行人重识别论文阅读4,行人重识别实验笔记1-无锚行人搜索框架
Anchor-Free Person Search
无锚的行人搜索框架(AlignPS)Feature-Aligned Person Search Network(特征对齐的行人搜索网络)
解决的问题
解决不同级别的错位问题:提出对齐的特征聚合模块,通过遵循“reid first”的原则来生成更具有区分性和鲁棒性的特征嵌入。
本文提出:
-
无锚检测模型的典型架构,带有对齐特征聚合模块(AFA),AFA通过利用可变形卷积和特征融合来克服重识别特征学习中区域和尺度错位的问题,重塑FPN一些构造块。
-
one-step one-stage 框架有效解决行人搜索,无锚的方案将会成为研究主流。
-
AFA模块解决规模区域任务错位问题,已成功适应人员搜索任务的无锚探测器。
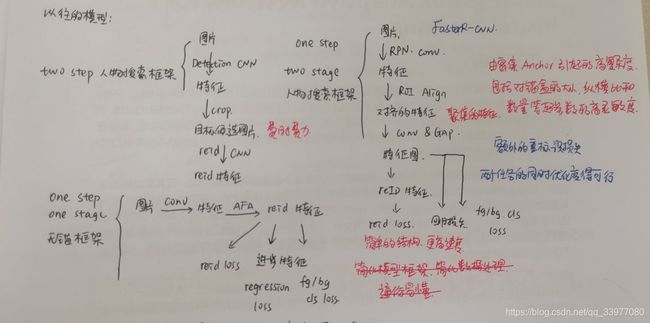
人物搜索分为:行人重识别和行人检测
人物搜索的挑战:遮挡、姿态/视点变化和背景混乱,寻找一个统一和优化的框架同时执行检测和重识别
重识别任务经常需要更多的数据增强,
两步模型可能会有更好的性能,一步模型具有简单高效的优点。
实验结果
在每一部分的测试中,单独使用每一部分能够比baseline的效果更好。将三部分结合一起能够比baseline性能提高20%左右。
AFA中三个尺度的结果在检测中,三个模块组合在一起性能最高,而P3的AP在检测分支中最高。在重识别中,P3也就是最后的处理模块在mAP和top1的性能都是最高的。

在验证三个对齐模块中,将不同级别的人分配到不同的特征级别来评估性能。不同的划分策略在召回率方面性能很好但是将规模失调问题带给重识别问题。多尺度训练策略没有很好地解决这个问题。
表2对应的实验为了证明区域对齐的有效性。
可变形滤波器可以根据人体布局来适应感受野,并对遮挡拥挤和尺度变化具有鲁棒性。C3学习了身体中心更加紧凑的偏移,C4能够跨越更大的区域可以使两个层相互补充。
框架概述
框架基于FCOS-最流行的单级无锚物体探测器之一(重识别优先),它强调重标识子任务学习健壮的特征嵌入。
同时定位图像中多个人物并学习其中的reid特征,AFA聚合主干网络多级特征图中的要素。
学习重标识嵌入可直接从AFA输出特征图中获取展平的特征作为最终嵌入而不需要额外的特征层。
检测时使用两个分支的FCOS的检测头:一个分支预测回归偏移和中心分数/另一个分支进行前景背景分类。
最后使用AFA输出特征图上的每个位置将于一个带有分类和中心分数的边界框以及一个重标识的特征嵌入相关联。

框架详述
对齐特征聚合
利用不同层次的特征图来学习检测和重新识别特征:尺度对齐,区域对齐,任务对齐。
尺度对齐:特征聚合块
最初的FCOS使用不同层次特征来检测不同大小的物体检测性能提高,因为重叠的模糊样本将被分配到不同的层。
对reid任务多级预测可能导致不同尺度的特征错位(匹配到不同尺度的人,重复的特征,不一致的取自FPN的不同层次)
在框架中,仅基于单层AFA进行预测,明确解决由初度变化引起特征错位问题。
使用ResNet50的C3,C4,C5特征图依次输出stride为32,16和8的P5,P4,P3。
只从P3生成特征,这是最大的输出特征图,用于检测和reid子任务。
区域对齐:lateral Dconv
在AFA输出特征图上,每个位置基于一个大的感受野感知来自整个输入图像的信息
由于缺少Faster-RCNN的ROI操作导致区域对齐操作。
解决方案:
- 用3X3 deformable 卷积层代替1X1卷积层,自适应的调整输入特征图上的感受野隐含的实现区域对齐
- 将自顶向下的求和操作替换为串联操作,这样可以更好地聚合多级特征
- 将3X3 conv -> 3X3 deformable conv作为FPN的输出层,进一步对齐多级要素,最终生成更精确的特征图
任务对齐:output conv
实验中,较差inferior的reid特征影响了总体的性能
AFA的输出特征直接由reid loss来监督,然后被送到检测头
reid优先基于这两个来考虑。1)检测子任务已经被框架很好的解决,主要是学习有区别的嵌入,无锚框架中reid性能对区域错位比较敏感,所以框架应该专注于重识别任务。2)与检测优先的并行结构相比,reid优先不许需要额外生成reid特征,所以更有效。
三元组辅助在线匹配损失
OIM将所有标记身份的特征中心存储在查找表中, V ∈ R D × L = { v 1 , . . . , v L } V \in \mathbb R^{D \times L}=\{v_1,...,v_L\} V∈RD×L={v1,...,vL},其中包含D维 L个特征向量
循环队列 U ∈ R D × Q = { u 1 , . . . , u Q } U \in \mathbb R^{D \times Q}=\{u_1,...,u_Q\} U∈RD×Q={u1,...,uQ},包含Q个未标记的身份特征。
每一次迭代中,标签i的输入特征x,OIM通过 V T x V_Tx VTx和 Q T x Q^Tx QTx计算x与LUT和循环队列中所有特征间的相似度。
x属于特征T的概率:
p i = exp ( v i T x ) / τ ∑ j = 1 L exp ( v j T x ) / τ ∑ k = 1 Q exp ( u k T x ) / τ p_i = \frac {\exp(v^T_ix)/\tau} {\sum^L_{j=1}\exp(v_j^Tx)/\tau \sum^Q_{k=1}\exp(u^T_kx)/\tau} pi=∑j=1Lexp(vjTx)/τ∑k=1Qexp(ukTx)/τexp(viTx)/τ
其中, τ = 0.1 \tau=0.1 τ=0.1控制概率分布柔度的超参数,OIM目标最小化预期的负对数似然
L O I M = − E x [ log p t ] , t = 1 , 2 , . . . , L \mathcal L_{OIM} = - E_x[\log p_t], t=1,2,...,L LOIM=−Ex[logpt],t=1,2,...,L
OIM有效使用了标记和未标记的样本,但仅计算输入特征和存储在查找表和循环队列中特征之间的距离,而不是进行输入特征之间的比较,其次对数似然损失项没有给出特征对之间的明确距离度量,此时采用对每个人,位于人中心周围一组特征被认为是正样本,目标是聚集同一个人的特征向量,分散不同人的特征向量。
同时来自被标记的人的特征应该接近存储在LUT相应特征,远离LUT其他特征,从同一个人中sample出S个向量, X m = { x m , 1 , . . . , x m , s , v m } , X n = { x n , 1 , . . . , x n , s , v n } X_m = \{x_{m,1},...,x_{m,s},v_m\},X_n=\{x_{n,1},...,x_{n,s},v_n\} Xm={xm,1,...,xm,s,vm},Xn={xn,1,...,xn,s,vn}.特征候选集。
可在每个集合内对正对采样,在两个集合间对负对进行采样。

损失计算:
L t r i = ∑ p o s , n e g [ M + D p o s + D n e g ] \mathcal L_{tri} = \sum_{pos,neg} [M + D_{pos} + D_{neg}] Ltri=pos,neg∑[M+Dpos+Dneg]
M是距离边界,后两项是正对和负对之间的欧几里得距离。
最后的Loss可表示为:
L T O I M = L t r i + L O I M \mathcal L_{TOIM} = \mathcal L_{tri} + \mathcal L_{OIM} LTOIM=Ltri+LOIM
实验错误排除
首先记录一生之敌的解决方案:
上次说到一生之敌:Cuda out of memory! 然后我尝试了好多方法,最后使用了两种方法的组合:
一是在训练前的那一块加入一行代码情况cuda的缓存:
# train.py Line 165
torch.cuda.empty_cache()
然后,修改他所谓的batchsize,具体步骤如下:

# 文件路径configs/fcos/prw_base_focal_labelnorm_sub_ldcn_fg15_wd1-3.py
# Line 61,62
samples_per_gpu = 1, # 4
workers_per_gpu = 1, # 4
#Line 81,82
optimizer = dict(
lr=0.0001,paramwise_cfg=dict(bias_lr_mult=2.,bias_decay_mult=0.),weight_decay=0.0001)

然后就可以奇迹般的跑通了。以后跑代码一定要勤于做笔记,遇到每个问题都要记录下来。
针对实验中没有result_1000.pkl的问题,我观察到它使用python的命令行加上参数来运行的tools/test.py的文件,然后我通过在terminal中运行test.py文件,加上特定的参数,创建好文件,让程序自动的写入文件中。
python tools/test.py configs/fcos/fcos_center-normbbox-centeronreg-giou_r50_caffe_fpn_gn-head_dcn_4x4_1x_cuhk_reid_1500_stage1_fpncat_dcn_epoch24_multiscale_focal_x4_bg-2_lconv3dcn_sub_tri
queue.py work_dirs/fcos_center-normbbox-centeronreg-giou_r50_caffe_fpn_gn-head_dcn_4x4_1x_cuhk_reid_1500_stage1_fpncat_dcn_epoch24_multiscale_focal_x4_bg-2_lconv3dcn_sub_triqueue/latest.pth --out work_dirs/fcos_center-normbbox-centeronreg-giou_r50_caffe_fpn_gn-head_dcn_4x4_1x_cuhk_reid_1500_stage1_fpncat_dcn_epoch24_multiscale_focal_x4_bg-2_lconv3dcn_sub_triqueue/results_1000.pkl

实验结果
readme中的结果

测试结果
| Dataset | Model | mAP | Rank1 | Rank5 | Rank10 |
|---|---|---|---|---|---|
| CUHK-SYSU | AlignPS | 92.68% | 93.31% | 97.79% | 98.66% |
| CUHK-SYSU | AlignPS+ | 92.94% | 93.48% | 98.07% | 98.59% |
| PRW | AlignPS | 45.86% | 83.08% | 91.35% | 93.58% |
| PRW | AlignPS+ | 46.86% | 82.06% | 90.81% | 92.76% |
run_test_prw

run_test_cuhk

run_test_prw+

run_test_chuk+

可视化结果
我注释掉两个assert之后得到的结果

方法3

方法1
