2022 APMCM亚太数学建模竞赛 C题 全球是否变暖 问题二python代码实现(更新完毕)

更新信息
2022-11-24 10:00 更新问题1和问题2 思路
2022-11-24 23:20 更新问题一代码
2022-11-25 11:00 更新问题二代码
相关链接
【2022 APMCM亚太数学建模竞赛 C题 全球是否变暖 问题一python代码实现】
【2022 APMCM亚太数学建模竞赛 C题 全球是否变暖 问题二python代码实现】
【代码及建模方案下载】
方法一:私信我
方法二:https://gitee.com/liumengdemayun/BetterBench-Shop
1 分析经纬度与气温的关系
import pandas as pd
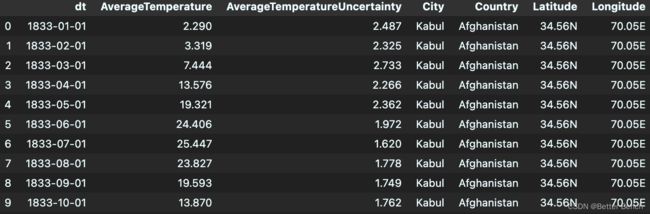
data = pd.read_csv('*.csv')
data.head(10)
只选择2013年全球的平均气温来分析
data['dt'] = pd.to_datetime(data['dt'])
data.index = data['dt']
data['Year'] = data['dt'].dt.year
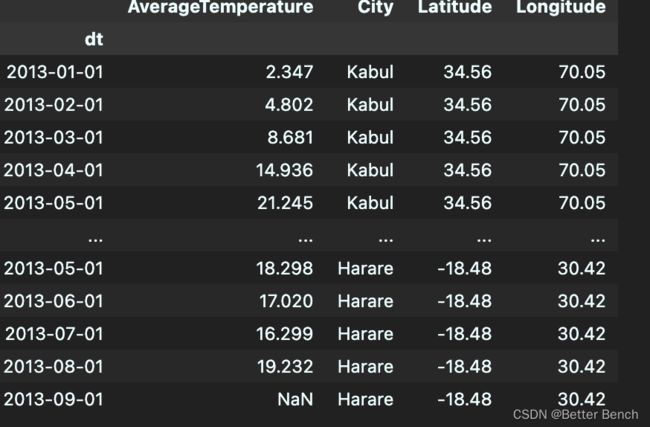
data_2013 = data[data['Year']==2013][['AverageTemperature','City','Latitude','Longitude']]
data_2013

北纬和南纬,东经和西经,分别用正负表示
def clear_Latitude(s):
if 'N' in s:
return float(s.replace('N',''))
else:
return -float(s.replace('S',''))
def clear_Longitude(s):
if 'E' in s:
return float(s.replace('E',''))
else:
return -float(s.replace('W',''))
data_2013['Latitude'] = data_2013['Latitude'].apply(clear_Latitude)
data_2013['Longitude'] = data_2013['Longitude'].apply(clear_Longitude)
data_2013
按城市分组
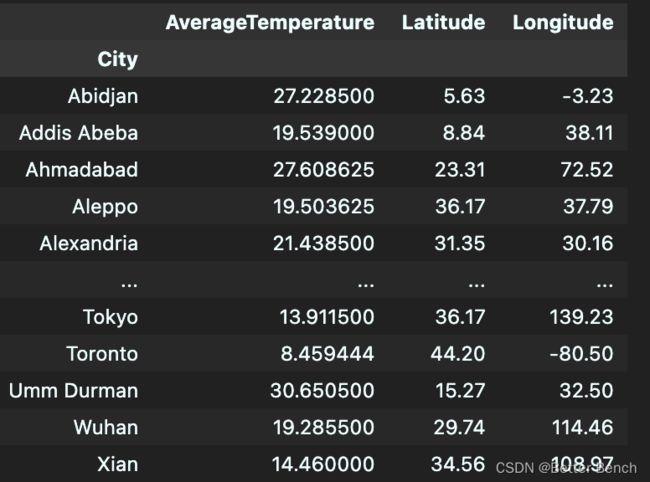
city_data_df = data_2013.groupby('City').mean()
city_data_df
分析经纬度与温度的相关性
import matplotlib.pyplot as plt
import seaborn as sns
f, ax = plt.subplots(nrows=1, ncols=1, figsize=(8, 8))
df = city_data_df
shifted_cols = df.columns
corrmat = df[shifted_cols].corr()
sns.heatmap(corrmat, annot=True, vmin=-1, vmax=1, cmap='coolwarm_r')
ax.set_title('经纬度与温度的全年平均气温相关性', fontsize=16)
plt.tight_layout()
plt.savefig('问题二/img/经纬度与温度的全年平均气温相关性.png',dpi=300, bbox_inches = 'tight')
plt.show()

多元线性回归
# from statsmodels.formula.api import ols
import statsmodels.api as sm
Y= city_data_df['AverageTemperature']
X1 = city_data_df.drop(columns=['AverageTemperature'])
X= sm.add_constant(X1)
result = sm.OLS(Y,X).fit()
result.summary()
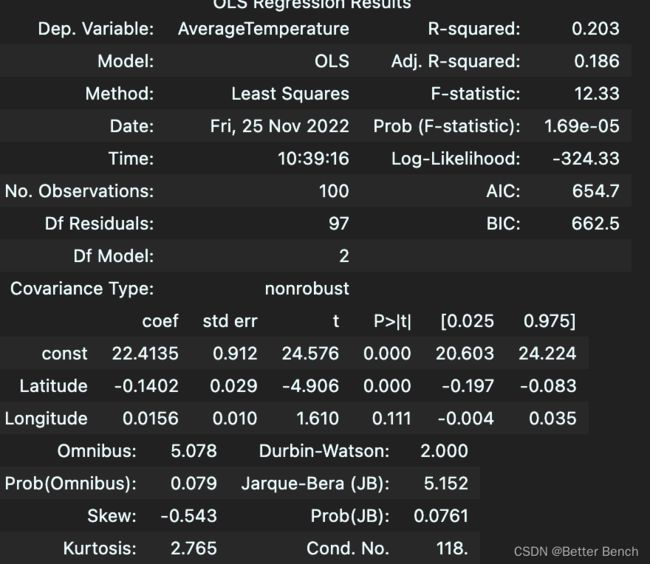
重点关注几个参数
- R-squared(R方):该值说明了方程的拟合好坏,R平方=0.80非常不错了,说明:
1)总体满意度的80%的变差都可以由7个分项指标解释,或者说,7个分项指标可以解释总体满意度80%的变差!
2)R平方如果太大,大家不要高兴太早,社会科学很少有那么完美的预测或解释,一定存在了共线性!
-
p>|t|:说明发生了小概率事件,拒绝原假设。可以看到都是0,说明不拒绝原假设。原假设是平均气温与经纬度存在多元线性相关。
-
coef是系数:说明多元性线性回归方程式 AverageTemperature = (-0.1402)*Latitude+(0.0156)*Longitude +22.4135
2 分析气温与时间的关系
(1)获取北京的数据
China_data = pd.read_csv('clear_China_city_AvgTemperature.csv')
China_data.head(10)
China_data.index =pd.to_datetime(China_data['date'])
Beijing_data = China_data[China_data['City'] == 'Beijing']
import numpy as np
Beijing_data['AvgTemperature'][Beijing_data['AvgTemperature']<-18]=np.nan
# 使用垂直方向的向前填充去填充空值
Beijing_data = Beijing_data.fillna(method = 'ffill',axis=0)
Beijing_data.AvgTemperature.plot(figsize=(20, 5))
plt.xlabel('Average Temperature')
plt.title('Average Temperature in Beijing')
plt.savefig('问题二/img/北京历史气温.png',dpi=300, bbox_inches = 'tight')
plt.show()
(2)季节性分解
from statsmodels.tsa.seasonal import seasonal_decompose
# 由于我们处理的是持续数年的每日数据,我们可以认为季节性成分每 365 天重复一次,因此我们将周期设置为 365。
decomposition = seasonal_decompose(Beijing_data['AvgTemperature'], model='additive', period=365, extrapolate_trend='freq')
fig, axs = plt.subplots(4, figsize=(12, 6))
fig.suptitle('Time series decomposition')
decomposition.observed.plot(ax=axs[0])
decomposition.trend.plot(ax=axs[1])
decomposition.seasonal.plot(ax=axs[2])
decomposition.resid.plot(ax=axs[3])
axs[0].set_ylabel('Observed')
axs[1].set_ylabel('Trend')
axs[2].set_ylabel('Seasonal')
axs[3].set_ylabel('Residual')
plt.subplots_adjust( hspace=1 )
plt.savefig('问题二/img/季节性分解.png',dpi=300, bbox_inches = 'tight')

我们应该验证残差是白噪声(其要求与平稳性的要求一致)。 我们可以使用 Augmented Dickey-Fuller Test 来检查平稳性。
from statsmodels.tsa.stattools import adfuller
adf_test = adfuller(decomposition.resid)
print(f"p-value = {adf_test[1]}")
# p-value = 2.5687430940547997e-17
得到的 p 值接近0.0,低于我们的显着性水平 (0.05)。 因此,我们可以拒绝零假设(H₀:时间序列是非平稳的),这对我们来说意味着我们的时间序列可以被认为是白噪声。