(十七:2020.09.10)nnUNet最全问题收录(9.10更新)
来这里寻找你的答案!
- 一、写在前面
- 二、GITHUB ISSUE
-
- I. 使用上的问题:
-
- #477 《3D nnUNet支持FP16量化吗?》
- #474 《ImportError: cannot import name find_namespace_packages》
- #471 《我怎么在本地评估一些预训练模型的指标呢?》
- #469 《无任何报错的进程死亡》
- #464 《如何对PET进行归一化》
- #459 《`orientation`这个属性在nnUNet里起作用吗?》
- #456 《cannot import name 'SpatialTransform_2' from 'batchgenerators.transforms'》
- #454 《能给个自己编译pytorch解决2d训练问题的教程吗?》
- #449 《前景多标签有重叠情况怎么解决?》
- #446 《在用多GPU训练以后发现推理时候报错》
- #437 《在Microsoft Azure VM Instance虚拟机中存在的一个bug》
- #427 《nnUNet能不能使用cupy来加速预处理过程呢?》
- #425 《当生成的patch_size大于图像本身的时候会发生什么?》
- #424 《能直接把预处理以后的npz文件的patch抽出来在我的新模型上进行训练吗?》
- #423 《想在你的模型中添加新的网络块,应该怎么做?》
- #422 《使用find_best_configuration时npz丢失》
- #421 《cuda10.0+torch1.2可以训练吗?》
- #420 《怎么训练2D图片?》
- #417 《推理时间特别慢(32g的RAM)》
- #416 《在docker中运行nnUNet遇到错误`RuntimeError: MultiThreadedAugmenter.abort_event was set, something went wrong. Maybe one of your workers crashed. This is not the actual error message! Look further up your stdout to see what caused the error. Please also check whether your RAM was full`》
- #322 《关于修改最大轮数》
- #321 《在执行plan_preprocess的时候卡住》
- #318 《12GB的显存仍然不够的问题》
- #312 《混合精度问题(TypeError: predict_preprocessed_data_return_seg_and_softmax() got an unexpected keyword argument 'mixed_precision')》
- #311 《训练时找不到预处理文件夹》
- #310 《"Segmentation fault (core dumped)"》
- #309《"RuntimeError: CUDA error: device-side assert triggered"》<---(Non-consecutive labels within ground truth )
- #304《1000的epoch太多了,我怎么自定义一个epoch?》
- #302《训练第一个fold的时候正常,但是其他四个fold的训练损失是NaN》
- #299《五折产生五个fold,每个训练出一个模型,怎么把这五个合成一个模型呢?》
- #297《简单修改了batchsize和patchsize并不成功,目的是希望在32GB的显卡上充分利用显存》
- #296《"TypeError: consolidate_folds() got an unexpected keyword argument 'folds'"》
- #295《"AttributeError: 'list' object has no attribute 'size'"(推理时候卡住并报错)》
- #290《预测时候卡主卡了一天没有反应》
- #288《怎么使用FabiansUNet,而不是默认的generic_Unet》
- #281《关于怎么评估模型测试结果》
- #280《怎么关闭deep-supervision》
- #273《代码中的"softmax_helper"相比torch中的"torch.nn.functional.softmax"有什么优点》
- #271《怎么读取权重(找不到权重文件)》
- #270《怎么在预训练模型的基础上加入一些新的数据以提高模型泛化能力?》
- #268《训练数据有四个通道(而不是五个),最后一个通道是一个二进制的map(应该是五个通道时候的xy合并在一起的),怎么应用数据增强》
- #263《有些测试CT推理不出来,有些CT推理出来啥也没有》
- #259《同样的数据集,为什么我的训练结果没有作者论文里的效果好呢?》
- #258《关于推理速度如此之慢的问题》
- #257《nnUNet怎么对预处理好的文件进行推理》
- II. 理论上的问题:
-
- #430《一种nnUNet的改进方向》
- #470《nnUNet可以进行一些dense-connection的改进吗?》
- #303《nnUNet是怎么在做强度归一化》
- #265《关于利用crop来生成前景boundingbox的问题》
- III. 代码上的问题:
-
- #313 《AttributeError: 'NoneType' object has no attribute 'is_alive'》
- #294《"RuntimeError: unable to write to file "》
- #291 《AttributeError: 'NoneType' object has no attribute 'is_alive'》(与#313的问题一样)
- #267 《TypeError: validate() got an unexpected keyword argument 'force_separate_z'》
一、写在前面
1. 发现最近大家的问题有很多,有部分是理论上的问题。但是很多还只是框架使用上的问题,其实个人觉得整个框架就现在来说已经相当的成熟,为了有一个类似于github的issue总结的地方,我希望去写一片问题总结的博客还是具有相当大的意义,一方面处于对工作学习内容的总结,一方面有个很好的反馈问题查找答案的地方。我会慢慢更新到最开始的位置。
2. 本篇博客总结的内容包括三个来源:
- ① GITHUB:我会从github的issue界面这里进行全面的检索和内容精要的提取,主要是已经关闭的issue。按照由今至古的时间线进行,同时会将内容分为如下三类:
- I. 使用上的问题:主要是使用过程出现的问题总结;
- II. 理论上的问题: 涉及到理论的新颖知识,基本的概念或常识;
- III. 代码上的问题:算法的代码实现,以及一些可能存在的bug。
- ② 个人使用经验:总结我在使用nnUNet过程中出现的问题和解决方案。
- ③ 访客问题:总结大家向我提出的问题,只会涉及到我之前没有遇到过也没有时间常识解决且GITHUB上暂时没有提到的问题。
3. 笔者希望各位看官在方便自己工作学习的同时,也能为贡献自己的一份力,我们距离德国的医疗卫生水平还有着巨大的鸿沟式的差距,人生在世,总得留下点有价值的东西,无论出于什么目的,大家一起加油,不忘初心。
二、GITHUB ISSUE
I. 使用上的问题:
#477 《3D nnUNet支持FP16量化吗?》
- 1. 解决方法:最近的更新将会支持FP16的量化,结果是一样的,有兴趣的同学测试下速度。
#474 《ImportError: cannot import name find_namespace_packages》
- 1. 问题描述:在
pip install -e .时遇到问题。 - 2. 解决方法:先执行
pip install -U setuptools,再pip install -e .。
#471 《我怎么在本地评估一些预训练模型的指标呢?》
- 1. 解决方法:在论文的附录里有的。
#469 《无任何报错的进程死亡》
- 1. 问题描述:我正在尝试使用马萨诸塞州道路分割数据集训练2D模型。 但是,当训练过程达到第四轮,终端将显示“ killed”,而没有任何错误消息。
- 2. 解决方法:这里的
nnU-Net training (2D U-Net): High (and increasing) system RAM usage, OOM解释了这个原因。 - 3. 问题解决:
分别将CUDA和CUDNN版本更新为11.0.194和8.0.5,然后我重新编译pyTorch,它可以正常工作。 - 4. 我有话说:几个月没看nnUNet,看来已经可以进行自然场景的2D分割了 ,很多同学问过这个问题,不知道你们有没有跟进关注呢?我在这个问题发现了这个任务的数据预处理---->here,看来作者已经把脚本写好了,确实得看一下了。
#464 《如何对PET进行归一化》
- 1. 解决方法:PET图像将像其他任何非CT图像一样处理:每个样本均使用其自己的均值和标准差进行归一化。
#459 《orientation这个属性在nnUNet里起作用吗?》
- 1. 解决方法:nnUNet不考虑这个属性,你的数据集必须要保证方向一致。
#456 《cannot import name ‘SpatialTransform_2’ from ‘batchgenerators.transforms’》
- 1. 解决方法:更新下
batchgenerators或者重新安装下nnUNet。
#454 《能给个自己编译pytorch解决2d训练问题的教程吗?》
- 1. 解决方法:这里有哦!说真的,只要你编译过ffmpeg的cuda版本这都是小儿科,人都能疯。pytorch已经很友好了。
#449 《前景多标签有重叠情况怎么解决?》
- 1. 解决方法:多分类的前景标签有重叠的情况现在nnUNet尚不支持。
#446 《在用多GPU训练以后发现推理时候报错》
- 1. 问题描述:
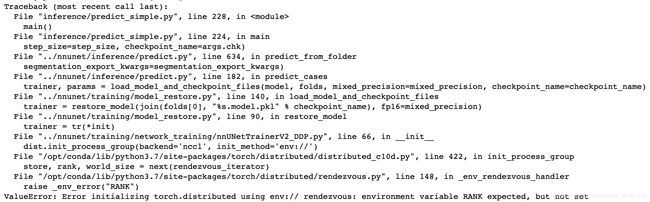
- 2. 解决方法:这是当前版本仍然存在的问题,会在未来进行改进,所以不建议去使用多gpu训练。
#437 《在Microsoft Azure VM Instance虚拟机中存在的一个bug》
- 1. 问题描述:
shutil.Error: [('/nnUnet/nnUNet_raw_data_base/nnUNet_cropped_data/Task001_Brain/gt_segmentations/BRAIN_000.nii.gz', '/nnUnet/nnUNet_preprocessed/Task001_Brain/gt_segmentations/BRAIN_000.nii.gz', "[Errno 38] Function not implemented: '/nnUnet/nnUNet_raw_data_base/nnUNet_cropped_data/Task001_Brain/gt_segmentations/BRAIN_000.nii.gz'"), . - 2. 解决方法:https://stackoverflow.com/questions/51616058/shutil-copystat-fails-inside-docker-on-azure。
#427 《nnUNet能不能使用cupy来加速预处理过程呢?》
- 1.我的理解:我对这个问题的理解应该就是它想通过加速numpy来加速skimage这个库,从而对插值进行加速。后续我会做这部分工作,因为之前我用torch的加速替代了skimage的加速,但发现因为量化或者是我插值方法的原因,速度虽然提升了,但精度损失了很多。
#425 《当生成的patch_size大于图像本身的时候会发生什么?》
- 1. 解决方法:如果patch大小大于图像,则原始图像将用零填充。这根本不与非零裁剪冲突。 这两个有不同的目的。
#424 《能直接把预处理以后的npz文件的patch抽出来在我的新模型上进行训练吗?》
- 1. 作者解释:作者认为这样可能效果并不是很好。 因为他们在nnU-Net中解决了许多与之相关的陷阱。 最好的比较是在训练时使用nnU-Net所使用的相同数据加载器(包括增强),这应该很容易从nnU-Net存储库中提取出来。如果由于某种原因不想这样做,那么使用npz也可以,但是您仍然必须报告由原始nnU-Net获得的Dice分数作为基准。
#423 《想在你的模型中添加新的网络块,应该怎么做?》
- 1. 问题描述:想把这个模块添加到nnUNet的模型当中。
- 2. 作者解释:您需要修改Generic_UNet并将自定义块添加到正确的位置。 那应该很简单。 请注意,这些块不会被用于估计GPU内存消耗,因此您可能需要超过10GB的GPU内存来训练所得模型。
#422 《使用find_best_configuration时npz丢失》
- 1. 解决方法:重新跑一下评估:
nnUNet_train CONFIG TRAINER TASK FOLD -val --npz
#421 《cuda10.0+torch1.2可以训练吗?》
- 1. 解决方法:最低要求cuda10.1,而torch的版本要用最新的。
#420 《怎么训练2D图片?》
- 1. 解决方法:很多人问我怎么使用2d图片,官方终于把这个作为一个常规武器放在了库中,这里是其解决方案,并且附带有几个相关的任务:
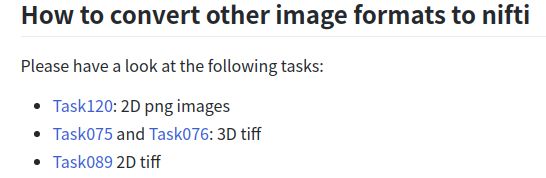
还是之前提到过的思想,将2d图片转换为伪3d nii文件,然后使用2d模式。不过现在有了官方的数据转换的脚本,省的自己写了。
#417 《推理时间特别慢(32g的RAM)》
- 1. 解决方法:对于医学图像来说这样的内存是不够的,在固态上加一个swap分区会很好的改善情况。
#416 《在docker中运行nnUNet遇到错误RuntimeError: MultiThreadedAugmenter.abort_event was set, something went wrong. Maybe one of your workers crashed. This is not the actual error message! Look further up your stdout to see what caused the error. Please also check whether your RAM was full》
- 1. 解决方法:这里是解决的方案,需要加上参数
--ipc=host。
#322 《关于修改最大轮数》
- 1. 解决方法:创建一个新的trainer来继承nnUNettrainerV2,并在初始化的时候给定最大轮数这个参数。
#321 《在执行plan_preprocess的时候卡住》
- 1. 问题原因:较小的RAM却使用默认的线程数会导致卡顿,所以要将线程数设置的少一点来进行测试其他是否正常。
- 2. 解决方法:
nnUNet_plan_and_preprocess -t 100 -tl 1 -tf 1 --verify_dataset_integrity来设置为一个线程。
#318 《12GB的显存仍然不够的问题》
- 1. 问题原因:问者在最后发现自己的显存仍有程序在占用,但是nvidia-smi并未将这部分进行显示。
- 2. 其他要点:
- I. 在使用nnUNet时,尽量把代码Update一下,同时将torch的版本进行更新;
- II. 作者建议如果要进行环境的更新安装,不怕工程大的话,将CUDA更新到CUDA11.
#312 《混合精度问题(TypeError: predict_preprocessed_data_return_seg_and_softmax() got an unexpected keyword argument ‘mixed_precision’)》
- 1. 问题原因:作者在最近将apex从框架中移除,因为torch1.6支持混合精度训练,没有及时更新出现的错误。
- 2. 解决方案:
pip install --upgrade nnunet来更新nnUNet,或者在ide中进行master的update。
#311 《训练时找不到预处理文件夹》
- 1. 问题原因:环境变量的设置问题,所以无法找到对应文件夹。
- 2. 解决方案:参考第四篇博客教程去进行环境路径的设置。
- 3. 我有话说:如果觉得这样设置不够灵活,且你的磁盘空间有限,想要灵活的设置nnUNet的路径,请按照下面导入临时环境变量:
export nnUNet_raw_data_base="/home/user/DATASET/nnUNet_raw(对应你的文件夹全路径)"
export nnUNet_preprocessed="/home/user/DATASET/nnUNet_preprocessed"(对应你的文件夹全路径)
export RESULTS_FOLDER="/home/user/DATASET/nnUNet_trained_models"(对应你的文件夹全路径)- 像之前一样执行命令,每进一次终端都要这样做一次,这是设置临时环境变量。
#310 《“Segmentation fault (core dumped)”》
- 1. 问题原因:这是个相当奇怪的问题,问者最终结论是觉得
torch 1.2.0和batchgenerators 0.20.1有冲突。 - 2. 解决方案:将torch回溯到1.2.0能解决这个问题。
- 3. 我有话说:把torch更新到1.6不香吗???
#309《“RuntimeError: CUDA error: device-side assert triggered”》<—(Non-consecutive labels within ground truth )
- 1. 问题描述:问者在尝试训练TCGA brain tumour的数据集,格式类似于 BraTS的数据集,但是按照正常的流程开始训练之后出现
RuntimeError: CUDA error: device-side assert triggered的问题。 - 2. 问题原因:对于这样格式的数据类型,作者写了一个专门的脚本来进行这个数据集的处理---->
nnunet/dataset_conversion/Task043_BraTS_2019.py,需要先运行这个脚本继续训练。 - 3. 解决方案:问者先是按照作者说的脚本处理数据,但是仍然有错误,之后他将整个之前产生的文件内容全部删除,只留下一个原始数据,重新训练后解决问题。
- 4. 其他要点:
- I. 在某些时候,如果想要重新处理数据,之前生成的crop文件夹不删除就会出现问题,尽量把这个文件夹删除掉;
- II. 对于不同的数据集处理方式可能会有所不同,对于比较主流的竞赛数据集,作者的代码中都会有对应的脚本。
#304《1000的epoch太多了,我怎么自定义一个epoch?》
- 1. 解决方案:初始化trainer时在代码里设置:
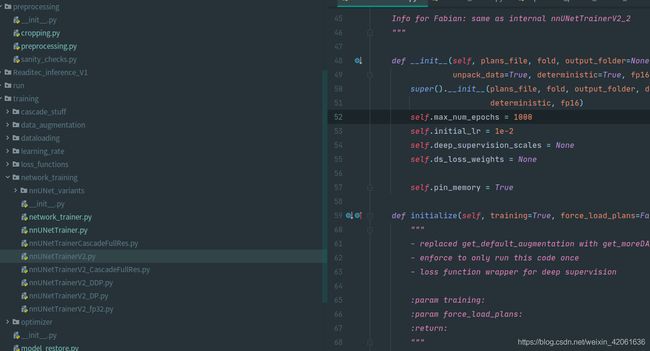
self.max_num_epochs=XXX - 3. 我有话说:找了一下位置在这里:
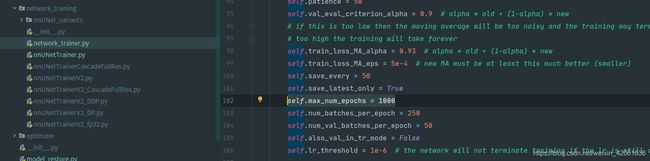
修改上面的不起作用,修改这里:
#302《训练第一个fold的时候正常,但是其他四个fold的训练损失是NaN》
- 1. 解决方案:问者的训练任务是MRI,最后发现在自己的训练集中有个图像中存在NaN值。
#299《五折产生五个fold,每个训练出一个模型,怎么把这五个合成一个模型呢?》
- 1. 作者回答:nnUNet没有这个功能,但是可以用ensemble的方式进行推理,如果是想充分利用所有数据集,就在训练时加上
all这个参数,意味着用所有的训练数据来训练,而不是用五折。但是验证的分数就没有意义,因为并没有做五折,这些验证分数实际就是你训练集的分数,而不是验证集的。
#297《简单修改了batchsize和patchsize并不成功,目的是希望在32GB的显卡上充分利用显存》
- 1. 问题描述:问者在进行迁移学习的nnUNet实践,需要修改batchsize、patchsize和网络结构(深度),于是修改了plan.pkl文件但是并未成功。报错:
RuntimeError: Sizes of tensors must match except in dimension 3. Got 7 and 8和RuntimeError: invalid argument 0: Sizes of tensors must match except in dimension 1. Got 41 and 42 in dimension 4 at /pytorch/aten/src/THC/generic/THCTensorMath.cu:71,这很明显是形状出了问题。而且希望能在32GB的显卡上充分应用显存,也就是增大patchsize。 - 2. 问题原因:直接从plan.pkl文件修改超参数会出现问题,在你不知道这些参数的具体作用时,不要修改,因为nnUNet的参数可能相互关联和影响。
- 3. 解决方案:前面的第一个问题没有给出详细的答案,至于如何增大patchsize,采用如下命令:
nnUNet_plan_and_preprocess [...] -pl2d None -pl3d ExperimentPlanner3D_v21_32GB
这个计划在代码的这个位置:

也就是说,只能通过这种方式来增加patchsize的大小,从而充分应用显存。那些有大显卡的兄弟姐妹可以来试一下了。 - 4. 我有话说:
- I. 一直没有看plan的代码,所以可能也没有深入了解为什么超参数不能乱修改;
- II. 更大的patchsize,意味着推理时更少的迭代次数,也就有可能会对推理速度有一部分加速效果,有兴趣的可以试一下,我还没测。
#296《“TypeError: consolidate_folds() got an unexpected keyword argument ‘folds’”》
- 1. 解决方案:问者采取的方法是将fold文件夹删除以后重新运行命令,从作者的回答来看更新框架可以解决问题。
#295《“AttributeError: ‘list’ object has no attribute ‘size’”(推理时候卡住并报错)》
- 1. 问题描述:问者在进行FabiansResUNet推理时遇到的错误,它运行的是
nnUNet_predict -i ./imagesTs -o ./predict_result -t 001 -tr nnUNetTrainerV2_ResencUNet -m 3d_fullres -f 0 -chk model_best - 2. 解决方案:作者稍微更新了下代码然后让问者重新拉取,这种错误应该是数据类型的问题,或者用错了api,如果还有问题可以直接在GITHUB上反馈。
- 3. 我有话说:
- I.我相信很多读者可能都想用残差网络来尝试训练一下nnUNet,我在这里给出详细的步骤:
- 第一步:更新nnUNet!!!;
- 第二步:运行一次普通的预处理,即
nnUNet_plan_and_preprocess -t 16,如果之前运行过则不需要; - 第三步:
nnUNet_plan_and_preprocess -t 16 -pl2d None; - 第四步:
nnUNet_plan_and_preprocess -t 16 -pl3d ExperimentPlanner3DFabiansResUNet_v21 -pl2d None; - 第五步:
nnUNet_train 3d_fullres nnUNetTrainerV2_ResencUNet 16 4 -p nnUNetPlans_FabiansResUNet_v2.1
- II. 我们知道,训练完成后有两个模型文件,一个是model_best,一个是model_latest,如果想在训练中用其中一个进行推理的测试,请在推理的命令后加参数
-chk model_best或者-chk model_latest。
- I.我相信很多读者可能都想用残差网络来尝试训练一下nnUNet,我在这里给出详细的步骤:
#290《预测时候卡主卡了一天没有反应》
- 1. 解决方案:因为作者用了tmux而不是我们平常使用的terminal,所以出现这个问题,切换回去普通的terminal后问题就解决了。
#288《怎么使用FabiansUNet,而不是默认的generic_Unet》
- 1. 解决方案:这里的FabiansUNet其实指的是残差网络,参考
#295中如何使用残差的步骤。
#281《关于怎么评估模型测试结果》
- 1. 我有话说:
nnUNet_find_best_configuration -m 3d_fullres -t 010 --strict
这个命令可以对你的测试集进行推理,会从fold_0到fold_4进行测试,测试不使用后处理和使用后处理的结果。
#280《怎么关闭deep-supervision》
- 1. 解决方案:
使用nnUNetTrainerV2_noDeepSupervision,替代命令中的nnUNetTrainerV2。 - 2. 关于deep-supervision这个trick:
参考这篇文章deep-supervision
#273《代码中的"softmax_helper"相比torch中的"torch.nn.functional.softmax"有什么优点》
- 1. 解决方案:
作者在做这个的时候torch还不支持多维上的softmax,现在支持了,所以之后会做改进。
#271《怎么读取权重(找不到权重文件)》
- 1. 解决方案:权重文件,也就是我们所说的.pth文件,其实是这个文件,不过是换成.model结尾的后缀而已:

#270《怎么在预训练模型的基础上加入一些新的数据以提高模型泛化能力?》
- 1. 解决方案:(这里正在询问作者解决方案)可以直接创建一个新的任务,里面存放添加的数据集,然后加载之前的模型并且训练,作者说这可能需要之前优化器的动量、学习率和轮数。
#268《训练数据有四个通道(而不是五个),最后一个通道是一个二进制的map(应该是五个通道时候的xy合并在一起的),怎么应用数据增强》
- 1. 我有话说:这个问题有点意思,不过我还是不大明白为什么会有这样的数据,我尝试问一下,解决之后更新。
#263《有些测试CT推理不出来,有些CT推理出来啥也没有》
- 1. 我有话说:出现这类问题请优先检查自己的CT,尝试换用其他的CT进行推理,正常情况不应该出现这个问题,多半是CT的问题。比如你的CT因为在转nii时操作不当导致里面的灰度值变为0-255的,那么就肯定推理不出结果。
#259《同样的数据集,为什么我的训练结果没有作者论文里的效果好呢?》
- 1. 我有话说:作者认为即使是同样的数据集,同样的代码,实验结果也会有各种各样的不同。问者认为可能和APEX的安装步骤有关,以及torch也可能有影响,这点需要诸位的实验来做下多次的验证。
#258《关于推理速度如此之慢的问题》
- 1. 我有话说:推理的时间问题在我看来主要来自于三个方面:
- ① 数据预处理的时间:预处理的时间分为crop的时间和插值的时间,所用的库都是skimage,可以说是相当的慢,层数较多的时候甚至会10min以上预处理一次。个人建议,将代码中的插值算法从ndimage换成torch的插值算法,基本在几秒内完成插值。
- ② 镜像计算的时间:也就是数据增强的时间,在3d的模式中,每次要做8次的镜像,然后每个都要推理,关闭镜像可以把这部分时间减少很多;
- ③ patch的迭代和推理时间:这是为什么推理时间那么长的根本原因,因为一个patch要0.3s左右的时间,但是一套ct上会有上百个patch,时间成本自然也就上去了。我尝试过libtorch的推理,看下时间有没有减少,发现也没有什么大的改观;尝试过tensorRT的加速,但是出现3d卷积核的问题至今没能解决。有想法的可以试一下。
#257《nnUNet怎么对预处理好的文件进行推理》
- 1. 解决方案:当前nnUNet只支持对原始nii文件进行推理,如果要用预处理好的文件进行推理,我的建议是从传入patch的位置进去,且要把你的数组合理的分成若干个满足模型推理要求的patch。
II. 理论上的问题:
#430《一种nnUNet的改进方向》
- 1. 问题描述:想把标签mask作为另一个通道加入到训练的数据中以此来指导模型。(有点意思,有谁能指引一下我这个论文?)
- 2. 作者建议:对这个方法没有什么概念所以也不知道作者说的啥意思,有兴趣的自己琢磨下。

#470《nnUNet可以进行一些dense-connection的改进吗?》
- 1. 作者建议:当你的训练结果并不如预期时,先考虑下是不是你的数据本身和你的使用方法出了问题,不要着急考虑改进网络。先看看图像方向是不是正确的,确保预处理以后的分割图像是否和原图重合。
再者,Verse的评估方法与nnUNet不同。
#303《nnUNet是怎么在做强度归一化》
- 我解释一哈:这个问题是我提出来的,因为在实际的应用中我发现模型在一些明显发灰的CT上表现很差,我希望摸清楚到底归一化在怎么做。其实是这样的:
- I. 将所有训练的数据集的所有体素的强度值进行一个统计,类似于去掉一个最低分和一个最高分的方法,把数值前0.5%和后0.5%的值去掉,只取中间部分的值,然后在剩下的值上计算均值和方差,来进行强度归一化。
- II. 代码在这里:
if scheme == "CT":
# clip to lb and ub from train data foreground and use foreground mn and sd from training data
assert self.intensityproperties is not None, "ERROR: if there is a CT then we need intensity properties"
mean_intensity = self.intensityproperties[c]['mean']
std_intensity = self.intensityproperties[c]['sd']
lower_bound = self.intensityproperties[c]['percentile_00_5']
upper_bound = self.intensityproperties[c]['percentile_99_5']
data[c] = np.clip(data[c], lower_bound, upper_bound)
data[c] = (data[c] - mean_intensity) / std_intensity
if use_nonzero_mask[c]:
data[c][seg[-1] < 0] = 0
#265《关于利用crop来生成前景boundingbox的问题》
- 1. 我有话说:这部分在ct上没有影响,主要是用在MRI图像上的。
III. 代码上的问题:
#313 《AttributeError: ‘NoneType’ object has no attribute ‘is_alive’》
- 1. 问题原因:这是最近编码时产生的bug。
- 2. 解决方案:将代码更新到最新。
- 3. 我有话说:同样遇到了这个问题,在更新完以后可以解决。
#294《“RuntimeError: unable to write to file ”》
- 1. 解决方案:这不是nnUNet的问题,是ubuntu系统的问题,具体的解决方案在这里。原因是需要修改/dev/shm大小,参考中文解决方案–>这里。
#291 《AttributeError: ‘NoneType’ object has no attribute ‘is_alive’》(与#313的问题一样)
- 2. 解决方案:删除preprocess文件夹里的所有 .npy文件,然后重新执行训练命令。
#267 《TypeError: validate() got an unexpected keyword argument ‘force_separate_z’》
- 2. 解决方案:之前版本的一个bug,已经修复。