CNN基础论文 精读+复现---- ResNet(一)
文章目录
- 前言
- 第1-2页
-
- 摘要与引言
- 残差模块
- 第2-3页
-
- 文献综述
- 第3-4页
-
- 深度残差网络
- 第4-8页
-
- 一些实验的结果
- BasicBlock块 与 BottleNeck块
- 总结与思考
-
- 深层网络为什么会出现退化现象?
- ResNet为什么可以解决网络退化问题?
- ResNet 为什么可以防止梯度消失?
-
- 读后感
前言
ResNet论文下载地址:https://arxiv.org/pdf/1512.03385.pdf
论文题目:Deep Residual Learning for Image Recognition
ResNet 撑起计算机视觉领域的半边天。
CV领域 或者说卷积神经网络领域的两次技术爆炸,第一次是AlexNet,第二次就是ResNet了。
复现代码放最后了 Github上也放了一份:https://github.com/shitbro6/paper
第1-2页
摘要与引言
先简单介绍了一下论文获得的奖项。
ResNet论文 2016年 CVPR最佳论文,2015年ImageNet竞赛和coco竞赛中的检测、分割、定位等五个赛道的冠军。
之前学习的VGG已经是很深了有19层。这次作者的实验使用了其8倍深的网络,152层深度,且仍有较低的复杂度(并用这个模型获得了ILSVRC 2015分类冠军)。
我们都知道,理论上来讲网络深度越深越好,网络越深,提取的图片特征越多越丰富,但随之会带来很多的问题(虽然已经可以通过BN等大部分解决),比如过拟合或者计算量爆炸,梯度消失 梯度爆炸等,导致网络在一定深度下就达到了局部最优解。
后来在作者的实验中发现深层网络中更加严重的问题–退化现象,这个退化问题既不是由梯度消失爆炸引起的,也不是由过拟合引起的(过拟合 是训练集误差低,测试集误差高),深层的退化现象是训练集和测试集上的误差都非常高,
为了解决这个问题,提出了残差网络的学习框架。
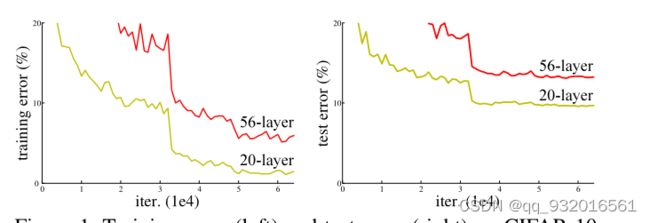
引言部分给的一张图,红色是变成高层之后,可以看到训练和测试集错误率变成56层之后都有明显升高。
残差模块
作者提出了一个残差模块(Residual Block残差块)用于解决网络退化问题。
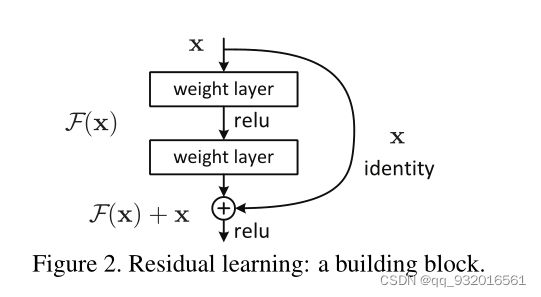
可以看到x输入之后有两条路可以走,右边一条路还有中间一条路 。左边的路 identity 称为恒等映射(shortcut connection & skip connection ),恒等映射 不引入额外的参数量和计算量,所以此时总的输出映射为 F ( x ) + x F(x) + x F(x)+x.
设最终得到的映射为 H ( s ) H(s) H(s) ,则 F ( x ) = H ( x ) − x F(x) = H(x) - x F(x)=H(x)−x,即学习的是 应有的映射与原始输入之间的差值。因此被称为残差映射(residual mapping)。
也可以理解为 中间这条有神经网络的路用于拟合原始输入的偏差。也就是说,原来的神经网络需要拟合最终的映射 H ( x ) H(x) H(x),而现在使用了残差模块后 需要拟合的是 F ( x ) F(x) F(x),最终映射就是 F ( x ) + x F(x) + x F(x)+x。
比如5正常映射为5.1,加入残差后变成 5+0.1。此时输入变成5.2,对于没有残差结构的结果,影响仅为0.1/5.1 = 2%。而对于残差结构,变成 5+0.2 , 由0.1变成了0.2 影响为100%。这么大的数值变化利于神经网络的分析,所以残差结构可以变相的看为差分放大器。
残差映射 H ( x ) = F ( x ) + x H(x) = F(x) + x H(x)=F(x)+x,反向传播的时候就变成了 H ′ ( x ) = F ′ ( x ) + 1 H^{'}(x) = F{'}(x) + 1 H′(x)=F′(x)+1,这里的加一也可以保证梯度消失的现象。
后面作者简单说了一下这个残差结构的有点:
- 易于优化和收敛
- 解决退化问题
- 可以使神经网络很深且准确率大大提升,计算复杂度仍很低。
作者也证明了退化问题在任何数据集上都普遍存在。在imagenet上拿到冠军之后,迁移学习用到了coco同样拿到了好几个赛道的冠军,说明残差结构是普适的。
最后又和VGG比了一下,比VGG深了8倍,计算复杂性却还比VGG小 。。额,反面教材VGG。
第2-3页
文献综述
这里作者主要说了一下现有的残差表示的情况。
在低级视觉(像素层面)和计算机图形学(2-3D图像显示在计算机中的研究)中,为了求解偏微分方程(PDE),广泛的使用多重网格,把问题分解成若干子问题,每个子问题都是要求得一个粗粒度和细粒度的一个残差。多重网格的替换方法时使用级联机方法,该方法也是使用残差解决问题。但现有工作都没有体现残差现象更本质的运用于机器学习的提升。
shortcut connections在之前就有被提及和研究,例如训练多层感知机时添加一个线性层连接输入和输出层、GoogleNet中的辅助分类器用于解决梯度消失,其中“inception”也是包含了shortcut连接的。
第3-4页
深度残差网络
这里就是解释前面说的那个 由直接拟合函数 H ( x ) H(x) H(x)变为拟合 残差 F ( x ) F(x) F(x)。
神经网络拟合传统网络能力较差,加了恒等映射之后,深层网络就不会比浅层的差(避免了退化现象),如果恒等映射已经最优,则残差模块只拟合零映射,所以后面的网络只拟合前面网络的输出与期望函数的残差(拟合扰动)即可。
这里有一个 万能近似定理(Universal Approximation Theorem):
人工智能领域一个出名的定理,就是说,如果一个前馈神经网络具有线性输出层和至少一层隐藏层,只要给予网络足够数量的神经元,就可以拟合任何一个函数。(暂时无法证明,果然就 人工智能=玄学)
3.2节就是数学化了这个残差过程,给了个公式:
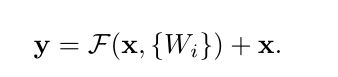
其实就还是前面说的那些,x就是恒等映射的,前面F那一堆就是残差。
论文里面的 σ 就像一个圈圈多一点 ,表示激活函数。
输入加起来F(x) + x,并使用shortcut进行逐元素对应相加( element-wise addition) ,之后将相加的结果再进行一次激活(relu)。其实就是在文字化上面的那个残差结构图。
相加的时候, 残差F(X)与自身输入x维度必须一致才能实现。
作者在3.3节中对比了带残差的网络和不带残差的网络,也是对比的反面教材VGG,用了34层网络,论文中第4页开头也给了一大块的图,以此来说明他家的残差很强。
其中在残差网路结构中,shortcut会有两种,一种是实线直接将输入传给输出,虚线则是使用了下采样,下采样采用步长为2的卷积,这里当残差维度不同时,用padding或者1 * 1 卷积核升维。
3.4中说了一下训练细节,其中的超参数还有预处理 数据增强等都和Alex或者VGG一样,只有一些细小的改动,比如输入的尺寸变成了[256,480]的范围值了,没有全连接层了所以没了dropout等。
batch normalization (BN) : 批量标准化 加快收敛速度,改善梯度消失,关于 BN原理详细。
第4-8页
一些实验的结果
第四章主要就是使用了各种对比方法,在各种模型和数据集上进行对比实验。
这一大段 and 一大堆实验图实际上就还是在说之前的那个问题,普通网络层数变深就出现了退化现象,而这种退化现象并不是由梯度消失 、爆炸或过拟合引起的。使用了残差结构的网络可以解决这一退化现象且残差网络收敛很快,早期就很快。
虽然有残差模块,但网络也不能一味的加深。1202层没有101层的效果好,因为相对于超深度模型,使用的数据集太小了,过拟合了。
扩大数据集规模是防止过拟合的根本。
给了张图表示了很多不同深度的ResNet网络:
有 18、34、50、101、152层的不同深度。第一二层和最后的全连接分类层是一样的,只有中间每一块是不同的,这里面 x2就是复制了两次,比如第二列34层的模型,中间是 x3 x4 x6 x3 这里一共是 3+4+6+3 16块,每块里面有2层,就是32层,加上开头的卷积 和最后的全连接 一共就是34层。
作者并没有说为什么要这样取,估计是调出来的吧,玄学。
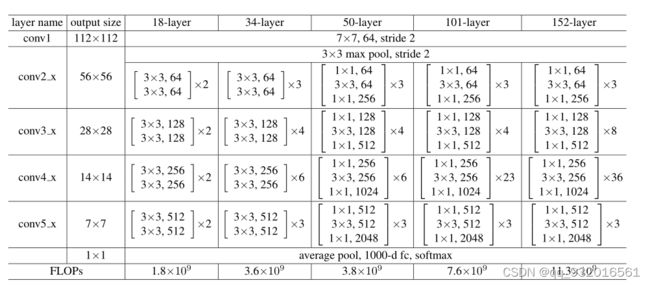
这张图的最后一行是 FLOPs,就是浮点数的计算法复杂度,在18层的时候复杂度是1.8 到了34层变成了3.6 几乎翻了一倍,但是由34层到50层 复杂度仅仅由3.6到了3.8,复杂度并没有提升多少,从网络结构的变化看, 小块块里的两层结构变成了三层结构,这就是后面介绍的BasicBlock块和BottleNeck块。
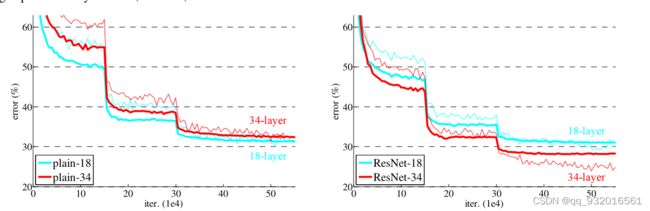
给出了实验图,对比普通的神经网络,使用了残差的网络越深,错误率越低。
突然下降是因为下降了学习率,学习率 * 0.1。
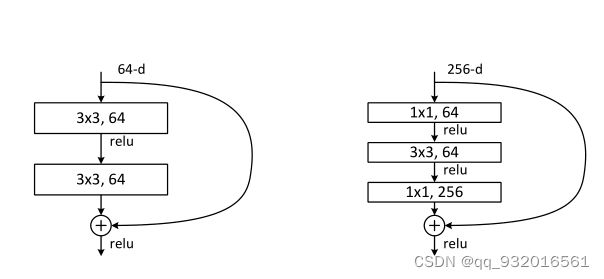
BasicBlock块 与 BottleNeck块
文中给出了一张图:(目的就是如何让ResNet层数更深)
左边就是原来的设计 64通道时,但想让层数加深的时候,通道数也跟着变多,这样就能学到更多的东西了,右边就是改造之后的,通道数变成了256,计算复杂度直线上升。
为了降低时间复杂度,右边256进去之后第一层就通过了 1 * 1 的卷积将维度降至64.之后做3 * 3的卷积,最后再变回256的通道数(输入输出要一样),
最后的附录,就是详细的说了一下比赛时候的各种调参细节,懒得看了,就跳过了。
总结与思考
深层网络为什么会出现退化现象?
读完论文之后我第一个就是想到了这个问题,然后思考了一下,我没想通为什么会出现退化现象,按理说如果有一个50层的网络,训练到50层时不应该比20层的错误率还高啊?最起码应该是个持平从状态,因为第50层的训练参数已经将前20层包含住了,怎么会出现退化现象的?文中也提到了并非是过拟合和梯度消失或爆炸导致的退化问题(毕竟现在已经加入BN来解决大部分梯度问题),在第三天我写完代码复现之后,我觉得可能是因为随机梯度下降的问题吗?还有可能是由于前面的太多Relu和池化导致为了降低复杂度从而损失了越来越多的特征且不可逆的问题?
网上有很多的解释,其中有一个说MobileNet V2中提到的特征丢失不可逆问题我觉得靠谱,等有时间看一下MobileNet V2。
ResNet为什么可以解决网络退化问题?
实际上就是因为残差结构作为一个变相的差分放大器,可以放大之前做错的地方从而进行更好的分析和改善。
我们可以通俗的理解为,残差结构学习的是差值(应有的映射与原始输入之间的差值)。
举个例子,看下面这张图。
红色是一类,蓝色是一类。如果第一次分错之后,分错的部分会被放大用于下次分析,下次就会着重的去处理上次分错的情况,以此类推。
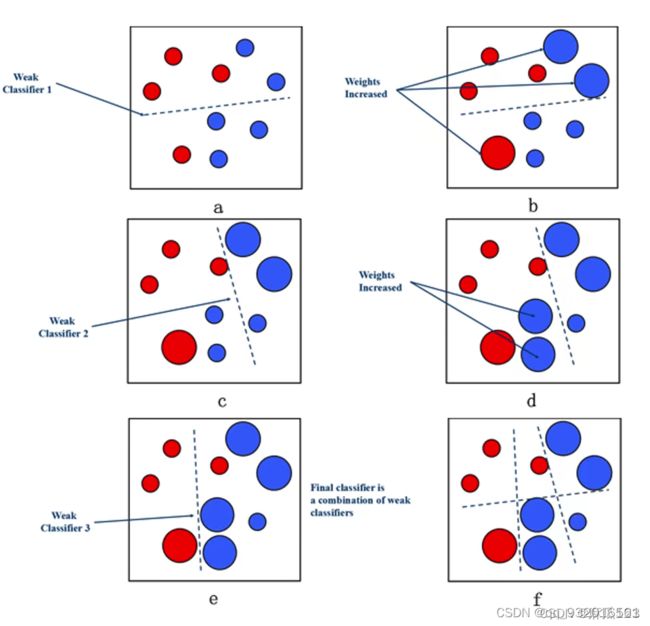
上面这个模型其实也可以看作集成学习,每一块都是弱分类器,集成到一起之后就变成了强分类器。和残差模块一样,每一个都是在修正上一块的误差。
网上还看到一个解释我觉得挺有意思,不希望随着网络深度的增加让模型特征‘越走越远‘,于是做了恒等映射,让模型不忘初心。
ResNet 为什么可以防止梯度消失?
首先明确一点,梯度消失和网络退化是两码事,原因也在文中说明过了。
其实能防止梯度消失就是残差块的恒等映射的功劳,恒等映射的梯度一直都是1(x的求导),将深层梯度注入底层(深层梯度回传流畅),防止了梯度消失。
读后感
这篇论文读完之后,感觉整篇文章的逻辑很清晰,大多数都是以实验为主,主要就是提出了一个残差结构,调参啊还有各种推导的地方,大幅玄学哈哈,据说很多地方都还没有证明。我悟了,理论和实验只要有一个方面有成果并且就算不是自己先提出来的也可以发论文。
另外其实还有很多地方没有懂,很多地方一知半解的(可能是我太菜了),可能会随着后续学习深入逐渐解决吧,ResNet还有很多变种,慢慢学吧,后面可能先看一下Densenet或者transform。
代码复现后续:CNN基础论文 精读+复现---- ResNet(二)