【PyTorch】Training Model
文章目录
- 七、Training Model
-
- 1、模型训练
- 2、GPU训练
-
- 2.1 .cuda()
- 2.2 .to(device)
- 2.3 Google Colab
- 3、模型验证
七、Training Model
1、模型训练
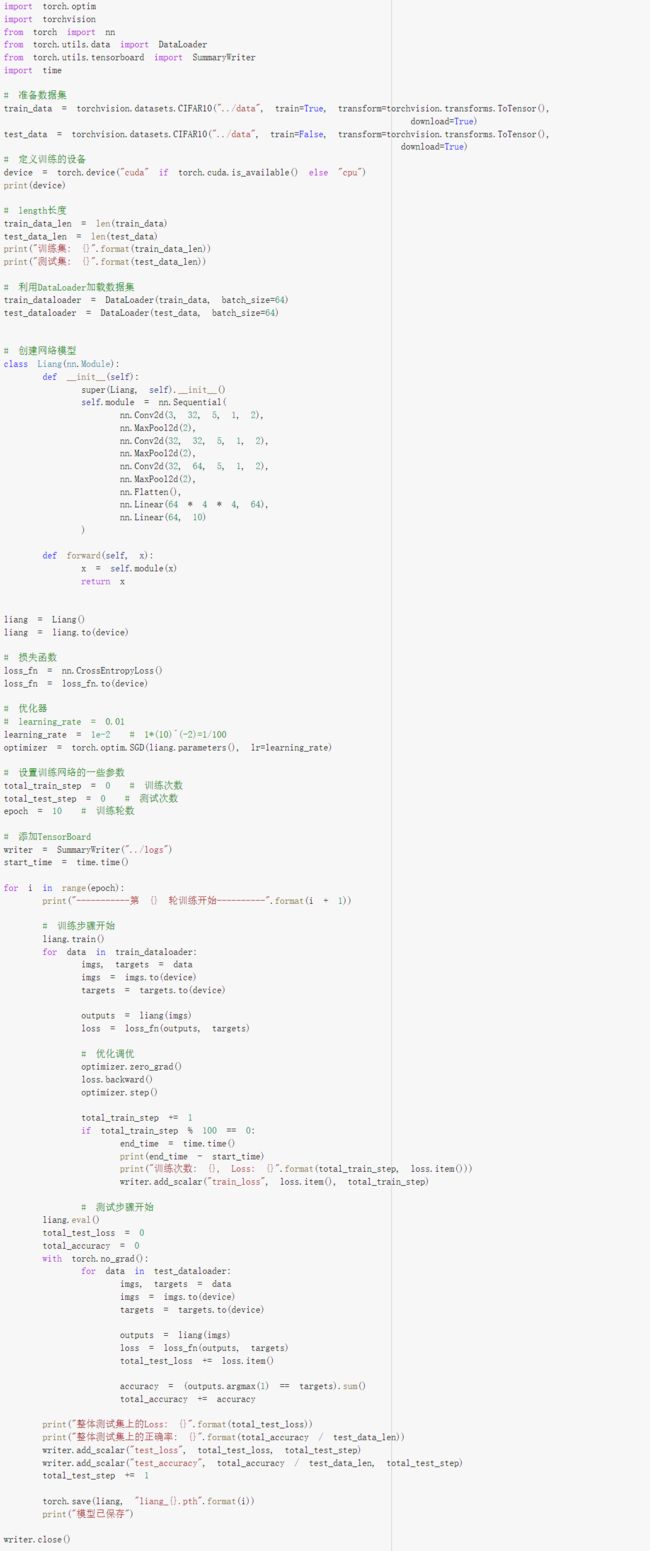
以CIFAR10数据集为例:
import torchvision
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
import time
from Model import *
# 准备数据集
train_data = torchvision.datasets.CIFAR10("../data", train=True, transform=torchvision.transforms.ToTensor(),
download=True)
test_data = torchvision.datasets.CIFAR10("../data", train=False, transform=torchvision.transforms.ToTensor(),
download=True)
# length长度
train_data_len = len(train_data)
test_data_len = len(test_data)
print("训练集: {}".format(train_data_len))
print("测试集: {}".format(test_data_len))
# 利用DataLoader加载数据集
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
# 创建网络模型
liang = Liang()
# 损失函数
loss_fn = nn.CrossEntropyLoss()
# 优化器
# learning_rate = 0.01
learning_rate = 1e-2 # 1*(10)^(-2)=1/100
optimizer = torch.optim.SGD(liang.parameters(), lr=learning_rate)
# 设置训练网络的一些参数
total_train_step = 0 # 训练次数
total_test_step = 0 # 测试次数
epoch = 10 # 训练轮数
# 添加TensorBoard
writer = SummaryWriter("../logs")
start_time = time.time()
for i in range(epoch):
print("-----------第 {} 轮训练开始----------".format(i + 1))
# 训练步骤开始
liang.train()
for data in train_dataloader:
imgs, targets = data
outputs = liang(imgs)
loss = loss_fn(outputs, targets)
# 优化调优
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_train_step += 1
if total_train_step % 100 == 0:
end_time = time.time()
print(end_time - start_time)
print("训练次数: {}, Loss: {}".format(total_train_step, loss.item()))
writer.add_scalar("train_loss", loss.item(), total_train_step)
# 测试步骤开始
liang.eval()
total_test_loss = 0
total_accuracy = 0
with torch.no_grad():
for data in test_dataloader:
imgs, targets = data
outputs = liang(imgs)
loss = loss_fn(outputs, targets)
total_test_loss += loss.item()
accuracy = (outputs.argmax(1) == targets).sum()
total_accuracy += accuracy
print("整体测试集上的Loss: {}".format(total_test_loss))
print("整体测试集上的正确率: {}".format(total_accuracy / test_data_len))
writer.add_scalar("test_loss", total_test_loss, total_test_step)
writer.add_scalar("test_accuracy", total_accuracy / test_data_len, total_test_step)
total_test_step += 1
torch.save(liang, "../model/liang_{}.pth".format(i))
print("模型已保存")
writer.close()
Files already downloaded and verified
Files already downloaded and verified
训练集: 50000
测试集: 10000
-----------第 1 轮训练开始----------
6.537519931793213
训练次数: 100, Loss: 2.288882255554199
13.001430749893188
训练次数: 200, Loss: 2.271170139312744
19.13790225982666
训练次数: 300, Loss: 2.247511148452759
25.20561981201172
训练次数: 400, Loss: 2.168041706085205
31.378580570220947
训练次数: 500, Loss: 2.049440383911133
37.541871309280396
训练次数: 600, Loss: 2.054497241973877
43.90901756286621
训练次数: 700, Loss: 1.9997793436050415
整体测试集上的Loss: 309.624484539032
整体测试集上的正确率: 0.2912999987602234
模型已保存
...
2、GPU训练
将 神经网络、损失函数、数据 转为 cuda(GPU型) 执行,我们可以发现,速度明显比CPU执行的快很多!
2.1 .cuda()
# 神经网络
liang = Liang()
if torch.cuda.is_available():
liang = liang.cuda()
# 损失函数
loss_fn = nn.CrossEntropyLoss()
if torch.cuda.is_available():
loss_fn = loss_fn.cuda()
# 数据
imgs, targets = data
if torch.cuda.is_available():
imgs = imgs.cuda()
targets = targets.cuda()
Files already downloaded and verified
Files already downloaded and verified
训练集: 50000
测试集: 10000
-----------第 1 轮训练开始----------
10.994545936584473
训练次数: 100, Loss: 2.2849647998809814
12.99094533920288
训练次数: 200, Loss: 2.2762258052825928
14.33635950088501
训练次数: 300, Loss: 2.230626106262207
16.00475764274597
训练次数: 400, Loss: 2.1230242252349854
17.964726209640503
训练次数: 500, Loss: 2.022688150405884
19.61249876022339
训练次数: 600, Loss: 2.01230788230896
20.96266460418701
训练次数: 700, Loss: 1.9741096496582031
整体测试集上的Loss: 305.68632411956787
整体测试集上的正确率: 0.29739999771118164
模型已保存
...
2.2 .to(device)
# 定义训练的设备
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(device)
# 神经网络
liang = Liang()
liang = liang.to(device)
# 损失函数
loss_fn = nn.CrossEntropyLoss()
loss_fn = loss_fn.to(device)
# 数据
imgs, targets = data
imgs = imgs.to(device)
targets = targets.to(device)
Files already downloaded and verified
Files already downloaded and verified
cuda
训练集: 50000
测试集: 10000
-----------第 1 轮训练开始----------
9.563657283782959
训练次数: 100, Loss: 2.2956345081329346
10.768706560134888
训练次数: 200, Loss: 2.2770333290100098
11.968295335769653
训练次数: 300, Loss: 2.26665997505188
13.181000471115112
训练次数: 400, Loss: 2.2037200927734375
14.387518167495728
训练次数: 500, Loss: 2.0665152072906494
15.585152387619019
训练次数: 600, Loss: 2.0054214000701904
16.81506586074829
训练次数: 700, Loss: 2.0446667671203613
整体测试集上的Loss: 320.6275497674942
整体测试集上的正确率: 0.2667999863624573
模型已保存
...
2.3 Google Colab
我们可以借助Google提供的Colab来进行GPU训练:https://colab.research.google.com/ (需要VPN)
在Colab中如果想要使用GPU进行训练,需要在笔记本设置中选择GPU。

明显快好多!!!
3、模型验证
import torch
import torchvision
from PIL import Image
from torch import nn
image_pth = "../images/dog.jpg"
image = Image.open(image_pth)
print(image)
transform = torchvision.transforms.Compose([torchvision.transforms.Resize((32, 32)),
torchvision.transforms.ToTensor()])
image = transform(image)
print(image.shape)
class Liang(nn.Module):
def __init__(self):
super(Liang, self).__init__()
self.module = nn.Sequential(
nn.Conv2d(3, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 5, 1, 2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(64 * 4 * 4, 64),
nn.Linear(64, 10)
)
def forward(self, x):
x = self.module(x)
return x
model = torch.load("../model/liang_4.pth")
print(model)
image = torch.reshape(image, (1, 3, 32, 32))
print(image.shape)
model.eval()
image = image.cuda()
with torch.no_grad():
output = model(image)
print(output)
print(output.argmax(1))
<PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=300x200 at 0x19E66C68100>
torch.Size([3, 32, 32])
Liang(
(module): Sequential(
(0): Conv2d(3, 32, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(1): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(2): Conv2d(32, 32, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(3): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(4): Conv2d(32, 64, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(5): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(6): Flatten(start_dim=1, end_dim=-1)
(7): Linear(in_features=1024, out_features=64, bias=True)
(8): Linear(in_features=64, out_features=10, bias=True)
)
)
torch.Size([1, 3, 32, 32])
tensor([[-0.8167, -2.1763, 1.3891, 0.7956, 1.2035, 1.8374, -0.7936, 1.7908,
-2.0639, -1.4441]], device='cuda:0')
tensor([5], device='cuda:0')