高保真数字人头《High-Fidelity 3D Digital Human Head Creation from RGB-D Selfies》
参考论文:
1:《High-Fidelity 3D Digital Human Head Creation from RGB-D Selfies》
目的:使用单张图片,生成图像对应的3D形象。
生动的3D形象生成的过程,主要需要生成1:3D头模,2:法线贴图,3:纹理贴图,4:各种表情系数,光照系数,pose系数等。一个头模只要3D头模和法线贴图准,就成功90%。
3D头模与系数生成
什么样的3D头模可以算之优质头模?
3D头模生成是3D形象生成的第一步,由几万个3D点云组合成的立体人头形状,如图1所示,可视化后如图2。

图1

图2
一个3D头模生成的好坏,直接看头模,只能看个大概,如果想要精确,需要可视化到不同角度的图片上,(同一个人不同角度,2D图片上脸形状以及五官点可能不一样,但在3D头模上一定是一样的,如果不一样,那这个头模生成的就不好)。
比如图3(用的同事图像做的实验,为避免侵犯别人肖像权,就删除),将此人生成好的头模,可视化到正脸,效果看着还可以,但是将其乘上对应侧脸的pose系数,转到侧脸可视化后问题就暴露,说明这个头模生成的不好。
图3
好的头模应该如图4所示,不管怎么pose系数,可视化到不同视角,都能很好的拟合轮廓。
csdnimg.cn/903bd4b3392e4400a42dc8fada203a18.png#pic_center)
图4
怎样生成优质头模?
3D 头模是怎样生成的?
s表示生成的新的3D头模,s~表示基础头模,S表示基础形状标识,是用N个人头基于PCA算出的主成分,Xshp表示需要估计的形状参数,一个1* 500的一维数组。
a 表示生成的新的颜色贴图,a~表示基础颜色贴图,A表示基础颜色标识,是用N个人头基于PCA算出的主成分,Xalb表示需要估计的颜色参数,一个1* 199的一维数组。
基础头模怎样获取
使用Artec Eva等高分辨率3D扫描仪对人头进行扫面,得到对应的3D头模,一般扫瞄N个人头得到N个头模(腾讯的N=200),然后对N个头模点求均值,得到一个基础头模。
基础形状标识怎样获取
算法讲解:1:使用200个头模作为最原始的头模集S
2: 进入外循环
2.1)从一个10000个头模集中随机不放回的抽取m=1000个头模,记做D
2.2)初始循环次数k,与头模误差均值§
3: 进入内循环
3.1)计算S的PCA,取能够代表S集99.9%的特征的前k个头模集,记做Sk
3.2) 用Sk逐一去表达D
3.3)将误差较大(超过头模误差均值§)的头模移到M集中,比如有m个
3.4)将M集中所有头模求镜像,得到2m个
3.5)求M集中所有误差的均值,更新§
3.6)将M集合并得到初始的S集中
3.7)累计迭代次数
如果§小于误差阈值thresh,结束内循环,进入外循环,再随机从9000个头模中随机挑出1000个头模进入3.
最终得到超过10000个头模的PCA.作为基础形状标识。
需要估计的形状参数Xshp获取
通过计算这5个loss,迭代训练得到P,P里面就包含500个参数的Xshp,199个参数的Xalb,27个光照系数和6个pose系数。
6个pose系数里分别包含了:[y轴平移位移,x轴平移位移,z轴平移位移,kx左右偏转幅度,ky上下偏转幅度,th缩放系数因子]
通过改变pose系数,可以改变生成3D头模的pose,如上图4所示。
1:
将原图与渲染出的图求L1范式
2:
深度图像loss,我们没有深度图像数据,这个loss没有做。
3:
分别求原图与渲染出的图的深度特征(用VGGFace模型的fc7层特征表示),然后对所有深度特征做L2范式。
4:
拟合轮廓点
腾讯这里拟合的是86个轮廓点,我们拟合的是206+86=292个轮廓点,并且动态更改拟合点的权重,即准确的点权重高,不准确的点,权重低。所以我们生成的头模形状细节会比较准。下图是我们拟合的点。
csdnimg.cn/e546d3467c6c4b7181c14b67cf52b013.png#pic_center)
5:
对形状和纹理参数进行正则化。
贴图生成
先解释几个maps:
Albedo maps :主要体现模型的纹理和颜色,叫颜色贴图
normal maps:法线贴图存储的是表面的法线方向,
UV map:"UV"这里是指u,v纹理贴图坐标的简称(它和空间模型的X, Y, Z轴是类似的)。 它定义了图片上每个点的位置的信息。这些点与3D模型是相互联系的, 以决定表面纹理贴图的位置。 UV就是将图像上每一个点精确对应到模型物体的表面. 在点与点之间的间隙位置由软件进行图像光滑插值处理。这就是所谓的UV贴图。
贴图生成主要有3个部分:
(1)生成Unwrap
(2)区域拟合
(3)使用pix2pix精细化贴图
下面分别从这3部分逐一讲解。
Unwrap 怎么得到?即如何把3D模型展开为一张2D贴图?
这个论文里没有细讲,需要自己网上找资料,再结合官方源码看。
理论:使用纹理坐标UV作为顶点的屏幕位置(把[0,1]范围的纹理坐标重映射为[-1,1]范围的规范化的位置坐标)。要注意的是模型的UV映射必须要好,即在纹理上的每个点必须映射为模型上的唯一点,不能重叠。然后以3D模型每个像素的颜色来对展开的网格进行着色,就会得到展开后的2D贴图。
总结来说,大致就是拆分网格,创建平面映射,展开UV网格,网格着色等。
上主要代码:
一张正脸的情况:
实现步骤:
1:用头模几何体(x,y)轴定点,vt贴图坐标点,和v法线定点,将上一步得到的头模展开,得到uv坐标点位置,展开的贴图大小即uv的大小。
2:将原图resize到同uv_map 同样的尺寸,然后通过位置索引,对每一uv坐标点像素着色。
3:用基础uv_map,与上一步得到的uv_map做图像拉普拉斯金字塔融合 ,得到最终的Unwrap。
多张图情况(eg:一张正脸,加左右两个侧脸):
实现步骤:
1:分别对三张图计算上面的1,2步,得到3个视角的uv_map。
2:将上一步得到的uv_map与下面对应的mask想融合后,再叠加。
3:最后基础uv_map,与叠加后的uv_map和下面三个mask叠加再归一到[0,1]做图像拉普拉斯金字塔融合 ,得到最终的Unwrap。
区域拟合细节
在区域拟合过程中,会用到区域金字塔结果,所以讲区域拟合细节之前,先把区域金字塔介绍一遍,下图是区域金字塔整个过程。
用一种基于金字塔的参数表达,来合成高分辨率颜色贴图和法线贴图
构建金字塔算法的过程:
1):将200个颜色贴图resize到(512512和20482048两种分辨率),
2):将脸部区域化为为8个区域,在如下UV图种用不同颜色表示
3):这样每个样本组成3元组,k表示8个区域种的一块区域。
4):将3元组向量化连接在一起成一维向量,并计算PCA,得到其主成分。
5):将4)得到的主成分根据indices散布到新向量中,得到k区域的金字塔特征。
区域拟合细节
区域拟合有2个部分:
1:参数拟合
2:高分辨率贴图合成
首先讲参数拟合,下面的公式就是参数拟合:
先解释上面公式中的几个变量含义:

:上一步生成的unwrap 。
表示将生成头模过程中生成的粗略的颜色贴图参数,与区域金字塔生成的A512(512* 512分辨率的颜色贴图基地)逐区域相乘拟合再叠加成一张总的颜色贴图。
实现步骤:
1:计算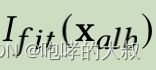
与
之间的l2范式,记做loss1;
2: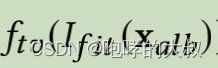
主要消除8个区域边界中的伪影。做法是:通过uv_mask将整个颜色贴图分割成边界mask和非边界mask,然后分别计算颜色贴图中的边界距离和非边界距离,将这两种距离相加。记做loss2
3:对这步中的颜色贴图参数Xalb做L2正则,记做loss3
4:将上面3种loss相加,L=loss1+loss2+loss3
5:通过最小化总loss L,迭代更新颜色贴图参数Xalb,直到得到训练好的Xalb。
这里的步骤1-5,就是上图中的参数拟合部分,就是将生成头模的时候生成的粗略化的Xalb,通过最小化loss,迭代训练得到较优的Xalb。
接下来介绍高分辨率贴图合成。
6: 将上部分得到的较优的Xalb,分别与区域金字塔生成的A2048(2048* 2048分辨率的颜色贴图基地)逐区域相乘拟合再叠加成一张总的颜色贴图,这便是区域拟合部分得到的最终的颜色贴图。
7: 将上部分得到的较优的Xalb,分别与区域金字塔生成的G2048(2048* 2048分辨率的法线贴图基地)逐区域相乘拟合再叠加成一张总的法线贴图,这便是区域拟合部分得到的最终的法线贴图。
颜色贴图和法线贴图合成细节
使用两个基于GAN的网络合成细节
3.1)由上一步得到最初颜色贴图,叫unwrap uv,与mask uv
| 
| 
|
|–|–|
| | |
3.2)通过金字塔特征逐区域拟合,得到fit_unwrap map,左边是细节化的颜色贴图,右边是生成的法线贴图。
|
| 
|
|–|–|
| | |
3.3)用fit_unwrap map为输入,通过GAN(pix2pix网络)得到同分辨率更精细化的颜色贴图和法线贴图。(pix2pix是2017年发表在CVPR,将GAN应用于有监督的图像到图像翻译的经典论文)这个博友对pix2pix算法做了详细讲解:https://blog.csdn.net/u014380165/article/details/98453672
3.3.1)对于颜色贴图生成:
输入:上一步得到的2048* 2048比较粗糙的颜色贴图
输出:比较精细化的2048* 2048的颜色贴图
3.3.2)对于法线贴图生成:
输入:将这一步得到的精细化的颜色贴图与上一步得到的比较粗糙的法线贴图沿通道维度拼接作为输入
输出:精细化的2048* 2048的法线贴图
|
| 
|
|–|–|
| | |
总流程为: