【多任务学习-Multitask Learning概述】
多任务学习-Multitask Learning概述
- 1.单任务学习VS多任务学习
-
- 多任务学习的提出
- 多任务学习和单任务学习对比
- 2.多任务学习
-
- 共享表示shared representation:
- 多任务学习的优点
- 那么如何衡量两个任务是否相关呢?
- 当任务之间相关性弱
- 多任务MLP特点总结
- 多任务学习与其他学习算法之间的关系
- 多任务学习应用
1.单任务学习VS多任务学习
1.单任务学习
一次只学习一个任务(task),大部分的机器学习任务都属于单任务学习。
2.多任务学习
把多个相关(related)的任务放在一起学习,同时学习多个任务。
多任务学习的提出
问题提出:
现在大多数机器学习任务都是单任务学习。对于复杂的问题,也可以分解为简单且相互独立的子问题来单独解决,然后再合并结果,得到最初复杂问题的结果。这样做看似合理,其实是不好的的,因为现实世界中很多问题不能分解为一个一个独立的子问题,即使可以分解,各个子问题之间也是相互关联的,通过一些共享因素或共享表示(share representation)联系在一起。把现实问题当做一个个独立的单任务处理,忽略了问题之间所富含的丰富的关联信息。
解决方法:
多任务学习就是为了解决这个问题而诞生的。把多个相关(related)的任务(task)放在一起学习。这样做会很有效的解决问题,多个任务之间共享一些因素,它们可以在学习过程中,共享它们所学到的信息。相关联的多任务学习比单任务学习能取得更好的泛化(generalization)效果。
多任务学习和单任务学习对比
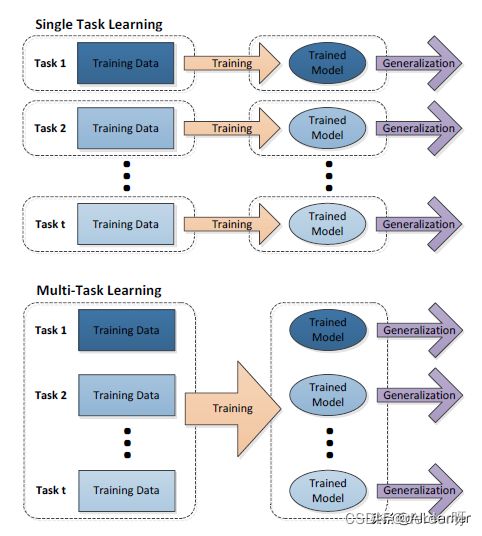
从图1中可以发现,单任务学习时,各个任务之间的模型空间(Trained Model)是相互独立的(图1上)。多任务学习时,多个任务之间的模型空间(Trained Model)是共享的(图1下)。
2.多任务学习
多任务学习(Multitask learning)定义:基于共享表示(shared representation),把多个相关的任务放在一起学习的一种机器学习方法。
多任务学习涉及多个相关的任务同时并行学习,在神经网络中同时反向传播,多个任务通过浅层的共享表示(shared representation)来互相帮助学习,提升泛化效果。简单来说:多任务学习把多个相关的任务放在一起学习(注意,一定要是相关的任务),学习过程中通过一个在浅层的共享表示来互相分享、互相补充学习到的领域相关的信息,互相促进学习,提升泛化的效果。
共享表示shared representation:
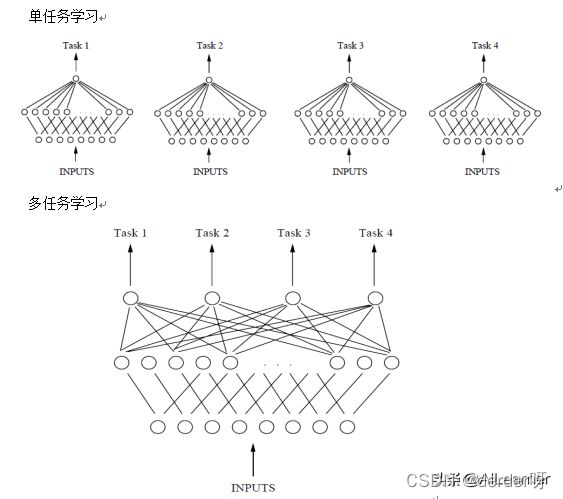
共享表示的目的是为了提高泛化(improving generalization),图2中给出了多任务学习最简单的共享方式,多个任务在浅层共享参数。MTL中共享表示有两种方式:
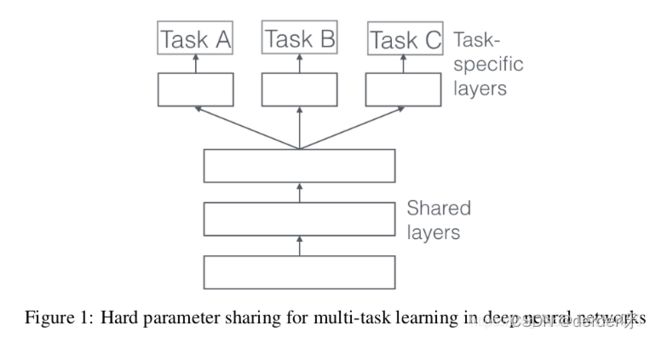
(1)、基于参数的共享(也叫硬约束)(Parameter based):比如基于神经网络的MTL
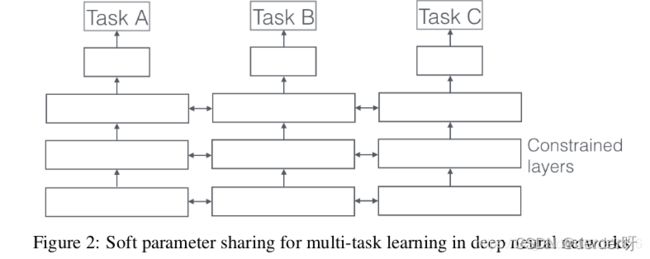
(2)、基于软约束的共享(regularization based):比如均值,联合特征(Joint feature)学习(创建一个常见的特征集合or矩阵)。每个任务都有自己的模型,自己的参数。我们对模型参数的距离进行正则化来保障参数的相似
两种常见共享表示的比较:
基于软约束的多任务学习方法,该方法不要求底部的参数完全一样,而是对不同任务底部的参数进行正则化。相对于硬参数约束的多任务深度学习模型,软约束的多任务学习模型的约束更加宽松,当任务关系不是特别紧密的时候,有可能学习得到更好的结果
如何参数共享?
从机器学习的角度来看,我们将多任务学习视为一种归纳迁移。归纳迁移通过引入归纳偏置来改进模型,使得模型更倾向于某些假设。举例来说,常见的一种归纳偏置是L1正则化,它使得模型更偏向于那些稀疏的解。在多任务学习场景中,归纳偏置是由辅助任务来提供的,这会导致模型更倾向于那些可以同时解释多个任务的解。
我们可以记得的是L1正则化是对参数之和上的约束,强制除少数几个外的其他所有参数为0。
通过正则化我们选取所要在不同人任务模型之间共享的参数。块稀疏正则化相对复杂不展开先简单了解。
块稀疏正则化
为了更好的将这些方法联系起来,我们首先介绍了一些符号的含义。我们有T个任务,每个任务t,对应的模型记为,模型参数记为,维度为d维。我们用列向量来表示参数。将这些列向量堆起来形成一个矩阵。矩阵A的第i行对应每个模型的第i个特征,第j列对应任务j的模型参数。
现有的许多方法都对模型参数做出稀疏性假设。文献[8]认为所有模型共享参数的一个小集合。从任务参数矩阵A的角度来看,这就意味着除了少数几行外全部是0,与之对应的只有少数特征是可以在不同任务间共享的。为了强制做到这一点,在多任务学习中强制加L1正则化项。我们可以记得的是L1正则化是对参数之和上的约束,强制除少数几个外的其他所有参数为0。L1正则化又被称为LASSO(Least Absolute Shrinkage and Selection Operator)。
对于单一任务场景,L1正则化的计算仅依赖于单个任务t中的模型参数。对于多任务场景,L1正则化的计算是基于任务参数矩阵A,首先对每行(对应每个任务的第i个特征)计算正则化,产生列向量,然后计算这个向量的L1正则化,从而强迫b中大部分项为0。
我们可以使用不同的正则化,取决于我们想要对每行设置什么样的约束。一般来说,我们将之称为混合正则化(mix norm)约束正则化。由于这样做导致A的整行为0,故可称之为块稀疏性正则化(Block-Sparsity Regularization)。文献[9]使用正则化,而Argyriou使用正则化。后者又被称为group lasso,首次提出是在文献[10]中。Argyriou等人于2007年的时候证明了优化非凸的group lasso可以通过对任务参数矩阵A进行迹正则化(trace norm)约束转化为凸优化问题。也就是,强制矩阵A是低秩的,其中的每一个列向量都位于一个低维度的子空间。文献[11]为了进一步在多任务学习中使用group lasso来建立上界约束。
块稀疏正则化在直觉上是非常受欢迎的,它的受欢迎程度与它依赖于任务间参数共享程度是一样的。文献[12]证明了当任务间特征不重叠时,正则化可能会比单纯的元素层面的正则化效果更糟。因此,文献[13]提出了将块稀疏正则化与元素稀疏正则化结合以改进块稀疏模型。他们将任务参数矩阵A分解为矩阵B与S,其中A=B+S。然后,对B使用强制的块稀疏正则化,对S使用lasso来进行元素稀疏正则化。文献[14]提出了一个分布式版本的group lasso正则化。
如何实现软约束?
其中是平均参数向量。该惩罚项强制一些任务向量的聚类靠近其均值,用来控制。
它寻求使得所有模型接近均值模型。
多任务学习的优点
(1)、提高泛化能力,多人相关任务放在一起学习,有相关的部分,但也有不相关的部分。当学习一个任务(Main task)时,与该任务不相关的部分,在学习过程中相当于是适当的噪声,因此,引入噪声可以提高学习的泛化(generalization)效果。
(2)、防止陷入局部最优,单任务学习时,梯度的反向传播倾向于陷入局部极小值。多任务学习中不同任务的局部极小值处于不同的位置,通过相互作用,可以帮助隐含层逃离局部极小值。
(3)、提高学习速率和效果,添加的任务可以改变权值更新的动态特性,可能使网络更适合多任务学习。
(4)、防止过拟合,多个任务在浅层共享表示,可能削弱了网络的能力,降低网络过拟合,提升了泛化效果。
(5)、学习能力提升,某些特征可能在主任务不好学习,但在辅助任务上好学习。可以通过辅助任务来学习这些特征
(6)、偏置机制。多任务学习更倾向于学习到一类模型。由于一个对足够多的训练任务都表现很好的假设空间,对来自于同一环境的新任务也会表现很好,所以这样有助于模型展示出对新任务的泛化能力[7]。
那么如何衡量两个任务是否相关呢?
一些理论研究:
- 使用相同的特征做决策
- 相关的任务共享同一个最优假设空间(having the same inductive bias)
- F-related: 如果两个任务的数据是通过一个固定分布经过一些变换得到
- 分类边界(parameter vectors)接近
任务是否相似不是非0即1的,越相似的任务,收益越大。
当任务之间相关性弱
当任务之间相关性较弱,使用上述方法可能导致negative transfer(也就是负向效果)。在此情景下,我们假设某些任务之间是相关的,但是某些任务之间是相关性较差。可以通过引入任务集合来约束模型(第二种常见的共享表示)。可以通过动态的约束 不同任务的参数向量 和降低他们的方差。限制不同模型趋向于不同的各自任务参数向量。
前面提到的某些特征在某些任务不好学,提出主任务和辅助任务概念,(NLP中主任务为情感预测,辅助任务为inputs是否包含积极或消极的词;)。辅助任务应该在一定程度上与主任务相关,利于主任务的学习。
多任务MLP特点总结
- 紧凑分布均匀的label的辅助任务更好
- 主任务训练曲线更快平稳,辅助任务慢
- 不同任务尺度不一样,任务最优学习率可能不同
- 某个任务的输出可以作为某些任务的输入
- 某些任务的迭代周期不同,可能需要异步训练?(后验信息;特征选择,特征衍生任务等)
- 整体loss函数可能被某些任务主导,需要整个周期对参数进行动态调整
「一个loss函数的多任务」:很多任务中把loss加到一起回传,实质优化的是一个loss函数, 但过程是多个任务,loss相加是多任务学习的一种正则策略
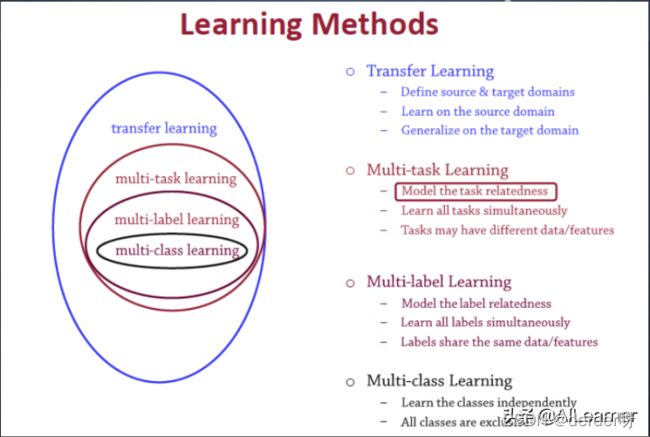
多任务学习与其他学习算法之间的关系
多任务学习(Multitask learning)是迁移学习算法的一种,迁移学习之前介绍过。定义一个一个源领域source domain和一个目标领域(target domain),在source domain学习,并把学习到的知识迁移到target domain,提升target domain的学习效果(performance)。归纳迁移
多标签学习(Multilabel learning)是多任务学习中的一种,建模多个label之间的相关性,同时对多个label进行建模,多个类别之间共享相同的数据/特征。
多类别学习(Multiclass learning)是多标签学习任务中的一种,对多个相互独立的类别(classes)进行建模。这几个学习之间的关系如图5所示:
多任务学习应用
现实生活中有很多适合多任务学习的场景,以下举例说明
(1).自然语言处理相关的研究,比如把词性标注、句子句法成分划分、命名实体识别、语义角色标注等任务放在一起研究。
(2).人脸识别中,人脸的属性的研究、人脸识别、人脸年龄预测等任务也可以通过多任务学习进行解决。
(3).图像分类,不同光照下、拍摄角度、拍摄背景下等分类任务的研究,也可以在多任务研究的框架下完成。除了上述举例的三种不同应用之外,现实生活中还有很多类似的多任务学习的例子。
https://blog.csdn.net/qq_32782771/article/details/90517443?