数字识别篇 (一) : 了解数据和处理数据
房地产不太景气
在每次开始之前都需要先运行以下代码,不报错方可继续
# Python 的版本需要大于3.5
import sys
assert sys.version_info >= (3, 5)
# Scikit-Learn的版本需要大于0.20
import sklearn
assert sklearn.__version__ >= "0.20"
import numpy as np
import os
#绘图设置
%matplotlib inline
import matplotlib as mpl
import matplotlib.pyplot as plt
mpl.rc('axes', labelsize=14)
mpl.rc('xtick', labelsize=12)
mpl.rc('ytick', labelsize=12)
所以我们换了一份工作,现在这家公司在开发一款手机手写输入法,我们负责数字的部分
假设负责数据收集的同事已经将收集好的一些手写数字图片打包上传好了,让我们下载下来
现在可以开始尝试理解这部分代码了,尤其建议和加州房价篇中的这部分代码对比理解
import os
import zipfile
import urllib.request
DOWNLOAD_ROOT = "https://dayangai.coding.net/p/dayangai/d/dayangai/git/raw/master/"
DIGIT_PATH = os.path.join("datasets", "digit")
DIGIT_URL = DOWNLOAD_ROOT + "datasets/digit/digit.zip"
def fetch_digit_data(digit_url=DIGIT_URL, digit_path=DIGIT_PATH):
if not os.path.isdir(digit_path):
os.makedirs(digit_path)
zip_path = os.path.join(digit_path, "digit.zip")
opener = urllib.request.URLopener() #opener这三行代码现在可以不用理解,主要作用是将数据下载下来
opener.addheader('User-Agent', 'whatever')
opener.retrieve(digit_url, zip_path)
digit_zip = zipfile.ZipFile(zip_path)
digit_zip.extractall(path=digit_path)
digit_zip.close()
fetch_digit_data()
import pandas as pd
def load_digit_data(digit_path=DIGIT_PATH):
csv_path = os.path.join(digit_path, "digit.csv")
return pd.read_csv(csv_path)
digit = load_digit_data()
这样整个数据集就加载到digit里了
黑白图片一般由若干个像素点组成,每个像素点由一个0-255的数字控制,数字越大,这个像素点就越黑
我们来看看
digit.head()
输出:

digit.info()
输出:

784个像素点,加一个数字类别,也就是784个特征加一个目标(target),而且全是数字(int),不用处理,完美!
先把类别分离出来
digit_target = digit["class"].copy()
digit = digit.drop("class", axis=1)
我们问了一下同事,同事回答说每张原图片都是正方形,也就是28 x 28的图片(28 x 28=784),不过他已经帮我们整理好了,现在是1 x 784,方便我们
训练模型,所以如果我们想看看图片,得用reshape来还原,就选第一张吧(housing.values[0])
#这里可以注意一下加了values之后的类型,为什么要加values?
import matplotlib as mpl
from pylab import *
mpl.rcParams['font.sans-serif'] = ['SimHei']
import matplotlib.pyplot as plt
plt.imshow(digit.values[0].reshape(28,28), cmap="binary")
plt.axis("off")
plt.show()
输出:

还不赖,是个5,看看digit_target这边是不是对的上
digit_target[0]
输出:
5
数据处理:数据增强(Data Augmentation)
在实际的生产活动中,机器学习应用的难点往往不是模型的选择和训练,而是数据难以收集,所以我们要尽最大努力利用好收集到的数据,对于不同的任务,数据增强的方法也各不相同,所以我们必须因地制宜,
对于目前的数字识别任务来说,我们可以把每个数字分别向上,下,左,右四个不同的方向平移一段距离,形成新的图片,这样我们的数据集一下就翻了四倍,不要小看这样的移动,因为在原数据集中每个数字都是居中的,还记得我们在加州房价篇提到过的过度拟合吗(overfit),如果仅在原数据集上训练,我们的模型很有可能无法识别不居中的数字,
不要认为这样的扩展降低了数据集的质量,虽然在人眼看来如此,但实际上像素的位置是发生了巨大变化的
数据增强既能避免过度拟合,又能扩展有限的数据集,可谓两全其美,妙哉!
我们看看怎么做
from scipy.ndimage.interpolation import shift
def shift_image(image, dx, dy):
image = image.reshape((28, 28))
shifted_image = shift(image, [dy, dx], cval=0, mode="constant")
return shifted_image.reshape([-1])#返回1 x 784的图片
图片数据增强的函数定义好了,拿第一个图片看看效果
image = digit.values[0]
shifted_image_down = shift_image(image, 0, 5)
shifted_image_left = shift_image(image, -5, 0)
# subplot是为了能在同一代码格中输出多个图片
plt.figure(figsize=(12,3))
plt.subplot(131)
plt.title("原来的", fontsize=14)
plt.imshow(image.reshape(28, 28), cmap="binary")
plt.subplot(132)
plt.title("向上", fontsize=14)
plt.imshow(shifted_image_down.reshape(28, 28), cmap="binary")
plt.subplot(133)
plt.title("向左", fontsize=14)
plt.imshow(shifted_image_left.reshape(28, 28), cmap="binary")
plt.show()
输出:
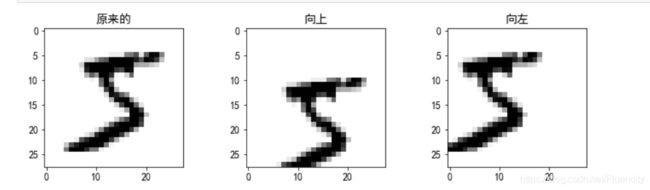
没毛病,我们全部转换好
#想一想为什么这里需要用list绕一下,而不能直接用dataframe或者dataframe.values
X_train_augmented = [image for image in digit.values]
y_train_augmented = [label for label in digit_target.values]
for dx, dy in ((1, 0), (-1, 0), (0, 1), (0, -1)):
for image, label in zip(digit.values, digit_target.values):# zip 可以把两者放一起循环遍历
X_train_augmented.append(shift_image(image, dx, dy))
y_train_augmented.append(label)
X_train_augmented = np.array(X_train_augmented)
y_train_augmented = np.array(y_train_augmented)
现在数据集的类型是array,而不是dataframe,不过不影响我们之后的训练,因为dataframe主要是用来查看数据集的特点的,在我们了解并处理好了数据集之后,可以直接用array来训练
好了,这个关于数据我们就处理好了,数字识别是分类问题,而房价预测是回归问题,二者最大的区别在于如何计算模型的误差,在房价预测里我们使用的是均方根误差,
而对于一个分类问题,我们该使用什么呢,我们在下一个部分着重讨论
对应视频
转载请注明出处