。通过将 σ σ σ (体积密度 (即场景的内容) 的预测限制为与观看方向无关),该神经网络表示被约束为多视图一致,而允许颜色 c c c取决于观看方向和场景内坐标。在基线NeRF模型中,这是通过将MLP设计为两个阶段来实现的。
第一阶段作为输入 x x x并输出 σ σ σ 和高维特征向量 (在原始论文中256)。在第二阶段,特征向量然后与观看方向 d d d连接,并传递给额外的MLP,该MLP输出 c c c。我们注意到Mildenhall等人 [1] 认为 σ σ σ MLP和 c c c MLP是同一神经网络的两个分支,但是许多后来的作者认为它们是两个独立的MLP网络,这是我们从这一点开始遵循的惯例。从广义上讲,使用经过训练的NeRF模型进行的新颖视图合成如下。
- 对于正在合成的图像中的每个像素,通过场景发送相机光线并生成一组采样点 (参见图1中的 (a))。
- 对于每个采样点,使用观看方向和采样位置来提取局部颜色和密度,由NeRF MLP(s) 计算 (参见图1中的 (b))。
- 使用体绘制从这些颜色和密度产生图像 (参见图1中的 (c ))。
更详细地说,给定体积密度和颜色函数,使用体积渲染来获得任何相机射线 r ( t ) = o + t d r(t) = o+td r(t)=o+td的颜色 C ( r ) C(r) C(r),相机位置 o o o和观看方向 d d d使用
C ( r ) = ∫ t 1 t 2 T ( t ) ⋅ σ ( r ( t ) ) ⋅ c ( r ( t ) , d ) ⋅ d t , ( 2 ) C(r)=\int_{t_1}^{t_2}{T(t)·\sigma(r(t))·c(r(t),d)·dt},(2) C(r)=∫t1t2T(t)⋅σ(r(t))⋅c(r(t),d)⋅dt,(2)
其中 T ( t ) T(t) T(t) 是累积透射率,表示光线从 t 1 t_1 t1传播到 t t t而不被拦截的概率,由
T ( t ) = e − ∫ t t 1 σ ( r ( u ) ) ⋅ d u , ( 3 ) T(t)=e^{-\int_{t}^{t_1}{\sigma (r(u))·du}},(3) T(t)=e−∫tt1σ(r(u))⋅du,(3)
C ( r ) C(r) C(r)通过待合成图像的每个像素。这个积分可以用数值计算。最初的实现 [1] 和大多数后续方法使用了非确定性分层抽样方法,将射线分成 N N N个等间距的仓,并从每个仓中均匀抽取一个样本。然后,等式 (2) 可以近似为
C ^ ( r ) = ∑ i = 1 N α i T i c i , w h e r e T i = e − ∑ j = 1 i − 1 σ j δ j , ( 4 ) \hat{C}\left( r \right) =\sum_{i=1}^N{\alpha _iT_ic_i}\,,\,where\quad T_i=e^{-\sum_{j=1}^{i-1}{\sigma _j\delta _j}},(4) C^(r)=i=1∑NαiTici,whereTi=e−∑j=1i−1σjδj,(4)
δ i \delta _i δi是从样本 i i i到样本 i + 1 i+1 i+1的距离。 ( σ i , c i ) (\sigma_i,c_i) (σi,ci)是根据NeRF MLP(s) 计算的在给定射线的采样点 i i i上评估的密度和颜色。 α i α_i αi在采样点 i i i处合成 a l p h a alpha alpha的透明度/不透明度由
α i = 1 − e σ i δ i , ( 5 ) \alpha_i = 1-e^{\sigma_i\delta_i},(5) αi=1−eσiδi,(5)
可以使用累积的透射率计算射线的预期深度为
d ( r ) = ∫ t 1 t 2 T ( t ) ⋅ σ ( r ( t ) ) ⋅ t ⋅ d t , ( 6 ) d(r)=\int_{t_1}^{t_2}{T(t)·\sigma(r(t))·t·dt},(6) d(r)=∫t1t2T(t)⋅σ(r(t))⋅t⋅dt,(6)
这可以近似于方程 (4) 近似方程 (2) 和 (3)
D ^ ( r ) = ∑ i = 1 N α i t i T i , ( 7 ) \hat{D}(r) = \sum_{i=1}^{N}{\alpha_it_iT_i},(7) D^(r)=i=1∑NαitiTi,(7)
某些深度正则化方法使用预期的深度来将密度限制为场景表面的类似delta的函数,或增强深度平滑度。
对于每个像素,使用平方误差光度损失来优化MLP参数。在整个图像上,这是由
L = ∑ r ∈ R ∣ ∣ C ^ ( r ) − C g t ( r ) ∣ ∣ 2 2 , ( 8 ) L = \sum_{r\in R}{|| \hat{C}(r)-C_{gt}(r)||_2^2},(8) L=r∈R∑∣∣C^(r)−Cgt(r)∣∣22,(8)
其中, C g t ( r ) C_{gt}(r) Cgt(r) 是与 r r r相关联的训练图像的像素的地面真实颜色, R R R是与待合成图像相关联的射线批次。
Spatial partitioning
Mega-NeRF将场景分解为具有质点 n ∈ N = ( n x , n y , n z ) n _{\in N} = (n_x,n_y,n_z) n∈N=(nx,ny,nz)的单元,并初始化相应的模型权重 f n f^n fn。每个权重子模块是类似于NeRF体系结构的一系列完全连接的层。与wild [21] 中的NeRF相似,我们为用于计算辐射度的每个输入图像a关联了一个附加的外观嵌入向量 l ( a ) l^{(a)} l(a) 。这允许Mega-NeRF在解释图像之间的照明差异方面具有额外的灵活性,我们发现这些差异在我们覆盖的场景的规模上很重要。在查询时,MegaNeRF使用最接近查询点的模型权重 f n f^n fn对给定位置 x x x,方向d和外观嵌入 l ( a ) l^{(a)} l(a) 产生不透明度 σ \sigma σ和颜色 c = ( r , g , b ) c = (r,g,b) c=(r,g,b):
f n = σ , ( 1 ) f n ( x , d , l ( a ) ) = c , ( 2 ) w h e r e n = arg min n ∈ N ∣ ∣ n − x ∣ ∣ 2 , ( 3 ) f^n = \sigma,(1)\\ f^n(x,d,l^{(a)}) = c,(2)\\ where n = \argmin_{n _{\in N}} ||n-x||^2,(3) fn=σ,(1)fn(x,d,l(a))=c,(2)wheren=n∈Nargmin∣∣n−x∣∣2,(3)
Centroid selection
最终发现将场景镶嵌到自上而下的2D网格中实际上效果很好。此方法易于实现,需要最少的预处理,并且可以在推理时将点查询有效地分配给质心。由于场景中相机姿势之间的高度差异相对于纬度和经度的差异较小,因此我们将质心的高度固定为相同的值。
Foreground and background decomposition
与NeRF++ [48] 类似,我们进一步将场景细分为包含所有相机姿势的前景卷和覆盖互补区域的背景。这两个卷都使用单独的Mega-NeRFs建模。我们使用与NeRF++相同的4D外部体积参数化和射线投射公式,但是通过使用更紧密地包围相机姿势和相关前景细节的椭球来改进其单位球体划分。我们还利用摄像机高度测量的优势,通过在地面附近终止光线来进一步完善场景的采样范围。因此,Mega-NeRF避免了不必要地查询地下区域和样本的效率更高。下图说明了两种方法之间的差异:

Ray Bounds:NeRF++ (左) 在一个以所有相机姿势为中心的单位球体内采样,以渲染其前景分量,并使用不同的方法对外部体积进行补充,以有效地渲染背景。Mega-NeRF (右) 使用类似的背景参数化,但将前景建模为椭球体,以在感兴趣的区域上实现更严格的界限。它还使用相机高度测量来限制射线采样,而不查询地下区域。
Training
Spatial Data Parallelism
由于每个Mega-NeRF子模块都是一个独立的MLP,因此我们可以并行训练每个模块,而无需模块间通信。至关重要的是,由于每个图像仅捕获场景的一小部分 (下表所示),因此我们将每个子模块的训练集的大小限制为仅那些潜在相关的像素。
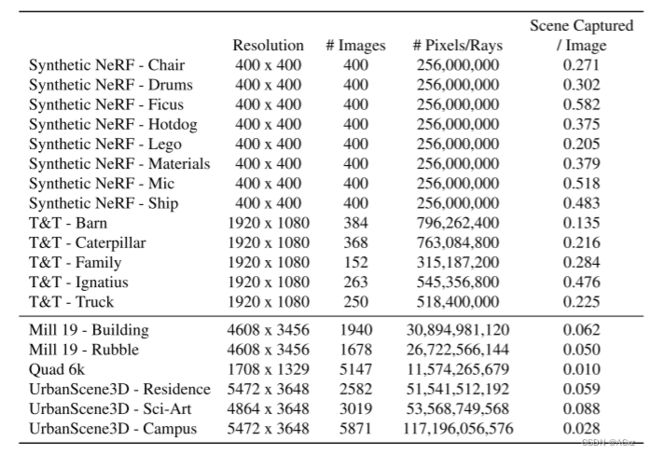
与我们的目标数据集相比,来自常用的合成NeRF和Tanks和Temples数据集 (T & T) 的场景属性 (下)。我们的目标包含的像素 (以及光线) 比以前的工作多了一个数量级。而且,每个图像捕获的场景明显更少,这激发了一种模块化方法,其中使用一小部分相关图像数据来训练空间本地化的子模块。我们在Sec中提供更多详细信息和其他统计数据。补充的H。
具体地,我们对每个训练图像沿着对应于每个像素的相机射线采样点,并将该像素添加到仅用于其相交的那些空间单元的训练集中 (图1)。在我们的实验中,与初始聚合训练集相比,这种可见性分区将每个子模块的训练集的大小减小了10倍。对于较大规模的场景,这种数据减少应该更加极端; 在为North Pittsburgh训练NeRF时,无需添加South Pittsburgh的像素。我们在细胞之间包括一个小的重叠因子 (在我们的实验中15%),以进一步最小化边界附近的视觉伪影。
Spatial Data Pruning
像素到空间单元的初始分配基于相机位置,而与场景几何形状无关 (因为在初始化时未知)。一旦NeRF对场景有了粗略的了解,就可以进一步修剪掉由于介入的封堵器而对特定NeRF没有贡献的不相关像素或者光线。例如,在图1中,早期的NeRF优化可推断单元F中的边界,这意味着来自图像2的像素可随后从单元A和B修剪。我们最初的探索发现,这种额外的可见性修剪进一步将训练数据集的大小减少了2倍。
Interactive Rendering
Caching
大多数现有的快速NeRF渲染器都利用缓存的预计算来加快渲染速度,这在我们的场景规模下可能无效。例如,plenotree [45] 将不透明度和球谐系数的缓存预先计算为稀疏体素八叉树。为我们的场景生成整个8级八叉树需要一个小时的计算,并且根据辐射格式的不同,内存从1到12 GB不等。添加一个额外的级别将处理时间增加到10小时,八叉树大小增加到55gb,超出了除最大gpu以外的所有gpu的容量。
Temporal coherence
我们探索利用交互式飞越的时间相干性的正交方向; 一旦计算出呈现给定视图所需的信息,我们将其大部分用于下一个视图。与plenotree类似,我们首先预先计算不透明度和颜色的粗略缓存。与plenotree相反,我们在整个交互式可视化过程中对树进行了动态细分。图4说明了我们的方法:
Mega-NeRF-Dynamic。当前的渲染器 (如plenotree [45]) 将预先计算的模型输出缓存到固定的八叉树中,从而限制了渲染图像的分辨率 (a)。Mega-NeRF-Dynamic根据飞穿 (b) 的当前位置动态扩展八叉树。由于相机视图的时间相干性,下一帧渲染 © 可以重用大部分扩展的八叉树。
当摄像机遍历场景时,我们的渲染器使用缓存的输出快速生成初始视图,然后执行额外的模型采样以进一步细化图像,将这些新值存储到缓存中。由于每个后续帧都与其前身有显著的重叠,因此它受益于先前的细化,并且只需要执行少量的增量工作即可保持质量。
Guided sampling
在完善八叉树之后,我们进行了最后一轮引导射线采样,以进一步提高渲染质量。通过使用八叉树结构中存储的权重,与NeRF的传统两阶段层次结构采样相反,我们可以通过一次渲染光线。由于我们改进的八叉树为我们提供了对场景几何形状的高质量估计,因此我们只需要在感兴趣的表面附近放置少量样本。图5说明了两种方法之间的区别:
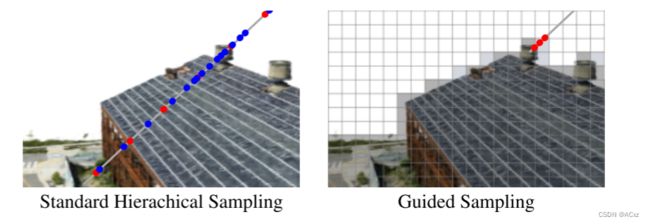
引导采样。标准NeRF (左) 首先沿射线以均匀的间隔粗略采样,然后在粗权重的指导下执行另一轮采样。Mega-NeRF-Dynamic (右) 使用其缓存结构跳过空白空间,并在表面附近获取少量样本。
与其他快速渲染器类似,我们通过沿射线累积透射率并在一定阈值后结束采样来进一步加速该过程。
效果对比
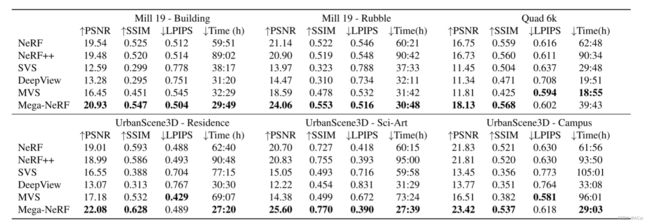
在运行每种方法完成后,我们将 Mega-NeRF 与 NeRF、NeRF++、稳定视图合成 (SVS)、DeepView 和多视图立体 (MVS) 进行比较。 即使在允许其他方法训练超过 24 小时之后,Mega-NeRF 也始终优于基线。
Supplemental Materials
Data Pruning
像素到空间单元的初始分配是基于相机位置的,而与场景几何无关(因为在初始化时不知道)。然而,秒。 3.2 指出可以用额外的 3D 知识重新划分我们的训练集。直观地说,可以修剪掉由于中间遮挡物而对特定 NeRF 子模块没有贡献的不相关像素/射线分配,如图:

像素到单元格的初始分配纯粹基于相机位置。我们将每个像素添加到它遍历的所有单元格的训练集中,从而导致集合之间的重叠 (顶部)。在模型获得对场景的3D理解之后,我们可以通过基于与实体表面 (底部) 的相机射线相交来分配像素来过滤不相关的像素。
为了探索这种优化,我们在模型获得对场景的粗略 3D 理解(在我们的实验中进行了 100,000 次迭代)之后,在训练过程的早期进一步修剪每个数据分区。由于在我们的规模上使用传统的 NeRF 渲染直接查询深度信息是令人望而却步的,因此我们从 Plenoctree 中汲取灵感,并将场景的模型不透明度值制表到一个固定的分辨率结构中。然后,我们计算每个训练像素的相机光线与结构内表面的交集,以生成新的分配。我们发现计算模型密度值大约需要 10 分钟,每张图像需要 500 毫秒来生成新的分配。我们在表 5 中总结了我们的发现。

像素对空间单元的初始分配纯粹基于从相机中心发出的光线,而与场景几何形状无关。但是,一旦训练了粗略的Mega-NeRF,就可以使用场景几何形状的粗略估计来修剪不相关的像素分配。这样做将每个子模块的训练数据量减少高达2倍,同时针对固定数量的500,000迭代增加准确性。
Dynamic objects
我们没有明确地解决工作中的动态场景,这是许多以人为中心的用例的相关因素。最近的一些与NeRF相关的工作,包括NR-NeRF [37],Nerfies [26],NeRFlow [5] 和DynamicMVS [11] 都集中在动态上,但是我们认为将这些方法扩展到更大的城市场景将需要额外的工作。