论文笔记:CLOCs: Camera-LiDAR Object Candidates Fusion for 3D Object Detection
CLOCs: Camera-LiDAR Object Candidates Fusion for 3D Object Detection
1.为什么要做这个研究(理论走向和目前缺陷) ?
在3D目标检测领域,目前的fusion普遍都是deep fusion,效果不如只基于lidar的方法。本文选择使用之前不常用的late fusion。
2.他们怎么做这个研究 (方法,尤其是与之前不同之处) ?
就是将来自不同2D和3D检测器的结果做一个deep fusion,并且fusion处理的的是一个稀疏的向量。
3.发现了什么(总结结果,补充和理论的关系)?
结果还不错,使得fusion在3D目标检测中用的方法的精度有了不小提升。但是还存在一些疑问:
1.网络最终输出的只是n个检测值(类别),检测框的结果去哪儿了,是按照之前3D检测器的检测结果吗?如果是的话,那该网络就没有改变3D检测器所检测出的3D框的结果。
2.2D检测器检测到了,3D检测器没检测到,就直接忽略了,这样做真的合适吗?
4.摘要
目前的3D目标检测的工作,基于融合(多模态)的方法很难取得比单模态更好的效果。CLOCS提供了一个low-complexity multi-modal fusion,这个网络可以显著提高单模态检测器的表现。
5.引言
仍然强调了LiDAR-only based methods outperform most of the fusion based methods.
Fusion可分为三类: early fusion,deep fusion,late fusion,它们各有利弊。
尽管early和deep fusion 有很大的潜力去利用跨模态信息 ,但他们对数据对齐很敏感,并且经常包括了很复杂的网络结构,并且需要传感器数据像素级别的对应。
late fusion的结构更简单因为他们包含提前训练好的不需要改变的单模态检测器,仅仅需要在决策层的联系。
Versatility & Modularity:可以随意使用任意的2D或者3D的检测器,因为不需要重新训练。
Probabilistic-driven Learning-based Fusion:
Speed and Memory:速度较快,占用内存少。
Detection Performance:在KITTI中,是使用融合的方法中精度最高的。
6.相关研究
3D Detection Using 2D Images:
3D Detection Using Point Cloud:
基于点云的3D检测目前很流行,但是它们在长距离时的表现相对较差,分为one stage architecture和two stage architecture。
one stage architecture:
Voxelnet:use voxels
SECOND:use sparse 3D CNNs which reduces the inference time significantly
Pointpillars: use pillars,then use 2D CNNs,所以大大提升了速度,可达到62HZ。
two stage architecture:
PointRCNN ,Fast PointRCNN and STD
3D Detection Using Multi-modal Fusion:
2D driven 3D detectors:
Frustum PointNet , Pointfusion and Frustum ConvNet
这些方法的缺点:But the 2D image-based proposal generation might fail in some cases
that could only be observed from 3D space.
project the raw point cloud into bird’s eye view (BEV) to form a multi-channel BEV image:
MV3D,AVOD,MMF
这些方法的缺点:表现比只基于lidar的差不少,有两个原因,第一,将原始点云转化为BEV图像时损失了空间信息;第二,为了跨模态融合时使用的crop和resize操作可能会破坏来自每个传感器的特征。(原文中在后面还有详细的讲解)
7.MOTIVATION
2D and 3D Object Detection
这一部分其实就是想说明正确的3D检测结果和2D检测结果可以在2D图中正确地重合在一起。

Why Fusion of Detection Candidates
late fusion其实就是对detection candidates的融合,这一部分讲了这么做的好处。
8. CAMERA-LIDAR OBJECT CANDIDATES FUSION
A.Geometric and Semantic Consistencies
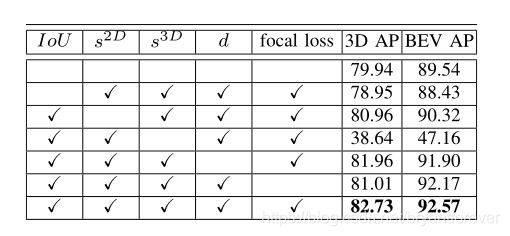
这部分就是说本文在做late fusion(fusion of detection candidates)时,考虑了Geometric consistency(体现在3D检测框和2D检测框的交并比上)和Semantic consistency(2D检测器和3D检测器输出的类别相同)。
B. Network Architecture
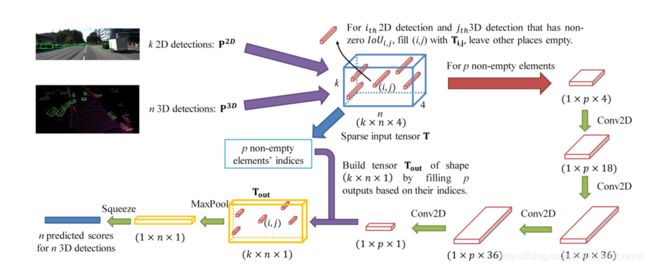
1) Sparse Input Tensor Representation:
首先是2D candidates的表示:
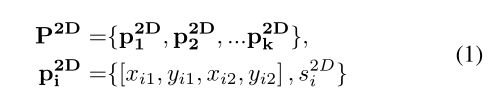
然后是3D candidates的表示:
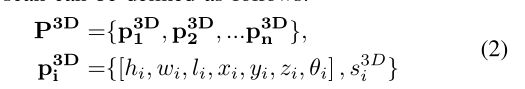
之后就可以创建一个k × n × 4的Tensor T:

当IoU为0时,这个Tij就被消除,因为它们是geometrically inconsistent。
因为只有少数的2D框能与3D框能对应(因为作者认为3D框具体有更高的可信度,所以不论3D框有没有对应的2D框,所有的3D框都会被保存下来),所以T向量是稀疏的。
之后我们将p个非空的T给到之后的网络中。
C. Network Details
见上图,最后输出1 × n的得分图。
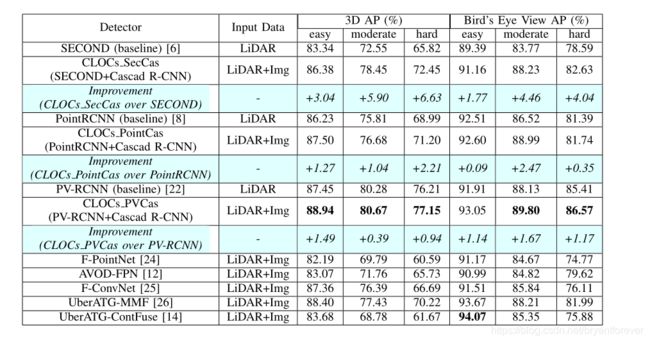
D. Experiment
做了多种组合的实验:
2D detectors:RRC, MS-CNN and Cascade R-CNN
3D detectors:SECOND, PointPillars, PointRCNN and PV-RCNN