Word2Vec【附代码】
Word2Vec【附代码】
原文链接:https://towardsdatascience.com/word2vec-explained-49c52b4ccb71
目录
介绍
什么是词嵌入?
Word2Vec 架构
- CBOW(连续词袋)模型
- 连续 Skip-Gram 模型
实施 - 数据
- 要求
- 导入数据
- 预处理数据
- 嵌入
- PCA on Embeddings
结束语
介绍
Word2Vec 是 NLP 领域的最新突破。Tomas Mikolov是捷克计算机科学家,目前是 CIIRC(捷克信息学、机器人和控制论研究所)的研究员,是 word2vec 研究和实施的主要贡献者之一。词嵌入是解决 NLP 中许多问题的一个组成部分。它们描绘了人类如何理解机器的语言。您可以将它们想象为文本的矢量化表示。Word2Vec 是一种常用的词嵌入生成方法,具有文本相似度、推荐系统、情感分析等多种应用。
什么是词嵌入?
在我们进入 word2vec 之前,让我们先了解一下词嵌入是什么。了解这一点很重要,因为 word2vec 的整体结果和输出将是与通过算法传递的每个唯一单词相关联的嵌入。
词嵌入是一种将单个词转换为词的数字表示(向量)的技术。每个单词都映射到一个向量,然后以类似于神经网络的方式学习该向量。向量试图捕捉该词相对于整个文本的各种特征。这些特征可以包括单词的语义关系、定义、上下文等。通过这些数字表示,你可以做很多事情,比如识别单词之间的相似性或不相似性。
显然,这些作为机器学习各个方面的输入是不可或缺的。机器无法处理原始形式的文本,因此将文本转换为嵌入将允许用户将嵌入提供给经典的机器学习模型。最简单的嵌入是文本数据的一次热编码,其中每个向量都将映射到一个类别。
例如:
have = [1, 0, 0, 0, 0, 0, … 0]
a = [0, 1, 0, 0, 0, 0, … 0]
nice = [0, 0, 1, 0 , 0, 0, … 0]
day = [0, 0, 0, 1, 0, 0, … 0] …
然而,像这样的简单嵌入有多重限制,因为它们不能捕捉单词的特征,而且根据语料库的大小,它们可能会很大。
Word2Vec 架构
Word2Vec 的有效性来自于它能够将相似词的向量组合在一起。给定足够大的数据集,Word2Vec 可以根据单词在文本中的出现次数对单词的含义做出强有力的估计。这些估计产生了与语料库中其他单词的单词关联。例如,像“King”和“Queen”这样的词会非常相似。在对词嵌入进行代数运算时,您可以找到词相似度的近似值。例如,“king”的二维嵌入向量——“man”的二维嵌入向量+“woman”的二维嵌入向量,产生了一个与“queen”的嵌入向量非常接近的向量。请注意,以下值是任意选择的。
国王 - 男人 + 女人 = 女王
[5,3] - [2,1] + [3, 2] = [6,4]
可以看到,King 和 Queen 两个字的位置相近。(图片由作者提供)
word2vec 的成功主要有两种架构。skip-gram 和 CBOW 架构。
CBOW(连续词袋)
这种架构非常类似于前馈神经网络。这种模型架构本质上试图从上下文词列表中预测目标词。这个模型背后的直觉很简单:给定一个短语"Have a great day",我们将选择目标词为“a”,上下文词为[“have”、“great”、“day”]。该模型将做的是采用上下文词的分布式表示来尝试和预测目标词。

skip-gram模型
skip-gram 模型是一个简单的神经网络,具有一个经过训练的隐藏层,以便在输入单词出现时预测给定单词出现的概率。直观地,您可以想象 skip-gram 模型与 CBOW 模型相反。在这个架构中,它将当前单词作为输入,并试图准确地预测当前单词之前和之后的单词。该模型本质上是尝试学习和预测指定输入词周围的上下文词。基于评估该模型准确性的实验,发现在给定大范围的词向量的情况下预测质量有所提高,但它也增加了计算复杂度。该过程可以直观地描述,如下所示。
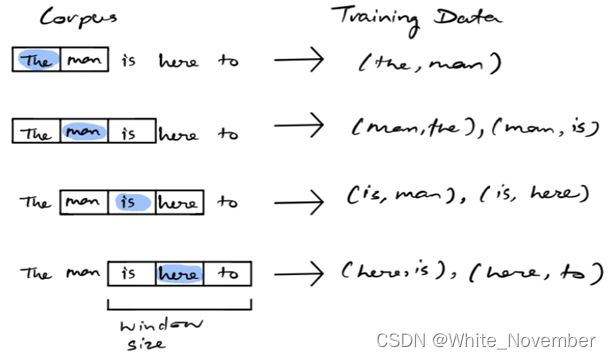
如上所示,给定一些文本语料库,在某个滚动窗口上选择目标词。训练数据由目标词和窗口中所有其他词的成对组合组成。这是神经网络的最终训练数据。一旦模型经过训练,我们基本上可以得出一个词作为给定目标的上下文词的概率。下图代表了 skip-gram 模型的神经网络架构。
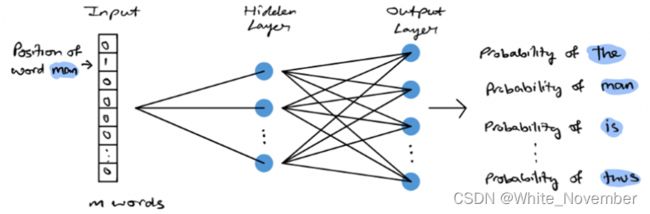
语料库可以表示为大小为 N 的向量,其中 N 中的每个元素对应于语料库中的一个词。在训练过程中,我们有一对目标词和上下文词,输入数组中除目标词外的所有元素都为 0。目标词将等于 1。隐藏层将学习每个词的嵌入表示,产生一个 d 维嵌入空间。输出层是一个带有 softmax 激活函数的密集层。输出层基本上会产生一个与输入大小相同的向量,向量中的每个元素都包含一个概率。该概率表示目标词与语料库中相关词之间的相似度。
有关这两种模型的更详细概述,我强烈建议您阅读概述这些结果的原始论文“Efficient Estimation of Word Representations inVector Space”。
执行
我将展示如何使用 word2vec 生成词嵌入,并使用这些嵌入来查找相似的词并通过 PCA 可视化嵌入。
数据
出于本教程的目的,我们将使用莎士比亚数据集。你可以在这里找到我用于本教程的文件,它包含莎士比亚为他的戏剧写的所有台词。
要求
nltk==3.6.1
node2vec==0.4.3
pandas==1.2.4
matplotlib==3.3.4
gensim==4.0.1
scikit-learn=0.24.1
注意:由于我们正在使用 NLTK,您可能需要下载以下语料库,以便教程的其余部分正常工作。这可以通过以下命令轻松完成:
import nltk
nltk.download('stopwords')
nltk.download('punkt')
导入数据
import pandas as pd
import nltk
import string
import matplotlib.pyplot as plt
from nltk.corpus import stopwords
from nltk import word_tokenize
from gensim.models import Word2Vec as w2v
from sklearn.decomposition import PCA
# constants
PATH = 'data/shakespeare.txt'
sw = stopwords.words('english')
plt.style.use('ggplot')
# nltk.download('punkt')
# nltk.download('stopwords')
# import data
lines = []
with open(PATH, 'r') as f:
for l in f:
lines.append(l)
注意:将变量更改为PATH您正在使用的数据的路径。
预处理数据
# remove new lines
lines = [line.rstrip('\n') for line in lines]
# make all characters lower
lines = [line.lower() for line in lines]
# remove punctuations from each line
lines = [line.translate(str.maketrans('', '', string.punctuation)) for line in lines]
# tokenize
lines = [word_tokenize(line) for line in lines]
def remove_stopwords(lines, sw = sw):
'''
The purpose of this function is to remove stopwords from a given array of
lines.
params:
lines (Array / List) : The list of lines you want to remove the stopwords from
sw (Set) : The set of stopwords you want to remove
example:
lines = remove_stopwords(lines = lines, sw = sw)
'''
res = []
for line in lines:
original = line
line = [w for w in line if w not in sw]
if len(line) < 1:
line = original
res.append(line)
return res
filtered_lines = remove_stopwords(lines = lines, sw = sw)
停用词过滤说明
-
请注意,从这些行中删除的停用词是现代词汇。应用程序和数据对于单词清理所需的预处理策略类型非常重要。
-
在我们的场景中,像“you”或“yourself”这样的词将出现在停用词中并从行中删除,但是由于这是莎士比亚文本数据,因此不会使用这些类型的词。相反,“你”或“你自己”可能有助于删除。保持对这些类型的微小变化保持热情,因为它们在一个好的模型和一个差的模型的性能上产生了巨大的差异。
-
出于本示例的目的,我不会详细介绍如何识别来自不同世纪的停用词,但请注意,您应该这样做。
嵌入
w = w2v(
filtered_lines,
min_count=3,
sg = 1,
window=7
)
print(w.wv.most_similar('thou'))
emb_df = (
pd.DataFrame(
[w.wv.get_vector(str(n)) for n in w.wv.key_to_index],
index = w.wv.key_to_index
)
)
print(emb_df.shape)
emb_df.head()

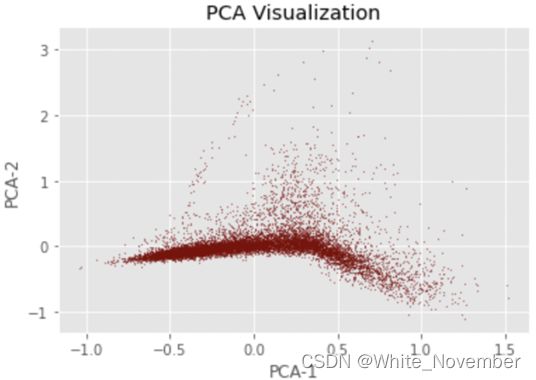
嵌入的 PCA
pca = PCA(n_components=2, random_state=7)
pca_mdl = pca.fit_transform(emb_df)
emb_df_PCA = (
pd.DataFrame(
pca_mdl,
columns=['x','y'],
index = emb_df.index
)
)
plt.clf()
fig = plt.figure(figsize=(6,4))
plt.scatter(
x = emb_df_PCA['x'],
y = emb_df_PCA['y'],
s = 0.4,
color = 'maroon',
alpha = 0.5
)
plt.xlabel('PCA-1')
plt.ylabel('PCA-2')
plt.title('PCA Visualization')
plt.plot()
Tensorflow 对 word2vec 模型进行了非常漂亮、直观和用户友好的表示。我强烈建议您探索它,因为它允许您与 word2vec 的结果进行交互。链接如下:https://projector.tensorflow.org/
结束语
词嵌入是解决 NLP 中许多问题的重要组成部分,它描述了人类如何理解机器的语言。给定一个大型文本语料库,word2vec 会生成一个与语料库中的每个单词相关联的嵌入向量。这些嵌入的结构使得具有相似特征的单词彼此非常接近。CBOW(连续词袋)和 skip-gram 模型是与 word2vec 相关的两个主要架构。给定一个输入词,skip-gram 将尝试预测输入上下文中的词,而 CBOW 模型将采用各种词并尝试预测缺失的词。