mmdetection目标检测模型最强优化
关于mmdetection框架,根据其config文件,可以将模型分为Backbone、Neck、Bbox_head几个模块。其中:
- Backbone指的是模型的主干网络,主要用来特征提取;
- Neck主要用来做特征融合,以FPN(特征金字塔)为代表;
- Bbox_head指的是目标检测或者目标分割等任务的头部,分为分类和回归两个子任务。
本文用SwinTransformer作为Backbone,FPN作为Neck,TOOD模型作为Bbox_head,并加入一系列的模型调优策略,得到目前单GPU最优精度模型。
TOOD: Task-aligned One-stage Object Detection
针对目前模型的分类与定位任务交互少,导致预测不一致的问题,TOOD设计一个新的 head 结构来更好的将分类和定位任务对齐。
首先,任务对齐head在FPN 输出特征中进行分类和定位;
然后,采用任务对齐学习(TAL)用对齐度量参数来计算两者的对齐信号(alignment signal);
最后,在反向传播中使用对齐信号动态调整分类的得分和定位的位置,从而在预测过程中对两个任务进行对齐,为任务交互以及任务相关特征提供更好的平衡,提升模型的精度。
- 在分类头部用QualityFocalLoss代替FocalLoss作为分类损失,兼顾分类得分和质量评估得分,这样可以保证训练和测试的一致性,从而解决模型类别不均衡问题。
- 在回归头部用GIoULoss作为回归损失
- 设计了TaskAlignedAssigner进行正负样本分配
一、Backbone模块
1、SwinTransformer_small
大名鼎鼎的SwinTransformer系列特征提取网络,现有三个版本:Large、Small、Tiny。当然,用SwinTransformer_large训练的模型精度最优,但是模型太大,用实验室的单GPU跑不起来。
backbone=dict(
type='SwinTransformer',
embed_dims=96,
depths=[2, 2, 18, 2],
num_heads=[3, 6, 12, 24],
window_size=7,
mlp_ratio=4,
qkv_bias=True,
qk_scale=None,
drop_rate=0.0,
attn_drop_rate=0.0,
drop_path_rate=0.2,
patch_norm=True,
out_indices=(1, 2, 3),
with_cp=False,
convert_weights=True,
init_cfg=dict(
type='Pretrained',
checkpoint=
'https://github.com/SwinTransformer/storage/releases/download/v1.0.0/swin_small_patch4_window7_224.pth'
)),
2、SwinTransformer_large
backbone=dict(
type='SwinTransformer',
pretrain_img_size=384,
embed_dims=192,
depths=[2, 2, 18, 2],
num_heads=[6, 12, 24, 48],
window_size=12,
mlp_ratio=4,
qkv_bias=True,
qk_scale=None,
drop_rate=0.,
attn_drop_rate=0.,
drop_path_rate=0.2,
patch_norm=True,
out_indices=(1, 2, 3),
# Please only add indices that would be used
# in FPN, otherwise some parameter will not be used
with_cp=False,
convert_weights=True,
init_cfg=dict(type='Pretrained', checkpoint=pretrained)),
3、ResneXt101+DCNv2
mmdetection中最常见的高精度backbone网络,算是ResNeXt系列的顶配。
backbone=dict(
type='ResNeXt',
depth=101,
num_stages=4,
out_indices=(0, 1, 2, 3),
frozen_stages=1,
norm_cfg=dict(type='BN', requires_grad=True),
norm_eval=True,
style='pytorch',
init_cfg=dict(
type='Pretrained', checkpoint='open-mmlab://resnext101_64x4d'),
groups=64,
base_width=4,
dcn=dict(type='DCNv2', deformable_groups=1, fallback_on_stride=False),
stage_with_dcn=(False, False, True, True)),
DCN模块
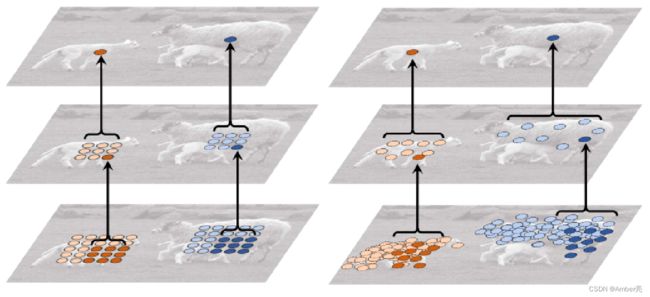
DCN能在模块中增加空间采样位置,并从目标任务中学习偏移量。
如下图分别是**标准卷积(左图)和可变形卷积(右图)**产生的感受野的采样点位置。由图可知,相比于标准卷积, 可变形卷积更能提取图像中的感兴趣区域。
二、Neck模块
Neck模块中通常用的是**FPN(特征金字塔)**及其改良版,比如:PAFPN (CVPR’2018)、NAS-FPN (CVPR’2019)、CARAFE (ICCV’2019)、FPG (ArXiv’2020)
1、SwinTransformer主干网络的FPN(SwinTransformer_small)
neck= dict(
type='FPN',
in_channels=[192, 384, 768],
out_channels=256,
start_level=0,
add_extra_convs='on_output',
num_outs=5),
2、Resnet主干网络的FPN
neck=dict(
type='FPN',
in_channels=[256, 512, 1024, 2048],
out_channels=256,
start_level=1,
add_extra_convs='on_output',
num_outs=5),
三、Bbox_head模块
Bbox_head部分有非常之多的论文进行改进,比如双阶段的FasterRCNN、Cascade模型,单阶段的ResNet、FCOS、VFNet等等。我们用的是TOOD: Task-aligned One-stage Object Detection的bbox_head架构。
bbox_head=dict(
type='TOODHead',
num_classes=6,
in_channels=256,
stacked_convs=6,
feat_channels=256,
anchor_type='anchor_free',
anchor_generator=dict(
type='AnchorGenerator',
ratios=[1.0],
octave_base_scale=8,
scales_per_octave=1,
strides=[8, 16, 32, 64, 128]),
bbox_coder=dict(
type='DeltaXYWHBBoxCoder',
target_means=[0.0, 0.0, 0.0, 0.0],
target_stds=[0.1, 0.1, 0.2, 0.2]),
initial_loss_cls=dict(
type='FocalLoss',
use_sigmoid=True,
activated=True,
gamma=2.0,
alpha=0.25,
loss_weight=1.0),
loss_cls=dict(
type='QualityFocalLoss',
use_sigmoid=True,
activated=True,
beta=2.0,
loss_weight=1.0),
loss_bbox=dict(type='GIoULoss', loss_weight=2.0),
num_dcn=2),
train_cfg=dict(
initial_epoch=4,
initial_assigner=dict(type='ATSSAssigner', topk=9),
assigner=dict(type='TaskAlignedAssigner', topk=13),
alpha=1,
beta=6,
allowed_border=-1,
pos_weight=-1,
debug=False),
test_cfg=dict(
nms_pre=1000,
min_bbox_size=0,
score_thr=0.05,
nms=dict(type='nms', iou_threshold=0.6),
max_per_img=100))
四、其他优化策略:
1、数据增强策略,包括Mixup,CutMix,RandAugment,Random Erasing等;
train=dict(
# 重复训练数据集3次
type='RepeatDataset',
times=3,
dataset=dict(
type='CocoDataset',
ann_file='data/coco_6/voc07_trainval.json',
img_prefix='data/coco_6/',
pipeline=[
dict(type='LoadImageFromFile'),
dict(type='LoadAnnotations', with_bbox=True),
dict(
type='Resize',
img_scale=[(1333, 640), (1333, 800)],
multiscale_mode='range',
keep_ratio=True,
backend='pillow'),
dict(type='RandomFlip', flip_ratio=0.5),
dict(
type='Normalize',
mean=[123.675, 116.28, 103.53],
std=[58.395, 57.12, 57.375],
to_rgb=True),
dict(type='Pad', size_divisor=128),
dict(type='DefaultFormatBundle'),
dict(type='Collect', keys=['img', 'gt_bboxes', 'gt_labels'])
])),
2、optimizer优化器从SGD改为AdamW
optimizer = dict(
type='AdamW',
lr=5e-05,
betas=(0.9, 0.999),
weight_decay=0.05,
paramwise_cfg=dict(
custom_keys=dict(
absolute_pos_embed=dict(decay_mult=0.0),
relative_position_bias_table=dict(decay_mult=0.0),
norm=dict(decay_mult=0.0))))
3、增加多尺度训练
多尺度训练(Multi Scale Training, MST)通常是指设置几种不同的图片输入尺度,训练时从多个尺度中随机选取一种尺度,将输入图片缩放到该尺度并送入网络中,是一种简单又有效的提升多尺度物体检测的方法。虽然一次迭代时都是单一尺度的,但每次都各不相同,增加了网络的鲁棒性,又不至于增加过多的计算量
train_pipeline = [
dict(type='LoadImageFromFile'),
dict(type='LoadAnnotations', with_bbox=True),
dict(
type='Resize',
# 多尺度训练
img_scale=[(1333, 640), (1333, 800)],
# img_scale=[(2000, 480), (2000, 1200)],
multiscale_mode='range',
keep_ratio=True,
backend='pillow'),
dict(type='RandomFlip', flip_ratio=0.5),
dict(type='Normalize', **img_norm_cfg),
dict(type='Pad', size_divisor=128),
dict(type='DefaultFormatBundle'),
dict(type='Collect', keys=['img', 'gt_bboxes', 'gt_labels']),
]
4、调整soft_nms,参数设置:(iou_threshold=0.7)
config文件——单GPU最优精度模型
tood_swin-s-p4-w12_fpn_mstrain_3x_coco.py
checkpoint_config = dict(interval=1)
log_config = dict(interval=50, hooks=[dict(type='TextLoggerHook')])
custom_hooks = [dict(type='NumClassCheckHook')]
dist_params = dict(backend='nccl')
log_level = 'INFO'
load_from = None
resume_from = None
workflow = [('train', 1)]
opencv_num_threads = 0
mp_start_method = 'fork'
pretrained = 'https://github.com/SwinTransformer/storage/releases/download/v1.0.0/swin_small_patch4_window7_224.pth'
model = dict(
type='TOOD',
backbone=dict(
type='SwinTransformer',
embed_dims=96,
depths=[2, 2, 18, 2],
num_heads=[3, 6, 12, 24],
window_size=7,
mlp_ratio=4,
qkv_bias=True,
qk_scale=None,
drop_rate=0.0,
attn_drop_rate=0.0,
drop_path_rate=0.2,
patch_norm=True,
out_indices=(1, 2, 3),
with_cp=False,
convert_weights=True,
init_cfg=dict(
type='Pretrained',
checkpoint=
'https://github.com/SwinTransformer/storage/releases/download/v1.0.0/swin_small_patch4_window7_224.pth'
)),
neck=[
dict(
type='FPN',
in_channels=[192, 384, 768],
out_channels=256,
start_level=0,
add_extra_convs='on_output',
num_outs=5)
],
bbox_head=dict(
type='TOODHead',
num_classes=6,
in_channels=256,
stacked_convs=6,
feat_channels=256,
anchor_type='anchor_free',
anchor_generator=dict(
type='AnchorGenerator',
ratios=[1.0],
octave_base_scale=8,
scales_per_octave=1,
strides=[8, 16, 32, 64, 128]),
bbox_coder=dict(
type='DeltaXYWHBBoxCoder',
target_means=[0.0, 0.0, 0.0, 0.0],
target_stds=[0.1, 0.1, 0.2, 0.2]),
initial_loss_cls=dict(
type='FocalLoss',
use_sigmoid=True,
activated=True,
gamma=2.0,
alpha=0.25,
loss_weight=1.0),
loss_cls=dict(
type='QualityFocalLoss',
use_sigmoid=True,
activated=True,
beta=2.0,
loss_weight=1.0),
loss_bbox=dict(type='GIoULoss', loss_weight=2.0),
num_dcn=2),
train_cfg=dict(
initial_epoch=4,
initial_assigner=dict(type='ATSSAssigner', topk=9),
assigner=dict(type='TaskAlignedAssigner', topk=13),
alpha=1,
beta=6,
allowed_border=-1,
pos_weight=-1,
debug=False),
test_cfg=dict(
nms_pre=1000,
min_bbox_size=0,
score_thr=0.05,
nms=dict(type='nms', iou_threshold=0.6),
max_per_img=100))
dataset_type = 'CocoDataset'
data_root = 'data/coco_6/'
img_norm_cfg = dict(
mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
train_pipeline = [
dict(type='LoadImageFromFile'),
dict(type='LoadAnnotations', with_bbox=True),
dict(
type='Resize',
img_scale=[(1333, 640), (1333, 800)],
multiscale_mode='range',
keep_ratio=True,
backend='pillow'),
dict(type='RandomFlip', flip_ratio=0.5),
dict(
type='Normalize',
mean=[123.675, 116.28, 103.53],
std=[58.395, 57.12, 57.375],
to_rgb=True),
dict(type='Pad', size_divisor=128),
dict(type='DefaultFormatBundle'),
dict(type='Collect', keys=['img', 'gt_bboxes', 'gt_labels'])
]
test_pipeline = [
dict(type='LoadImageFromFile'),
dict(
type='MultiScaleFlipAug',
img_scale=(1333, 800),
flip=False,
transforms=[
dict(type='Resize', keep_ratio=True, backend='pillow'),
dict(type='RandomFlip'),
dict(
type='Normalize',
mean=[123.675, 116.28, 103.53],
std=[58.395, 57.12, 57.375],
to_rgb=True),
dict(type='Pad', size_divisor=128),
dict(type='ImageToTensor', keys=['img']),
dict(type='Collect', keys=['img'])
])
]
data = dict(
samples_per_gpu=2,
workers_per_gpu=2,
train=dict(
type='RepeatDataset',
times=3,
dataset=dict(
type='CocoDataset',
ann_file='data/coco_6/voc07_trainval.json',
img_prefix='data/coco_6/',
pipeline=[
dict(type='LoadImageFromFile'),
dict(type='LoadAnnotations', with_bbox=True),
dict(
type='Resize',
img_scale=[(1333, 640), (1333, 800)],
multiscale_mode='range',
keep_ratio=True,
backend='pillow'),
dict(type='RandomFlip', flip_ratio=0.5),
dict(
type='Normalize',
mean=[123.675, 116.28, 103.53],
std=[58.395, 57.12, 57.375],
to_rgb=True),
dict(type='Pad', size_divisor=128),
dict(type='DefaultFormatBundle'),
dict(type='Collect', keys=['img', 'gt_bboxes', 'gt_labels'])
])),
val=dict(
type='CocoDataset',
ann_file='data/coco_6/voc07_test.json',
img_prefix='data/coco_6/',
pipeline=[
dict(type='LoadImageFromFile'),
dict(
type='MultiScaleFlipAug',
img_scale=(1333, 800),
flip=False,
transforms=[
dict(type='Resize', keep_ratio=True, backend='pillow'),
dict(type='RandomFlip'),
dict(
type='Normalize',
mean=[123.675, 116.28, 103.53],
std=[58.395, 57.12, 57.375],
to_rgb=True),
dict(type='Pad', size_divisor=128),
dict(type='ImageToTensor', keys=['img']),
dict(type='Collect', keys=['img'])
])
]),
test=dict(
type='CocoDataset',
ann_file='data/coco_6/voc07_test.json',
img_prefix='data/coco_6/',
pipeline=[
dict(type='LoadImageFromFile'),
dict(
type='MultiScaleFlipAug',
img_scale=(1333, 800),
flip=False,
transforms=[
dict(type='Resize', keep_ratio=True, backend='pillow'),
dict(type='RandomFlip'),
dict(
type='Normalize',
mean=[123.675, 116.28, 103.53],
std=[58.395, 57.12, 57.375],
to_rgb=True),
dict(type='Pad', size_divisor=128),
dict(type='ImageToTensor', keys=['img']),
dict(type='Collect', keys=['img'])
])
]))
evaluation = dict(interval=1, metric='bbox')
optimizer_config = dict(grad_clip=None)
optimizer = dict(
type='AdamW',
lr=5e-05,
betas=(0.9, 0.999),
weight_decay=0.05,
paramwise_cfg=dict(
custom_keys=dict(
absolute_pos_embed=dict(decay_mult=0.0),
relative_position_bias_table=dict(decay_mult=0.0),
norm=dict(decay_mult=0.0))))
lr_config = dict(
policy='step',
warmup='linear',
warmup_iters=500,
warmup_ratio=0.001,
step=[8, 11])
runner = dict(type='EpochBasedRunner', max_epochs=12)
work_dir = './work_dirs/tood_swin-s-p4-w12_fpn_mstrain_3x_coco'
auto_resume = False
gpu_ids = [0]