DCFEE A Document-level Chinese Financial Event Extraction System based on Automatically Labeled论文解读
DCFEE: A Document-level Chinese Financial Event Extraction System based on Automatically Labeled Training Data

paper:DCFEE: A Document-level Chinese Financial Event Extraction System based on Automatically Labeled Training Data - ACL Anthology
code:yanghang111/DCFEE (github.com)
期刊/会议:ACL 2018
摘要
我们提出了一个事件抽取框架,目的是从文档级财经新闻中抽取事件和事件提及。到目前为止,基于监督学习范式的方法在公共数据集中获得了最高的性能(如ACE 2005、KBP 2015)。这些方法严重依赖于人工标注的训练数据。然而,在特定领域,如金融、医疗和司法领域,由于数据标记过程的高成本,没有足够的标记数据。此外,当前的大多数方法侧重于从一个句子中抽取事件,但一个事件通常由一个文档中的多个句子表示。为了解决这些问题,我们提出了一个文档级中文金融事件提取(DCFEE)系统,该系统可以自动生成大规模标记数据并从整个文档中提取事件。实验结果证明了该方法的有效性。
1、简介
事件抽取(EE)是自然语言处理(NLP)中一项具有挑战性的任务,旨在发现事件提及,并从文本中抽取包含事件触发词和事件论元的事件。例如,在图1中,EE系统预计将发现由冻结 (frozen)引发的股权冻结(Equity Freeze)事件(E1本身),并提取相应的五个不同角色的论点: Nagafu Ruihua (Role=Shareholder Name), 520,000 shares (Role=Num of Frozen Stock), People’s Court of Dalian city (Role=Frozen Institution), May 5,2017 (Role=Freezing Start Date) and 3 years (Role=Freezing End Date)。从文本中提取事件实例在构建NLP应用程序(如信息提取(IE)、问答(QA)和摘要(Ahn,2006)中发挥着关键作用。最近,研究人员已经建立了一些英文EE系统,如EventRegistry7和Stela8。然而,在金融领域,还没有这样有效的EE系统,尤其是中文。
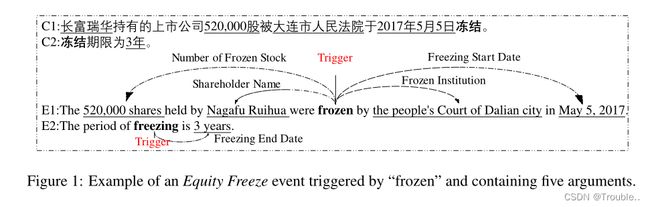
金融事件能够帮助用户获得竞争对手的策略,预测股市并做出正确的投资决策。例如,股权冻结(Equity Freeze)事件的发生将对公司产生不利影响,股东应迅速做出正确的决定以避免损失。在商业领域,公司发布的官方公告代表了重大事件的发生,如股权冻结(Equity Freeze)事件、股权交易(Equity Trading)事件等。因此,从公告中发现事件提及并抽取事件是很有价值的。然而,中国金融EE面临两个挑战。
数据匮乏。大多数EE方法通常采用监督学习范式,该范式依赖于复杂的人工标注数据,但在中国金融领域没有针对EE的标注语料库。
文档级事件抽取。大多数当前的事件抽取任务都是句子级的事件抽取文本。但一个事件通常在文档中用多个句子来表达。在本文构建的金融领域数据集中,91%的情况下事件参数分布在不同的句子中。例如,如图1所示,E1和E2一起描述了股权冻结(Equity Freeze)事件。
为了解决上述两个问题,我们提出了一个名为DCFEE的框架,它可以基于自动标记的训练数据从公告中抽取文档级事件。我们利用已验证的远程监控(DS)为EE生成标记数据,自动生成大规模标注数据。我们使用序列标注模型来自动提取句子级事件。然后,我们提出了一个关键事件检测模型和一个论元填充策略,以从文档中提取整个事件。
总之,本文的贡献如下:
- 我们提出了DCFEE框架,它可以自动生成大量标记数据,并从财务公告中提取文档级事件。
- 我们介绍了一种用于事件抽取的自动数据标注方法,并为构建中国金融事件数据集提供了一系列有用的提示。我们提出了一个主要基于神经网络序列标注模型、关键事件检测模型和论元填充策略的文档级EE系统。实验结果表明了该方法的有效性。
- DCFEE系统已成功构建为一个在线应用程序,可快速从财务公告中抽取事件。
2、方法
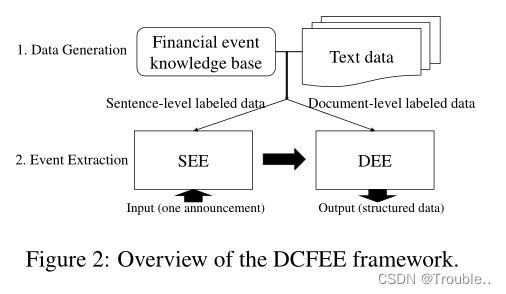
图2描述了我们提出的DCFEE框架的架构,主要包括以下两个组件:(i)数据生成,它利用DS自动标记整个文档中的事件提及(文档级数据),并标注事件提及(句子级数据)中的触发词和论元;(ii)EE系统,包含由句子级标注数据支持的句子级事件抽取(SEE)和由文档级标注数据支撑的文档级事件抽取(DEE)。在下一节中,我们简要描述了标记数据的生成和EE系统的架构。
2.1 数据生成
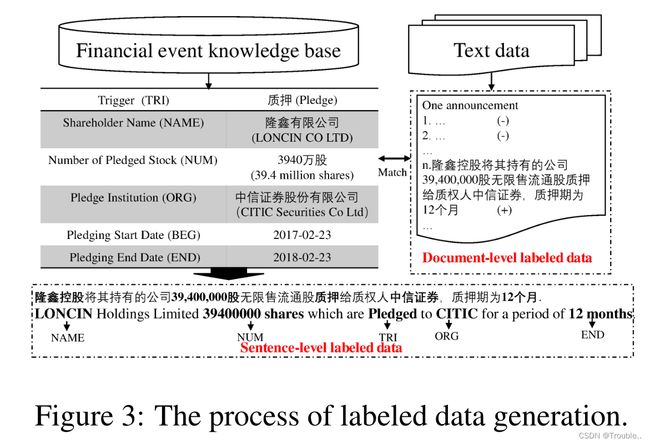
图3描述了基于DS方法生成标记数据的过程。在本节中,我们首先介绍了我们使用的数据源(结构化数据和非结构化数据)。然后我们描述了自动标记数据的方法。最后,我们将介绍一些可以用来提高标记数据质量的提示。
数据来源:自动生成数据需要两种类型的数据资源:包含大量结构化事件数据的金融事件知识数据库和包含事件信息的非结构化文本数据。(i) 本文使用的金融事件知识数据库是结构化数据,包括九种常见的金融事件类型,并以表格格式存储。这些包含关键事件论点的结构化数据是金融专业人士从公告中总结出来的。以股权质押(Equity Pledge)事件为例,如图3左侧所示,其中关键论元包括股东名称(Shareholder Name)(Name)、质押机构(Pledge Institution)(ORG)、质押股票数量(Number of Pledged Stock)(NUM)、质押开始日期(Pledging Start Data)(BEG)和质押结束日期(Pledging End Data)(End)。(ii)非结构化文本数据来自公司发布的官方公告,这些公告以非结构化形式存储在网络上。我们从搜狐证券网获取这些文本数据。
数据生成方法:标注数据由两部分组成:通过标记事件提及中的事件触发词和事件论元生成的句子级数据;通过标记来自文档级公告的事件提及而生成的文档级数据。现在的问题是,如何找到事件触发词。与结构化事件知识数据库相对应的事件论元和事件提及是从大量公告中总结出来的。DS已证明其在自动标记数据以用于关系抽取和事件抽取方面的有效性。受DS启发,我们假设一句话包含最多的事件论元,并且由特定触发词驱动,很可能是公告中提到的事件。事件中出现的论点有可能在事件中扮演相应的角色。对于每种类型的金融事件,我们构建了一个事件触发词字典,例如在股权冻结(Equity Freeze)事件中冻结(freeze)和在股权质押(Equity Pledge)事件中质押(pledge)。因此,可以通过从公告中查询预定义的字典来自动标记触发词。通过这些预处理,结构化数据可以映射到公告中的事件论元。因此,我们可以自动识别事件提及并标记事件触发词及其包含的事件论元,以生成句子级数据,如图3底部所示。然后,事件提及被自动标记为正面示例,公告中的其余句子被标记为负面示例,以构成文档级数据,如图3右侧所示。文档级数据和句子级数据一起构成EE系统所需的训练数据。
技巧:事实上,数据标注存在一些挑战:财务公告与事件知识库的对应;事件论元的模糊性和缩写。我们使用了一些技巧来解决这些问题,示例如图3所示。(i) 减少搜索空间:通过检索关键事件论元(如发布日期和公告的股票代码),可以减少候选公告的搜索空间。(ii)正则表达式:可以匹配更多的事件论元,以通过正则表达式提高标记数据的召回率。例如,财务事件数据库中的LONCIN CO LTD(角色=股东名称),但公告中的LOUNCIN。我们可以通过正则表达式解决这个问题,并将LONCIN标记为事件论元。(iii)规则:一些任务驱动的规则可以用于自动标注数据。例如,我们可以通过计算2017-0223(角色=抵押开始日期)和2018-02-23(角色=质押结束日期)之间的日期差来标记12个月(角色=担保结束日期)。
2.2 事件抽取
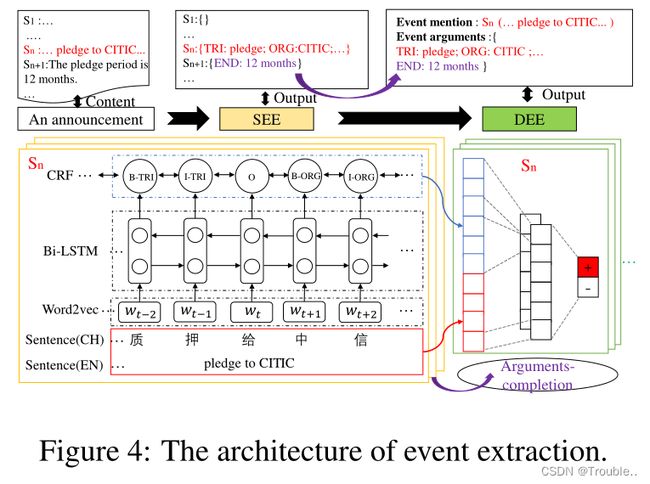
图4描述了本文提出的EE系统的总体架构,主要包括以下两个部分:句子级事件提取(SEE)的目的是从句子中抽取事件论元和事件触发词。文档级事件提取(DEE)旨在基于关键事件检测模型和论元填充策略从整个文档中提取事件论元。
2.2.1 句子级抽取
我们将SEE转化为一个序列标注任务,训练数据由句子级标注数据支持。句子以BIO格式表示,如果标记是事件论元的开始,则每个字符(事件触发词、事件论元和其他)标记为B-label,如果标记在事件论元内,则标记为I-label,否则标记为O-label。近年来,神经网络被用于大多数NLP任务,因为它可以从文本表示中自动学习特征。Bi-LSTM-CRF模型可以在经典NLP任务(如词性标注(POS)、分词和NER)上产生最先进(或接近)的准确性。由于双向长短期记忆(BiLSTM)组件,它可以有效地结合过去和将来的输入特征,并且由于条件随机字段(CRF)层,它还可以使用句子级标签信息。
SEE的具体模型实现如图4左侧所示,由Bi-LSTM神经网络和CRF层组成。句子中的每个汉字都由一个向量表示,作为Bi-LSTM层的输入。BiLSTM层的输出被投影为每个角色的分数。并且使用CRF层来克服标签偏差问题。SEE最终返回文档中每个句子的句子级别EE的结果。
2.2.2 文档级事件抽取
DEE由两部分组成:一个关键事件检测模型,旨在发现文档中提到的事件,另一个论元填充策略,旨在填补缺失的事件论元。
关键事件检测:如图4右侧所示,事件检测的输入由两部分组成:一部分是来自SEE输出的事件论元和事件触发词的表示(蓝色),另一部分是当前句子的向量表示(红色)。两个部分被连接作为卷积神经网络(CNN)层的输入特征。然后将当前句子分为两类:关键事件与否。
论元填充策略:我们通过DEE获得了包含大多数事件论元的关键事件,并通过SEE获得了文档中每个句子的事件抽取结果。为了获得完整的事件信息,我们使用论元填充策略,该策略可以自动填充周围句子中缺少的事件论元。如图4所示,集成的质押事件包含事件提及 S n S_n Sn中的事件论元和从句子 S n + 1 S_{n+1} Sn+1中获得的12个月的填充事件论元。
3、评估
3.1 数据集
我们对四种类型的金融事件进行了实验:股权冻结(Equity Freeze)(EF)事件、股权质押(Equity Pledge)(EP)事件、股票回购(Equity Repurchase)(ER)事件和股权超重(Equity Overweight)(EO)事件。共有2976项公告通过自动生成数据进行了标注。我们将标记的数据分为三个子集:训练集(占公告总数的80%)、开发集(10%)和测试集(10%。表1显示了数据集的统计信息。NO.ANN表示可以为每个事件类型自动标记的公告数量。NO.POS表示肯定格句(事件提及)的总数。相反,NO.NEG表示否定格句子的数量。正面和负面案例句子构成了作为DEE训练数据的文档级数据。包含事件触发词和一系列事件论元的肯定句子被标记为SEE的句子级训练数据。
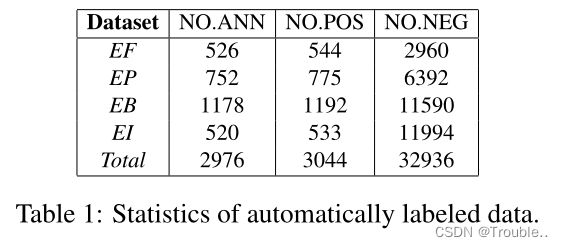
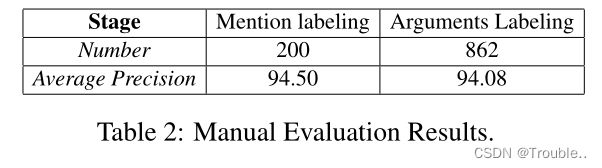
我们随机选择200个样本(包含862个事件参数)来人工评估自动标记数据的精度。表2显示了平均精度,这表明我们的自动标记数据具有高质量。
3.2 系统的效果
我们使用precision(P)、recall(R)和(F1)来评估DCFEE系统。表3显示了基于模式匹配的方法和DCFEE在提取股权冻结事件中的表现。实验结果表明,在大多数事件参数提取中,DCFEE的性能优于基于模式的方法。
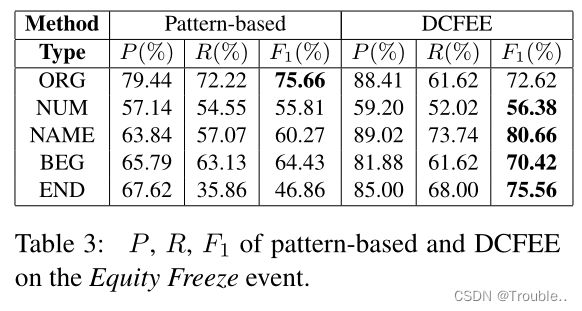
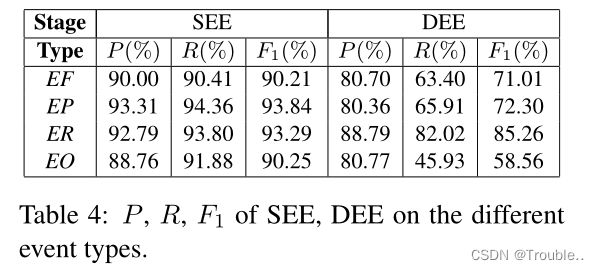
表4显示了SEE和DEE在不同事件类型上的P、R、F1。值得注意的是,SEE阶段使用正确数据是自动生成的数据,DEE阶段使用的正确数据来自金融事件知识库。实验结果表明,SEE和DEE的有效性,本文提出的DCFEE系统的可接受精度和可扩展性是满足要求的。
总之,实验表明,基于DS的方法可以自动生成高质量的标注数据,避免人工标注。它还验证了本文中提出的DCFEE,它可以从文档级视图中有效地提取事件。
4、DCFEE的应用
DCFEE系统的应用:中文金融文本的在线EE服务。它可以帮助财务专业人员快速从财务公告中获取事件信息。图5显示了在线DCFEE系统的屏幕截图。不同颜色的单词表示不同的事件论元类型,带下划线的句子表示文档中提到的事件。如图5所示,我们可以从非结构化文本(关于股权冻结(Equity Freeze)的公告)中获得完整的股权冻结(Equity Freeze)事件。

5、相关研究
当前的EE方法主要可分为统计方法、基于模式的方法和混合方法。统计方法可分为两类:基于特征提取工程的传统机器学习算法,基于自动特征提取的神经网络算法。模式方法通常用于工业中,因为它可以实现更高的准确性,但同时也可以降低召回率。为了提高召回率,有两个主要的研究方向:构建相对完整的模式库,并使用半自动方法构建触发字典。混合事件提取方法将统计方法和基于模式的方法结合在一起。据我们所知,目前还没有一个系统能够自动生成标记数据,并从中国金融领域的公告中自动提取文档级事件。
6、总结
模式库,并使用半自动方法构建触发字典。混合事件提取方法将统计方法和基于模式的方法结合在一起。据我们所知,目前还没有一个系统能够自动生成标记数据,并从中国金融领域的公告中自动提取文档级事件。