Reverse Attention-Based Residual Network for Salient Object Detection论文解读以及代码复现时所遇问题
论文原文下载:原文
代码下载:源代码
该博客只是在学习本篇论文时自己所遇问题以及一些心得,如有侵权,请联系本人删除即可。
该论文主要针对的是SOD遇到的一些问题,如:模型架构复杂、模型参数较多的问题,作者提出了一种框架即:Reverse Attention-Based Residual Network。
前述部分作者讲的很仔细,我就不多赘述,只进行模型的讲解。
Initial Saliency Prediction
首先经过VGG-16进行处理,因为VGG16独特的网络框架,具有五个最大池化层,因此在每个池化层处引出五个不同尺寸大小的侧输出。论文将最后一个池化层的输出称为initial saliency,作者首先对initial saliency进行处理:通过一个1*1的卷积层将输出将成维度为64的输出。并且设计了一个多尺度上下文模块(MSCM)用来捕获全局显著性线索。MSCM分为两部分:一是(2b-1)x(2b-1)尺寸的卷积核进行卷积,另一个是核尺寸为3x3输出为2(b-1)的卷积核进行卷积。最后将四个分支进行融合,并通过一个3x3的卷积生成单通道的输出预测,生成结果只有输入图片的1/32.
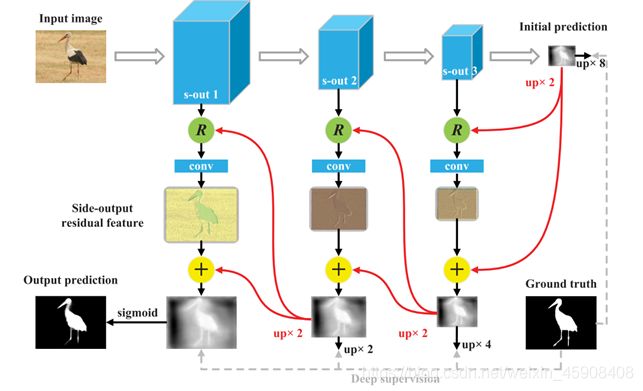
Side-Output Residual Learning
本文采用的是通过残差学习纠正每一个预测结果核真实值之间的错误作为侧输出残差学习,并且对残差学习的单元的输入和输出都使用深度监督,深度监督的方法在形式上是对i+1阶的侧输出上采样到两倍大小,计算方法为:
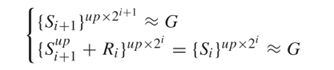
其中Si 和G表示i阶侧输出的残差单元输出,G表示真实值。残差单元建立在每一级的预测和真实值预测之间,它能以更高的适应性去纠正它们之间的错误。在它们之间应用残差块可以降低参数和迭代次数。残差特征可以通过64个通道的3*3卷积核的卷积模块进行学习。值得一提的是,残差学习特征包含政府两个反应值,因此错误和丢失的部分可以通过将其加入到initial prediction中进行优化。
Top-Down Reverse Attention
反向关注块通过擦除每个侧面输出特征中的当前预测区域来引导整个网络顺序发现互补对象区域和细节,其中当前预测是从其相邻的更深层上采样的。
获得侧输出特征T和反向注意权重A,然后注意输出的计算方式为逐像素相乘:
![]()
其中Z和C表示卷积特征的空间位置和通道数。
I阶的侧输出反向注意权重是通过以下方式计算:
![]()
Deep Supervision
用l作为侧输出的定义:
表示每一级侧输出的loss

M个侧输出的loss
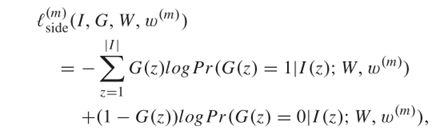
表示为m个侧输出在位置z的可能性。
代码部分:
在自己电脑或者环境上测试和训练时所需要修改的部分:
cfg = Dataset.Config(datapath='D:/date set/saliency_train/DUTS/DUTS-TR/', savepath='./models', mode='train', batch=2, lr=0.05, momen=0.9, decay=5e-4, epoch=32)
data = Dataset.Data(cfg)
loader = DataLoader(data, collate_fn=data.collate, batch_size=cfg.batch, shuffle=True, num_workers=2)
def initialize(self):
# res50 = 'D:/date set/resnet50_caffe.pth'
res50 = models.resnet50(pretrained=False)
self.load_state_dict(torch.load('D:/date set/resnet50_caffe.pth'))
image_path = self.cfg.datapath+'/DUTS-TR-Image/'
self.images = [image_path + f for f in os.listdir(image_path) if f.endswith('.jpg')]
if self.cfg.mode=='train':
mask_path = self.cfg.datapath+'/DUTS-TR-Mask/'
self.masks = [mask_path + f for f in os.listdir(mask_path) if f.endswith('.png')]
将上述三个部分的路径改为自己文件或者数据集的路径即可。
其次,文中所需要一个apex包,这个包暂时只有Linux和ubentu版本的,windows版本下载后并不能用,这个包可以去GitHub自行下载apex的下载路径。
还有代码中所需要的预训练模型可以在网上找到下载下来,并不需要每次都去下载。可以参考该作者的博客去调试下载预训练模型的链接
将上述修改完成后代码基本就跑通一大半了,但是他会进行一个警告和一个报错,如以下问题:
Traceback (most recent call last):
File "D:/document/一区/RAS-pytorch-master/v2/train.py", line 76, in
train(data, RAS)
File "D:/document/一区/RAS-pytorch-master/v2/train.py", line 48, in train
for step, (image, mask) in enumerate(loader):
File "D:\anconda\envs\python37\lib\site-packages\torch\utils\data\dataloader.py", line 279, in __iter__
return _MultiProcessingDataLoaderIter(self)
File "D:\anconda\envs\python37\lib\site-packages\torch\utils\data\dataloader.py", line 719, in __init__
w.start()
File "D:\anconda\envs\python37\lib\multiprocessing\process.py", line 112, in start
self._popen = self._Popen(self)
File "D:\anconda\envs\python37\lib\multiprocessing\context.py", line 223, in _Popen
return _default_context.get_context().Process._Popen(process_obj)
File "D:\anconda\envs\python37\lib\multiprocessing\context.py", line 322, in _Popen
return Popen(process_obj)
File "D:\anconda\envs\python37\lib\multiprocessing\popen_spawn_win32.py", line 89, in __init__
reduction.dump(process_obj, to_child)
File "D:\anconda\envs\python37\lib\multiprocessing\reduction.py", line 60, in dump
ForkingPickler(file, protocol).dump(obj)
TypeError: 'NoneType' object is not callable
其中警告时因为apex文件没起作用,但是该文件对于代码的运行并不会起阻碍作用,所以只是警告,而代码报错的原因是因为:
for step, (image, mask) in enumerate(loader):
image, mask = image.cuda().float(), mask.cuda().float()
out2, out3, out4, out5 = net(image)
此处代码进行遍历的时候,因为作者默认的num_workers=2,我理解的是作者同时映入两个工作程序,类似于同时进行两个工作流程,而本人电脑只有一个GPU 所以才会出现报错。将代码中的num_workers=2修改为num_workers=0即可。
# if (epoch + 1) % 8 == 0:
torch.save(net.state_dict(), cfg.savepath+'/RAS.v2' + str(epoch+1) + '.pth')
在调试代码时建议将此部分代码修改为如上,方便调试。