Deep Learning中的Attention Mechanism介绍
文章目录
-
-
- 参考文章
-
- Attention 机制的解析
-
- 1. 为什么引入attention机制?
- 2. Attention机制有哪些?
- 3. Attention机制的计算流程是怎么样?
- 4. Attention机制的变种有哪些?
-
- ①. 硬性注意力
- ②.键值对注意力
- ③. 多头注意力
- 5. 为什么自注意力模型(self-Attention model)在长距离序列中如此强大?
-
- 卷积或循环神经网络难道不能处理长距离序列吗?
- 自注意力模型(self-Attention model)
-
- 计算过程
- 6. Attention机制的应用
参考文章
目前主流的attention方法都有哪些?
目前主流的attention方法都有哪些? - JayLou娄杰的回答 - 知乎
目前主流的attention方法都有哪些? - 张戎的回答 - 知乎
模型汇总24 - 深度学习中Attention Mechanism详细介绍:原理、分类及应用
李宏毅机器学习
Attention 机制的解析
1. 为什么引入attention机制?
根据通用近似定理,前馈网络和循环网络都有很强的能力。但为什么还有引入注意力机制?
- 计算能力的限制:当要记住很多"信息",模型就要变得更复杂,然而目前计算能力依然是限制神经网络发展的瓶颈
- 优化算法的限制:虽然局部连接、权重共享以及pooling等优化操作可以让神经网络变得简单一些,有效缓解模型复杂度和表达能力之间的矛盾;但是,如循环神经网络中的长距离问题,信息“记忆”能力并不高
- 可以借助人脑信息处理信息过载的方式,例如Attention机制可以提高神经网络处理信息的能力
2. Attention机制有哪些?
当用神经网络来处理大量的输入信息的时候,可以借鉴人脑的注意力机制,只选择一些关键的信息输入进行处理来提高神经网络的效率。
按照认知神经学中的注意力,分为以下两类
1. 聚焦式(focus)注意力
- 自上而下的有意识的注意力
- 主动注意:指有预定目的、依赖任务的、主动有意识地聚焦于某一对象的注意力
2. 显著性(saliency-based)注意力
- 自下而上的有意识的注意力
- 被动注意:基于显著性的注意力是由外界刺激驱动的注意,不需要主动干预,也和任务无关
- 可以将max-pooling和门控(gating)机制来近似地看作是自下而上的基于显著性的注意力机制
在人工神经网络中,注意力机制一般就特指聚焦式注意力
3. Attention机制的计算流程是怎么样?
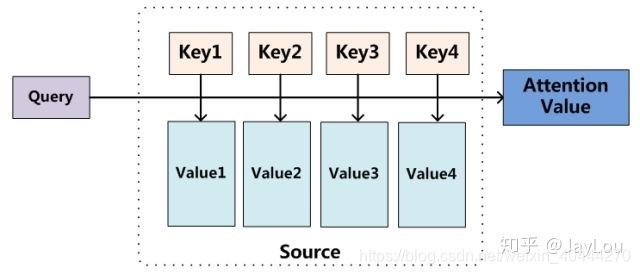
Attention机制的实质其实就是一个寻址(addressing)的过程。
如上图所示:给定一个和任务相关的查询Query向量 q q q,通过计算与Key的注意力分布并附加在Value上,从而计算Attention Value,这个过程实际上是Attention机制缓解神经网络模型复杂度的体现
不需要将所有的 N N N个输入信息都输入到神经网络进行计算,只需要从 X X X中选择一些和任务相关的信息输入给神经网络。
注意力机制分为以下三步
- 信息输入
用 X = [ x 1 , x 2 , . . . . , x N ] X = [x_1,x2,....,x_N] X=[x1,x2,....,xN]表示 N N N个输入信息 - 注意力分布计算
令Key = Value = X,则给出注意力分布
α i = s o f t m a x ( s ( k e y i , q ) ) = s o f t m a x ( s ( X i , q ) ) \alpha_i = softmax(s(key_i,q)) = softmax(s(X_i,q)) αi=softmax(s(keyi,q))=softmax(s(Xi,q))
将 α i \alpha_i αi称之为注意力分布(概率分布)
s ( X i , q ) s(X_i,q) s(Xi,q)为注意力打分机制
| 注意力打分机制 | 公式 |
|---|---|
| 加性模型 | s ( x i , q ) = v T tanh ( W x i + U q ) s(x_i,q) = v^{T}\tanh(Wx_i + Uq) s(xi,q)=vTtanh(Wxi+Uq) |
| 点积模型 | s ( x i , q ) = x i T q s(x_i,q) =x^T_iq s(xi,q)=xiTq |
| 缩放点积模型 | s ( x i , q ) = x i T q d s(x_i,q) = \frac{x^T_iq}{\sqrt{d}} s(xi,q)=dxiTq |
| 双线性模型 | s ( x i , q ) = x i T W q s(x_i,q) =x^T_i Wq s(xi,q)=xiTWq |
- 信息加权平均
注意力分布 α i \alpha_i αi可以解释为上下文查询 q q q时,第 i i i个信息受关注的程度,采用一种”软性“的信息选择机制对输入信息 X X X进行编码为:
a t t ( q , X ) = ∑ i = 1 N α i X i att(q,X) = \sum_{i=1}^N{\alpha_iX_i} att(q,X)=i=1∑NαiXi
这种编码方式为软性注意力机制(soft attention),软性注意力机制有两种:普通模型(key=value=x)和键值对模式(key!=value)
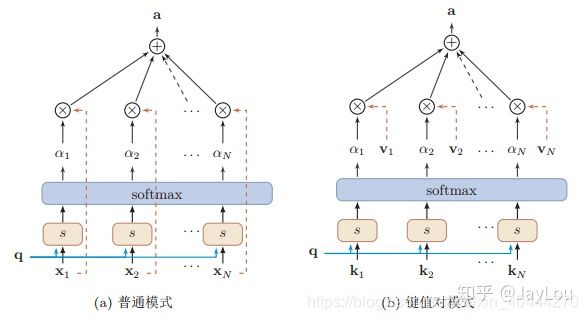
4. Attention机制的变种有哪些?
与普通的Attention机制(上图左)相比,Attention机制有哪些变种呢?
①. 硬性注意力
之前的注意力是软性注意力,其选择的信息是所有输入信息在注意力分布下的期望。
还有一种注意力是只关注到某一个位置上的信息,叫做硬性注意力(hard attention)
硬性注意力的两种实现方式:
- (1)一种是选取最高概率的输入信息
- (2)另一种是通过在注意力分布式上随机采样的方式实现
缺点 - 基于最大采样或随机采样的方式来选择信息。因此最终的损失函数与注意力分布之间的函数关系不可导,因此无法使用在反向传播算法进行训练
- 为了使用反向传播算法,一般使用软性注意力来替代硬性注意力,硬性注意力需要通过强化学习来进行训练
②.键值对注意力
即上图右边的键值对模式,此时Key!=Value,注意力函数变为
a t t ( ( K , V ) , q ) = ∑ i N a i v i = ∑ i = 1 N e x p ( s ( k i , q ) ) ∑ j e x p ( s ( k j , q ) ) v i att((K,V),q) = \sum_i^{N}a_iv_i = \sum_{i=1}^{N}\frac{exp(s(k_i,q))}{\sum_j exp(s(k_j,q))}v_i att((K,V),q)=i∑Naivi=i=1∑N∑jexp(s(kj,q))exp(s(ki,q))vi
③. 多头注意力
多头注意力(multi-head attention)是利用多个查询 Q = [ q 1 , ⋅ ⋅ ⋅ , q M ] Q = [q_1, · · · , q_M] Q=[q1,⋅⋅⋅,qM],来平行地计算从输入信息中选取多个信息。每个注意力关注输入信息的不同部分,然后再进行拼接:
a t t ( ( K , V ) , Q ) = a t t ( ( K , V ) , q 1 ) ⊕ ⋯ ⊕ a t t ( ( K , V ) , q M ) att((K,V),Q)= att((K,V),q_1) \oplus \cdots \oplus att((K,V),q_M) att((K,V),Q)=att((K,V),q1)⊕⋯⊕att((K,V),qM)
5. 为什么自注意力模型(self-Attention model)在长距离序列中如此强大?
卷积或循环神经网络难道不能处理长距离序列吗?
当使用神经网络处理一个变长的向量序列时,通常使用卷积神经网络或循环神经网络进行编码来得到一个相同长度的输出向量序列
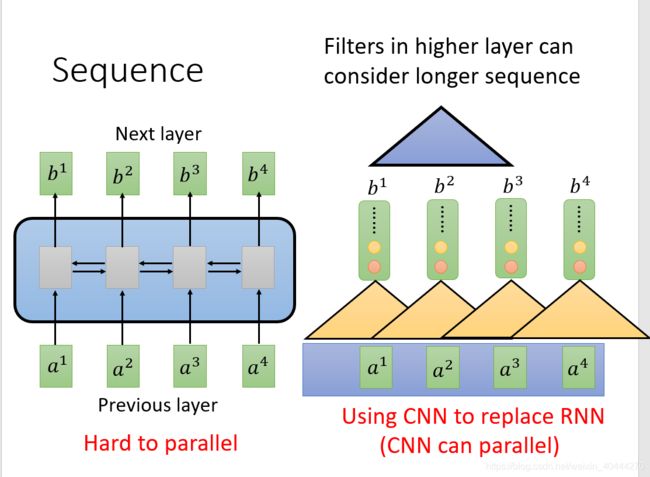
CNN与RNN存在的缺点
- RNN无法进行并行处理
- CNN可以并行处理,但是在每一层中只能兼顾部分信息,不能将输入序列全部兼顾,若想全部考虑需要更深的CNN。
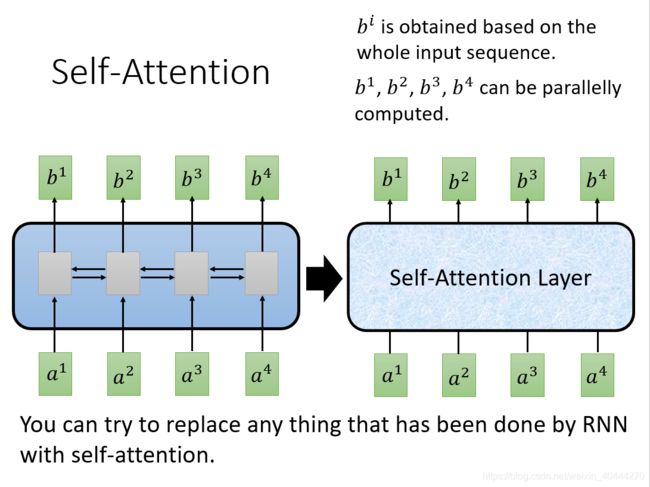
自注意力模型(self-Attention model)
self-Attention可以兼顾到whole input sequence,不再需要像左图的 L S T M LSTM LSTM一样不能并行处理, b 1 , b 2 , b 3 , b 4 b^1,b^2,b^3,b^4 b1,b2,b3,b4可以并行计算出
计算过程
这个我也没法讲清楚,直接看李宏毅视频吧
李宏毅视频
6. Attention机制的应用
Attention机制在深度学习的各种应用领域都有广泛的使用场景。从图像处理领域和语音识别选择典型应用实例来对其应用做简单说明。

图片描述(Image-Caption)是一种典型的图文结合的深度学习应用,输入一张图片,人工智能系统输出一句描述句子,语义等价地描述图片所示内容。很
明显这种应用场景也可以使用Encoder-Decoder框架来解决任务目标,此时Encoder输入部分是一张图片,一般会用CNN来对图片进行特征抽取,Decoder部分使用RNN或者LSTM来输出自然语言句子(参考图13)。
此时如果加入Attention机制能够明显改善系统输出效果,Attention模型在这里起到了类似人类视觉选择性注意的机制,在输出某个实体单词的时候会将注意力焦点聚焦在图片中相应的区域上。
图给出了根据给定图片生成句子“A person is standing on a beach with a surfboard.”过程时每个单词对应图片中的注意力聚焦区域

给出了另外四个例子形象地展示了这种过程,每个例子上方左侧是输入的原图,下方句子是人工智能系统自动产生的描述语句,上方右侧图展示了当AI系统产生语句中划横线单词的时候,对应图片中聚焦的位置区域。比如当输出单词dog的时候,AI系统会将注意力更多地分配给图片中小狗对应的位置。
