【论文导读】CIKM2019|MIND---召回阶段的多兴趣网络模型
前言
本次分享2019年由阿里团队发表在CIKM上的论文“Multi-Interest Network with Dynamic Routing for Recommendation at Tmall”,应用胶囊网络的动态路由算法来构建一个多兴趣网络MIND,是一个召回阶段的模型。
本文约4.2k字,预计阅读15分钟。

1. 背景
文章是基于「手机天猫App」的背景来探索在十亿级别的天猫用户和商品中,给每个用户进行个性化的推荐。天猫的推荐(工业推荐)的流程主要分为「召回阶段和排序阶段」。召回阶段负责检索数千个与用户兴趣相关的候选物品,之后,排序阶段预测用户与这些候选物品交互的精确概率。「文章做的是召回阶段的工作」,来对满足用户兴趣的物品的有效检索。
1.1 多兴趣
建立「用户兴趣模型」和「寻找用户兴趣表示」是非常重要的。但在天猫塑造用户兴趣并不是一件小事,因为「用户的兴趣存在着多样性」。平均上,10亿用户访问天猫,每个用户每天与数百种产品互动。交互后的物品往往属于不同的类别,说明用户兴趣的多样性。
1.2 用户兴趣表示
基于协同过滤的方法通过历史交互物品或隐藏因子来表示用户兴趣,但会遇到「稀疏或计算问题」;
基于深度学习的方法用低维Embedding向量表示用户兴趣,但作者认为,这是「多兴趣表示的一个瓶颈」,因为不得不去压缩所有与用户多兴趣相关的的所有信息到一个表示向量,所有关于用户多兴趣的所有信息是混合在一起的,导致召回阶段的物品检索不准确。除非维度特别大,才能表示大量的兴趣信息(而维度一般会选择较小的值:8,16,32等);
DIN在Embedding的基础上加入Attention,来捕捉用户兴趣的多样性。但采用Attention机制,「对于每一个目标物品,都需要重新计算用户表示」,因此无法应用在召回阶段(DIN属于CTR模型);
1.3 胶囊网络
Hinton在2011年首次提出了“胶囊”的概念,“胶囊”是一组聚合起来输出整个向量的小神经元。采用动态路由代替反向传播来学习胶囊之间的连接权值,并利用期望最大化算法(EM)对其进行改进,克服了一些不足,获得了更好的精度。
对于胶囊网络和动态路由学习有帮助的博客:
【论文导读】浅谈胶囊网络与动态路由算法
https://medium.com/ai%C2%B3-theory-practice-business/understanding-hintons-capsule-networks-part-i-intuition-b4b559d1159b
https://medium.com/ai%C2%B3-theory-practice-business/understanding-hintons-capsule-networks-part-ii-how-capsules-work-153b6ade9f66
https://medium.com/ai%C2%B3-theory-practice-business/understanding-hintons-capsule-networks-part-iii-dynamic-routing-between-capsules-349f6d30418
2. 主要贡献
文章关注的是在召回阶段用户的多兴趣的问题,提出了使用「动态路由的多兴趣网络(MIND)」 来学习用户表示。
最主要的「创新点」是:采用胶囊网络的动态路由算法来获得用户多兴趣表示,将用户的历史行为聚集成多个集合内容,每一组历史行为进一步用于推断对应特定兴趣的用户表示向量。这样,对于一个特定的用户,MND输出了多个表示向量,它们共同代表了用户的不同兴趣。「用户表示向量只计算一次」(与DIN比较理解),可用于在匹配阶段从十亿个尺度的物品中检索相关物品。
3. MIND模型
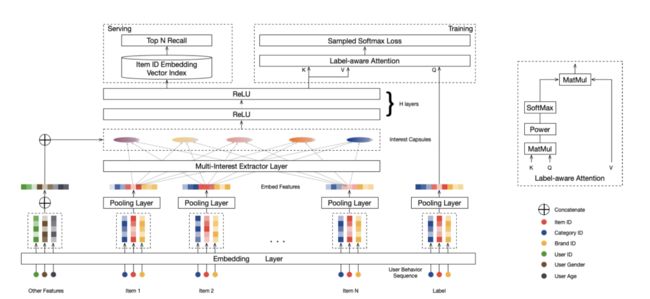
3.1 问题表示
一篇足够优秀的论文,都会有对整篇论文研究的问题进行公式化描述。
3.1.1 任务目标
召回任务的目标是对于每一个用户 从十亿规模的物品池 检索出包含与用户兴趣相关的上千个物品集。
3.1.2 输入内容
对于模型,每个样本的输入可以表示为一个三元组: ,其中 代表与用户 交互过的物品集,即用户的历史行为; 表示用户的属性,例如性别、年龄等; 定义为目标物品 的一些特征,例如物品id和种类id等。
3.1.3 核心任务
MIND的核心任务是学习一个从原生特征映射到「用户表示」的函数,用户表示定义为:
其中 为用户 的表示向量, 为embedding的维度, 是表示向量的数量,即兴趣的数量。若 ,即其他模型(如Youtube DNN)的Embedding表示方式。
目标物品 的embedding函数为:
其中 , 表示一个Embedding&Pooling层。
3.1.4 最终结果
根据评分函数检索(根据「目标物品与用户表示向量的内积的最大值作为相似度依据」,DIN的Attention部分也是以这种方式来衡量两者的相似度),得到top N个候选项:
3.2 Embedding&Pooling 层
Embedding层的输入由三部分组成,用户属性 、用户行为 和目标物品标签 。每一部分都由多个id特征组成,则是一个高维的稀疏数据,因此需要Embedding技术将其映射为低维密集向量。具体来说,
对于 的id特征(年龄、性别等)是将其Embedding的向量进行「拼接」,组成用户属性Embedding ;
目标物品 通常包含其他分类特征id(品牌id、店铺id等) ,这些特征有利于物品的冷启动问题,需要将所有的分类特征的Embedding向量进行「平均池化」,得到一个目标物品向量 ;
对于用户行为 ,由物品的Embedding向量组成「用户行为Embedding列表」,
3.3 多兴趣提取层【核心工作】
相对于单一向量进行用户兴趣表示,作者采用「多个表示向量」来分别表示用户不同的兴趣。通过这个方式,在召回阶段,用户的多兴趣可以分别考虑,对于兴趣的每一个方面,能够更精确的进行物品检索。
为了学习多兴趣表示,作者利用胶囊网络表示学习的动态路由将用户的历史行为分组到多个簇中。来自一个簇的物品应该密切相关,并共同代表用户兴趣的一个特定方面。
3.3.1 动态路由
「前提:」 以下内容基本按照原文叙述【具有概括性】,建议先理解通过其他方式理解胶囊网络和动态路由算法,不然很难理解以下描述。
“胶囊”是一种用一个向量表示的新型神经元,而不是普通神经网络中使用的一个标量。基于向量的胶囊期望能够表示一个实体的不同属性,其中胶囊的方向表示一个属性,胶囊的长度用于表示该属性存在的概率。
动态路由是胶囊网络中的迭代学习算法,用于学习低水平胶囊和高水平胶囊之间的路由对数(logit) ,来得到高水平胶囊的表示。
我们假设胶囊网络有两层,即低水平胶囊和高水平胶囊,其中, 表示胶囊的个数, 表示每个胶囊内的神经元个数(向量长度)。路由对数 通过以下计算得到,进行更新【最开始初始化为0】:
其中 表示待学习的双线性映射矩阵【在胶囊网络的原文中称为转换矩阵】。
通过计算路由对数,将高阶胶囊 的候选向量计算为所有低阶胶囊的加权和:
其中 定义为连接低阶胶囊 和高阶胶囊 的权重【称为耦合系数】,而且其通过对路由对数执行softmax来计算:
最后,应用一个非线性的“压缩”函数来获得一个高阶胶囊的向量【胶囊网络向量的模表示由胶囊所代表的实体存在的概率】
路由过程重复进行3次达到收敛。当路由结束,高阶胶囊值 固定,作为下一层的输入。
【注】:以上是论文中的定义,具体的内容可以参考其他文章。
3.3.2 B2I动态路由
作者认为原始路由算法无法直接应用于处理用户行为数据。因此,提出了「行为到兴趣(B2I)动态路由」来自适应地将用户的行为聚合到兴趣表示向量中,它与原始路由算法有三个不同之处:
「共享双向映射矩阵」。在初始动态路由中,我们使用适应的的双线性映射矩阵 而不是单独的双线性映射矩阵。一方面,用户行为是可变长度的,从几十个到几百个不等,因此使用适应的双线性映射矩阵是可推广的。另一方面,希望兴趣胶囊在同一个向量空间中,但不同的双线性映射矩阵将兴趣胶囊映射到不同的向量空间中。路由对数计算如下:
其中 是历史物品 的embedding, 表示兴趣胶囊 的向量。双线性映射矩阵 是在每一对行为胶囊【低阶】和兴趣胶囊【高阶】之间共享。
「随机初始化路由对数」。由于利用共享双向映射矩阵 ,初始化路由对数为0将导致相同的初始的兴趣胶囊。随后的迭代将陷入到一个不同兴趣胶囊在所有的时间保持相同的情景。为了减轻这种现象,我们对矩阵通过高斯分布进行随机采样来初始化路由对数,让初始兴趣胶囊与其他每一个不同,类似于稳定的K-Means聚类算法。
「动态兴趣数量」。由于不同用户拥有的兴趣胶囊数量可能不同,我们引入了一种启发式规则来自适应调整不同用户的 值。具体来说,用户的 值由以下计算:
这种调整兴趣胶囊数量的策略可以为兴趣较小的用户节省一些资源,包括计算和内存资源。

3.4 标签意识的注意力层
通过多兴趣提取层,多个兴趣胶囊从用户行为embedding建立。在训练期间,我们设计一个标签意识注意力层「让标签(目标)物品选择使用过的兴趣胶囊」。特别的,对于每一个标签物品,我们计算兴趣胶囊和标签物品embedding之间的相似性,并且计算兴趣胶囊的权重和作为目标物品的用户表示向量,通过相应的兼容性确定一个兴趣胶囊的权重【这里和DIN中的Attention几乎一样,「但key与value的含义不同」】。其中目标物品是query,兴趣胶囊既是keys也是values,如图2所示。用户 关于物品的输出向量通过以下计算得到:
其中pow定义每个元素的指数级操作, 是一个可调节的参数来调整注意力分布。当 接近0,每一个兴趣胶囊都得到相同的关注。当 大于1时,随着 的增加,具有较大值的点积将获得越来越多的权重。考虑极限情况,当 趋近于无穷大时,注意机制就变成了一种硬注意,选关注最大的值而忽略其他值。在我们的实验中,我们发现使用硬注意导致更快的收敛。
3.5 训练与服务
3.5.1 训练
得到用户向量 和标签物品embedding 后,计算用户 与标签物品 交互的概率:
目标函数为:
其中 是训练数据包含用户物品交互的集合。因为物品的数量可伸缩到数十亿,所以分母(10)的和运算在计算上是禁止的。因此。使用采样的softmax技术来让目标函数可追踪,并且选择Adam优化来训练MIND。
3.5.2 服务
训练结束后,抛开标签意识注意力层,MIND网络得到一个用户表示映射函数 。在服务期间,用户的历史序列与自身属性喂入到 ,每个用户得到多兴趣向量。然后这个「表示向量通过一个近似邻近方法来检索top N物品」。
4. 实验
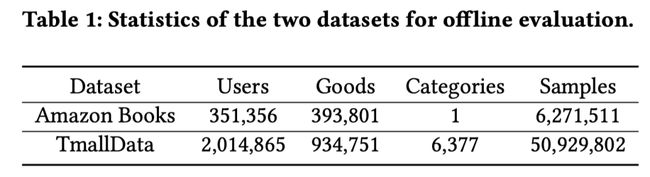
4.1 数据集
选择两个数据集进行评估:
(1)Amazon Book,一个广泛应用的公开电子推荐数据集;
(2)TmallData,包含了10天内天猫用户的200万随机采样的历史行为;
4.2 指标
命中率作为衡量推荐性能的主要指标
4.3 方法比较
WALS加权交错最小二乘法(WALS)是一种经典的矩阵分解算法,用于将用户与物品交互矩阵分解为用户与物品的隐含因子。基于用户隐藏因素与目标物品的兼容性进行推荐;
YouTube DNN如前所述,YouTube DNN是工业推荐系统中最成功的深度学习方法之一;
MaxMF 该方法引入了一种高度可扩展的非线性潜因子分解方法来建模多个用户兴趣;
4.4. 实验结果
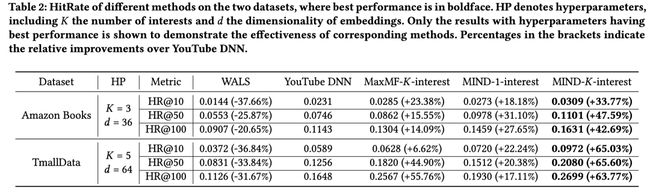
以上结果证明了使用多个用户表示向量是建立用户兴趣多样性模型,是提高推荐准确度的有效方法。
4.5 超参数分析
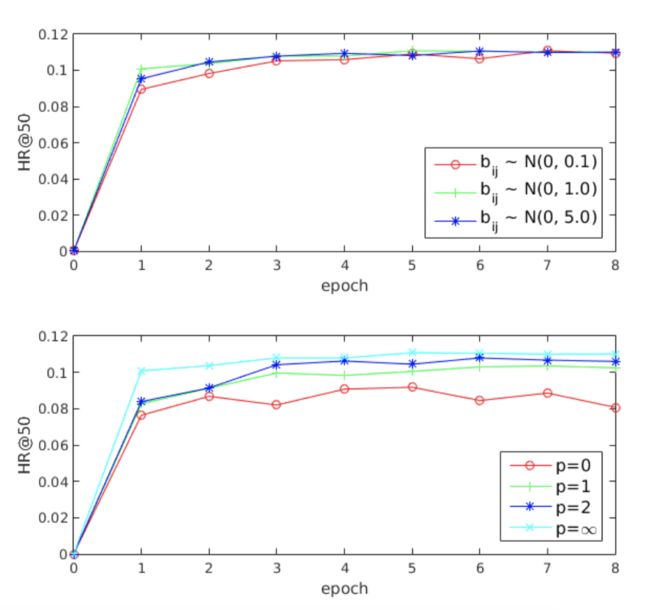
路由对数:根据高斯分布。我们考虑到 的不同值会导致不同的收敛从而对性能产生影响,选择0.1,1.0,5.0,结果如上所示。3个值的曲线基本重叠。这显示了MIND对于 的值是非常健壮的;
标签意识注意力的权值 :当 ,结果差很多,因为各兴趣关注程度相同。随着 的增大,与目标物品相似度越高的兴趣表示向量获得的关注量越大,当 ,最接近目标物品的兴趣表示优于组合兴趣表示,使MIND收敛更快,性能最好;
5. 总结
MIND模型最主要的创新是通过胶囊网络的动态路由算法来捕捉用户的多个兴趣。而在训练过程中加入一个标签意识注意力层也是一个不错的trick。可以与之前看过的ComiRec模型进行一个对比。

往期精彩回顾
【论文导读】KDD2020|阿里团队最新的多元兴趣推荐模型---ComiRec
【论文导读】浅谈胶囊网络与动态路由算法
扫码关注更多精彩




点分享

点点赞

点在看