理解 Swin Transformer
引言
Vision Transformer (ViT)的提出让大家意识到 transformer 不仅在 NLP 领域表现得很好,在 CV 领域也充满了潜力,但 ViT 论文仅验证了 transformer 在图像分类任务上的性能,大家并不确定 transformer 能不能胜任其他视觉工作;同时自注意力计算方式还存在一个弊端,它的计算复杂度随输入图像尺寸呈平方增长,这严重限制了 transformer 在 CV 领域的应用场景。Swin Transformer(SwinT)应运而生,在一系列下游视觉任务中都取得了当时的 SOTA,证明了 transformer 可以很好应用到 CV 中并在一定程度上超越卷积网络。
1 动机
SwinT 的研究动机就是想证明 transformer 可以作为通用的 backbone 应用到 CV 中并超越 conv。作者在 ViT 基础上提出了将 transformer 应用于图像的两个新难点:
- 多尺度。在 NLP 中一个单词的语义是很固定的,但是图像里面 “车” 这个语义对应的图像实体具有非常多不同的尺寸;
- 高分辨率。高分辨率是指如果用像素点作为 token,序列的长度将非常大,所以相关工作要么在特征图上计算自注意力,要么将图像拆分成 patch,要么划分成一个个窗口,在窗口里面做自注意力。
SwinT 针对上述两个难点提出了自己的解决方案:
- 提出了 patch merging 操作,逐层增加每个 patch 的感受野,形成 hierarchical transformer,实现了多尺度特征提取,也因为拥有了多尺度特征,更容易应用到下游视觉任务中;
- 提出了基于 shifted windows 的自注意力计算方法,降低了序列长度,使计算复杂度随图像尺寸线性增长,同时 shifting 操作让相邻 windows 之间有了交互,间接实现了全局建模。
2 对比 SwinT 和 ViT
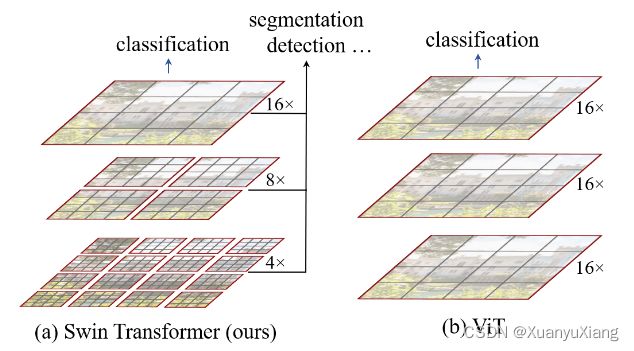
2.1 ViT
图 (b) 中的 16× 代表 16 倍下采样率,因为 ViT 的 patch size = 16 × 16,相当于每个 patch 代表的是 16× 信息,从图中可以看出,每个 patch 表征的尺寸自始至终都没有发生改变,因此 ViT 对多尺度特征的表达能力较弱。同时,ViT 的自注意力始终都在全图范围上进行计算,因此计算复杂度随图像尺寸呈平方增长。
2.2 SwinT
SwinT 借鉴了很多 conv 的设计理念和先验知识,为了降低序列长度,SwinT 在每个窗口内计算自注意力,只要窗口大小是固定的,窗口自注意力计算复杂度就是固定的,整体计算复杂度随图像大小线性增长,基于窗口的思想利用了 conv 的 locality 先验知识,即相同语义的物体大概率会出现在相同的位置。为了生成多尺度特征(在 transformer 语义中是多尺度的 patch),conv 使用了 pooling 操作,若 N × N 像素经过 pooling 后得到一个像素,那么该像素包含了前面 N × N 的信息,增大了感受野,SwinT 提出了一个类似的操作叫做 patch merging,将相邻的小 patch 合成一个大 patch,这个大 patch 包含了之前小 patch 的信息,从而使每个 patch 的感受野就变大了。
2.3 Shifted Window

SwinT 最关键的设计是 shifted window。图中每个灰色框代表一个 patch,是自注意力最基础的计算单元,红色框代表窗口,表示自注意力的计算范围(论文中默认一个 window 含有 7 × 7 个 patch)。shift 操作就是把整体窗口的排列向右下角移动了 7 / 2 向下取整个 patch。这样的好处是 window 之间有了交互,再结合 patch merging 操作,合并到最后几层时,每个 patch 本身的感受野也很大,间接实现了全局建模。
3 实现原理
3.1 整体流程

假设输入图像尺寸为 224 × 224 × 3,第一步是把图像划分成 patch(文中默认 patch size = 4 × 4),通过 Patch Partition 后得到的尺寸是 56 × 56 × 48(224 / 4 = 56,4 × 4 × 3 = 48),可以理解为序列长度是 56 × 56,每个 4 × 4 × 3 patch 被拉直成为 48 维的向量。
Stage 1 Linear Embedding 用于将每个 patch 的维度变成预先设计好的值 C,方便传递给 transformer(论文设置 C = 96),因此该层输出尺寸是 56 × 56 × 96。由于当前序列长度为 56 × 56 = 3136,对 transformer 来说计算量过大,SwinT 引入了基于 windows 的自注意力计算,单独计算每个窗口内的自注意力,每个窗口默认含有 7 × 7 = 49 个 patch(即序列长度为 49)。为了便于表述,这里先暂时把 SwinT Block 当作一个黑盒,仅关注输入输出的维度。我们知道 transformer 输入长度是多少,输出长度也是多少,因此 Stage 1 SwinT Block 的输出维度还是 56 × 56 × 96。
为了构建多尺度信息,提出了 patch merging 操作,它很像 PixelShuffle 的反过程(PixelShuffle 是 low-level 任务中常见的上采样方法)。如下图所示,假如我们需要下采样两倍,会在采样时隔一个点采一个,如图 (a) 所示,将对应的采样点组合在一起,如图 (b) 所示,将组合结果按通道维度连接起来,得到张量 H/2 × W/2 × 4C,此时长宽已经变成一半了。为了和卷积中下采样两倍通道数翻倍保持一致,© 还会通过一个 1×1 卷积得到最终的下采样结果 H/2 × W/2 × 2C。

因此通过 Stage 2 的 Patch Merging 后,尺寸从 56 × 56 × 96 变成了 28 × 28 × 192。 Stage 3 和 4 同理,最终的特征图维度是 7 × 7 × 768,经过 GAP 变成 1 × 768 维向量用于去分类。整个流程的尺寸变化规律和 conv 很相似。
3.2 Shifted Window based Self-Attention
以 Stage 1 SwinT Block 的输入 56 × 56 × 96 为例,第一个 block 首先会将该输入平均划分成无重叠的窗口,每个窗口包含 7 × 7 个 patch,每个窗口计算属于自己的自注意力,那么输入可以划分成 (56 × 56) / (7 × 7) = 64 个窗口。由于每个窗口互相不重叠,达不到全局建模的能力,第二个 block 在计算各窗口的自注意力前会把窗口整体向右下角移动 7 // 2 = 3 个 patch,实现窗口之间的交互(如 2.3 节图所示)。因此每个 Stage 中的 SwinT Block 总是以偶数的形式出现,第一个是普通划分的窗口,第二个是移动后的窗口,这样实现了层级之间窗口的交互,间接实现了全局建模。
3.3 提高移动窗口自注意力的计算效率
原始的移动窗口存在一个问题,原来只存在 4 个窗口,但是移动后变成了 9 个(如 2.3 节图所示),且每个窗口包含的 patch 数量不同,当我们想做快速运算,即把所有窗口压成一个 batch 计算时,现在就做不到了。一种简单的方式是把小窗口周围 0 padding,但这样提升了计算复杂度,因为自注意力的计算从 4 个窗口变成了 9 个窗口,增大了 2 倍多。那应该怎样才能让移位后的整体窗口数量和每个窗口内的 patch 数量保持不变呢?
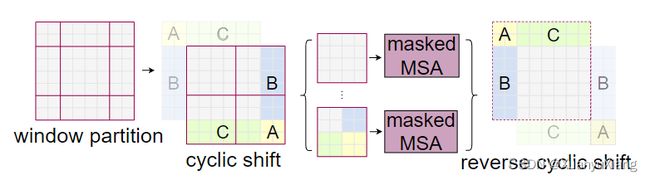
作者使用掩码 mask 巧妙解决了上述问题。如上图所示,先把原图的 A,B,C 移动到右下角,然后在移动结果上平均分割窗口,这样得到的窗口数量不变,且每个窗口内 patch 数量相同。新的问题是,例如 C 是从图像上面移到下面来的,C 和下面的 patch 之间应该没有很大的联系(例如 C 是天空,下面是地面,当移动下来以后,图像语义变成了天空在地面下方),直接计算的话会引入它们之间的联系,因此采用掩码操作避免了计算不同区域之间的自注意力。计算完成后,还需要把 A,B,C 还原到原来的位置上。接下来介绍掩码操作是如何实现的。

假设图像尺寸是 14 × 14,window size = 7 × 7,我们移动 A,B,C 后得到的结果如上图左边所示,其中 6,7 对应 C;2,5 对应 B;8 对应 A,应该相互计算自注意力的 patch 属于同一个编号。以 window2 为例,我们知道计算自注意力时会将 patch 按顺序拉直成一个一维序列,如下图所示:

其中列向量就是 Q,行向量就是 K^T,33 和 66 是应该使用的注意力权重,36 和 63 是不应该使用的注意力权重,所以作者会在 33 和 66 加上值 0,而在 36 和 63 加上值 -100,这样在进行 softmax 操作时,由于加上了 -100,softmax 结果接近于 0,相当于被 mask 掉了。
window0~3 的掩码如下图所示:

3.4 相对位置偏置
在 ViT 中,为了引入每个 patch 的位置信息,作者在每个 patch 的特征上加上了绝对位置编码,而 SwinT 作者发现使用相对位置偏置的效果更好,该偏置被加在注意力权重上,如下公式所示:
A t t e n t i o n ( Q , K , V ) = S o f t m a x ( Q K T / d + B ) V Attention(Q,K,V)=Softmax(QK^T / \sqrt{d} + B) V Attention(Q,K,V)=Softmax(QKT/d+B)V
其中 B 就是相对位置偏置。相对位置偏置是如何计算的呢?我们假设特征图尺寸是 2 × 2,那么每个像素的绝对位置索引如下:

每个像素的绝对位置索引减去其他像素的绝对位置索引得到其相对位置索引,将这 4 个相对位置索引拉直组合成一个矩阵:
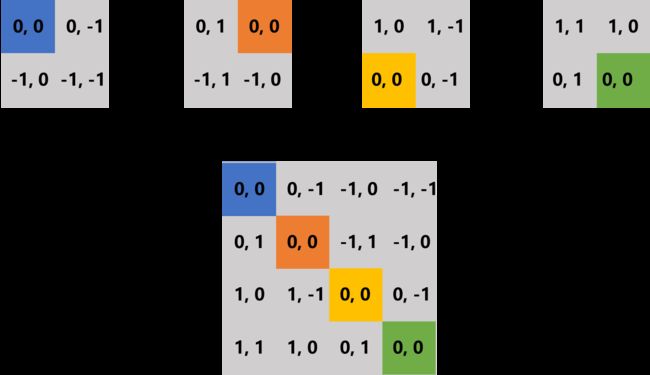
统计这个大矩阵里面的相对位置模式,发现一共有 9 种,也就是 ( 2 M − 1 ) 2 (2M - 1)^2 (2M−1)2,其中 M 是特征图边长。最后会初始化一个可学习的相对位置偏置向量,向量的维度是 ( 2 M − 1 ) 2 (2M - 1)^2 (2M−1)2 ,在前向传播的时候直接根据相对位置索引在该向量中取值即可。
现在我们希望简化对这 9 种模式的索引方式,就是将上述由两个数字表示的相对位置索引变成用一个数字表示。论文采用的方法是:先将行列索引分别加上 M − 1 M-1 M−1,然后行标加上 2 M − 1 2M-1 2M−1,最后将行列标相加,得到的就是单一数字索引。
4 总结
SwinT 的成功部分来源于引入了 conv 的设计理念,后来也有人思考,纯 conv 能不能比 transformer 做得更好?当然可以,从而又出现了类似 ConvNeXt:全面超越Swin Transformer的CNN 基于纯 conv 的工作,甚至出现了纯 MLP 网络。因此,学术就是一个圈,你不知道啥技术突然就火了。