自然语言处理系列之:词性标注与命名实体识别
大纲
- 词性标注和命名实体识别的基础概念和常用方法
- 基于条件随机场的命名实体识别原理解析
- 日期识别和地名识别实践
4.1 词性标注
-
词性:词汇基本语法属性,也称为词类;
-
词性标注:在给定句子中判定每个词的语法范畴,确定其词性并加以标注的过程。最简单的方法是从语料库中统计每个词对应的高频词性,并将其作为默认词性;
-
词性标注规范
- 北大词性标注集;
- 宾州词性标注集;
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-YykgaAs2-1604644370579)(https://i.loli.net/2019/08/27/LQa2YqMGbN58TIs.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-KEzT7VCZ-1604644370581)(https://i.loli.net/2019/08/27/2U3ILZXxNTybcPV.png)]
- 简单Python实现
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @version : 1.0
# @Time : 2019-8-27 21:05
# @Author : cunyu
# @Email : [email protected]
# @Site : https://cunyu1943.github.io
# @File : posseg_demo.py
# @Software: PyCharm
# @Desc : 词性标注
import jieba.posseg as pesg
import glob
import random
import jieba
def posseg_test(path,posseg_path):
with open(path, 'r', encoding='gbk') as file1, open(posseg_path,'w',encoding='utf-8') as file2:
corpus = file1.readlines()
for line in corpus:
words = pesg.cut(line)
for word in words:
print(word.word + " " + word.flag)
file2.write(word.word + ' '+word.flag + '\n')
if __name__ == '__main__':
print('++++测试++++')
words = pesg.cut("词性标注是NLP中一项重要任务。")
for word in words:
print(word.word + '/' + word.flag)
print('++++验证++++')
path = './data/news/C000008/10.txt'
posseg_path = './data/posseg/posseg_result.txt'
posseg_test(path,posseg_path)
print('写入成功!')
4.2 命名实体识别
-
定义:将对特定词的识别在词汇形态处理(如汉语切分)任务中独立处理,称为命名实体识别(Named Entities Recognition,NER),分为3大类(实体类、时间类、数字类)和7小类(人名、地名、组织机构名、时间、日期、货币和百分比);
-
认为命名实体识别任务未解决的原因
- 只是在有限的文本类型(主要是新闻语料)和实体类别(主要是人名、地名)中取得一定效果;
- 评测语料较小,易产生过拟合;
- NER更加侧重于召回率,但在信息检索领域,高准确率更重要;
- 通用的识别多种类型的命名实体的系统性很差;
-
中文NER面临的难题
- 各类命名实体数量太多
- 命名实体的构成规律复杂
- 嵌套情况复杂
- 长度不确定
-
条件随机场
-
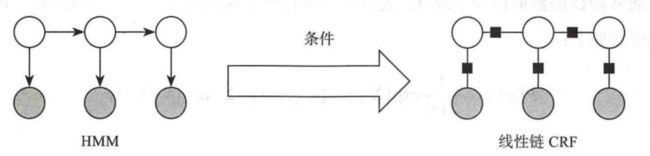
与HMM的的区别
条件随机场是在给定观察的的标记序列下,计算整个标记序列的联合概率,而HMM则是在给定当前状态下,定义下一个状态的分布;
-
定义
设 X = ( X 1 , X 2 , X 3 , … , X n ) X=(X_1,X_2,X_3,…,X_n) X=(X1,X2,X3,…,Xn)和 Y = ( Y 1 , Y 2 , Y 3 , … , Y n ) Y=(Y_1,Y_2,Y_3,…,Y_n) Y=(Y1,Y2,Y3,…,Yn)为联合随机变量,若随机变量 Y Y Y构成了一个无向图 G = ( V , E ) G=(V,E) G=(V,E)表示的马尔可夫模型,则其条件概率 P ( Y ∣ X ) P(Y|X) P(Y∣X)称为条件随机场(CRF),即
-
P ( Y v ∣ X , Y w , w ≠ v ) = P ( Y v ∣ X , Y w , w ∼ v ) P(Y_v|X,Y_w,w \not= v)=P(Y_v|X,Y_w,w \sim v) P(Yv∣X,Yw,w=v)=P(Yv∣X,Yw,w∼v)
其中 w ∼ v w \sim v w∼v表示图 G = ( V , E ) G=(V,E) G=(V,E)中与节点 v v v有边连接的所有节点, w ≠ v w \not= v w=v表示节点 v v v以外的所有节点;
-
线性链条件随机场(linear-chain Conditional Random Fields)
-
定义
设 X = ( X 1 , X 2 , X 3 , … , X n ) X=(X_1,X_2,X_3,…,X_n) X=(X1,X2,X3,…,Xn)和 Y = ( Y 1 , Y 2 , Y 3 , … , Y n ) Y=(Y_1,Y_2,Y_3,…,Y_n) Y=(Y1,Y2,Y3,…,Yn)均为线性链表示的随机变量序列,若在给定随机变量序列 X X X的条件下,随机变量序列 Y Y Y的条件概率分布 P ( Y ∣ X ) P(Y|X) P(Y∣X)构成条件随机场,且满足马尔可夫性:
-
P ( Y i ∣ X , Y 1 , Y 2 , Y 3 , … , Y n ) = P ( Y i ∣ X , Y i − 1 , Y i + 1 ) P(Y_i|X,Y_1,Y_2,Y_3,…,Y_n)=P(Y_i|X,Y_{i-1},Y_{i+1}) P(Yi∣X,Y1,Y2,Y3,…,Yn)=P(Yi∣X,Yi−1,Yi+1)
此时,称 P ( Y ∣ X ) P(Y|X) P(Y∣X)为线性链的条件随机场;

-
HMM与CRF的联系区别
- HMM是概率有向图,而CRF是概率无线图;
- HMM是生成模型,而CRF是判别模型;
- HMM求解过程可能是局部最优,而CRF可以全局最优;
- HMM会导致label bias问题,而CRF概率归一化较合理;
- HMM在处理时,每个状态依赖上一个状态,而CRF依赖于当前状态的周围节点状态;
- 日期识别
-
地名识别
-
CRF++地名识别流程
- 确定标签体系
- 语料数据处理
- 特征模板设计
- 模型训练和测试
- 模型使用
-
针对识别效果不佳的措施
- 扩展语料,改进模型。如加入词性特征,调整分词算法等;
- 整理地理位置词库。识别时,先通过词库匹配,再采用模型进行发现;
-