tensorflow2 minist手写数字识别数据训练
✨ 博客主页:小小马车夫的主页
✨ 所属专栏:Tensorflow

文章目录
- 前言
- 一、tenosrflow minist手写数字识别代码
- 二、输出
- 三、参考资料
- 总结
前言
刚开始学习tensorflow, 首先接触的是minist手写数字识别,用的梯度下降算法,记录一下以备后续复习和供其他初学者参考,如有错误请不吝指正,万分感谢。
环境:
- python 3.9.13
- Tensorflow 2.11.0
- Tensorboard 2.11.0
一、tenosrflow minist手写数字识别代码
将说明加在代码注释,方便查看复习。
import tensorflow as tf
from tensorflow import keras
from keras import layers, optimizers, datasets
#加载minist数据集,分成训练集和测试集,每个样本包含图像和标签
(x, y), (x_val, y_val) = datasets.mnist.load_data()
print('datasets', x.shape, y.shape, x.min(), y.min())
#训练集图像数据归一化到0-1之前
x = tf.convert_to_tensor(x, dtype=tf.float32) / 255.
#构建数据集对象
db = tf.data.Dataset.from_tensor_slices((x, y))
#批量训练,并行计算一次32个样本、所有数据集迭代20次
db = db.batch(32).repeat(10)
#构建Sequential窗口,一共3层网络,并且前一个网络的输出作为后一个网络的输入
model = keras.Sequential([
layers.Dense(256, activation='relu'),
layers.Dense(128, activation='relu'),
layers.Dense(10)
])
#指定输入大小
model.build(input_shape=(None, 28*28))
#打印出网络的结构和参数量
model.summary()
#optimizers用于更新梯度下降算法参数,0.01为学习率
optimizer = optimizers.SGD(lr=0.01)
#准备率
acc_meter = keras.metrics.Accuracy()
#创建参数文件
summary_writer = tf.summary.create_file_writer('/Users/qcr/tf_log')
#循环数据集
for step, (xx, yy) in enumerate(db):
#上下文
with tf.GradientTape() as tape:
#图像样本大小重置(-1, 28*28)
xx = tf.reshape(xx, (-1, 28*28))
#获取输出
out = model(xx)
#实际标签转为onehot编码
y_onehot = tf.one_hot(yy, depth=10)
#计算误差
loss = tf.square(out-y_onehot)
loss = tf.reduce_sum(loss/xx.shape[0])
#更新准备率
acc_meter.update_state(tf.argmax(out, axis=1), yy)
#更新梯度参数
grads = tape.gradient(loss, model.trainable_variables)
optimizer.apply_gradients(zip(grads, model.trainable_variables))
#参数存储,便于查看曲线图
with summary_writer.as_default():
tf.summary.scalar('train-loss', float(loss), step=step)
tf.summary.scalar('test-acc', acc_meter.result().numpy(), step=step)
#tf.summary.image('val-onebyone-images', val)
if step % 1000 == 0:
print(step, 'loss:', float(loss), 'acc:', acc_meter.result().numpy())
acc_meter.reset_states()
二、输出
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense (Dense) (None, 256) 200960
dense_1 (Dense) (None, 128) 32896
dense_2 (Dense) (None, 10) 1290
=================================================================
Total params: 235,146
Trainable params: 235,146
Non-trainable params: 0
0 loss: 1.6363120079040527 acc: 0.0625
1000 loss: 0.3189510107040405 acc: 0.83390623
2000 loss: 0.2195253074169159 acc: 0.91753125
3000 loss: 0.2733377516269684 acc: 0.93
4000 loss: 0.20172631740570068 acc: 0.9415
5000 loss: 0.13919278979301453 acc: 0.94378126
6000 loss: 0.14041364192962646 acc: 0.951625
7000 loss: 0.0935342013835907 acc: 0.9514375
8000 loss: 0.1644362509250641 acc: 0.95728123
9000 loss: 0.11363211274147034 acc: 0.9559063
10000 loss: 0.15755562484264374 acc: 0.9628125
11000 loss: 0.0880645364522934 acc: 0.959375
12000 loss: 0.08858028799295425 acc: 0.9657813
13000 loss: 0.0917932391166687 acc: 0.96296877
14000 loss: 0.06503693014383316 acc: 0.9683125
15000 loss: 0.09167198836803436 acc: 0.9665625
16000 loss: 0.1386248767375946 acc: 0.96834373
17000 loss: 0.10692787915468216 acc: 0.96953124
18000 loss: 0.10871071368455887 acc: 0.9697813
误差和准确率曲线
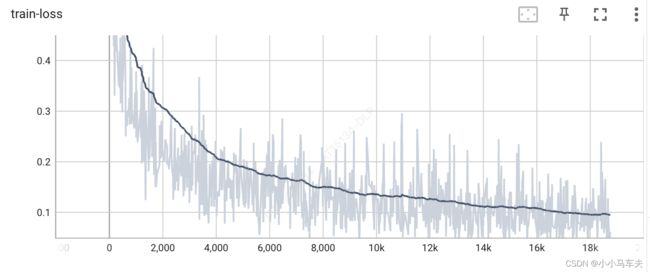

三、参考资料
[1] 《Tensorflow深度学习》
总结
以上就是本次的内容,来总结一下吧:
主要介绍了tensorflow2梯度下降算法实现minist手写数字数据集的训练,并对结果进行可视化展示。
如果觉得有些帮助或觉得文章还不错,请关注一下博主,你的关注是我持续写作的动力。另外,如果有什么问题,可以在评论区留言,或者私信博主,博主看到后会第一时间进行回复。
【间歇性的努力和蒙混过日子,都是对之前努力的清零】
欢迎转载,转载请注明出处:https://blog.csdn.net/xxm524/article/details/128054377