论文浅尝 | Efficient RDF graph storage based on RL

笔记整理:郑国鹏,天津大学硕士
链接:https://link.springer.com/article/10.1007/s11280-021-00919-x
动机
知识是人工智能的基石,它通常以RDF图的形式表示。各个领域的大规模RDF图对图数据管理提出了新的挑战。关系型数据库因其成熟稳定的特性,是存储图数据库的热门方案。然而,在关系型数据库中管理结构复杂的RDF图需要复杂的存储结构设计。为了解决这个问题,本文采用了强化学习(RL)来优化RDF图的存储分区方法。这是第一个采用RL来解决这个问题的工作。此外,本文提出了RDF表的特征化方法,保证了状态表示的充分性,并提出了查询重写策略,保证了存储结构变化时查询结果的正确性。在各种RDF基准上进行的大量实验表明,本文所提出的方法明显优于最先进的存储策略。
亮点
GSBRL的亮点主要包括:
(1)本文是第一个采用强化学习(RL)解决RDF图存储问题的工作
(2)本文为图的存储问题设计了有效的RL模型。并且提出了查询重写策略,以确保在存储结构发生变化时查询结果正确。
概念及模型
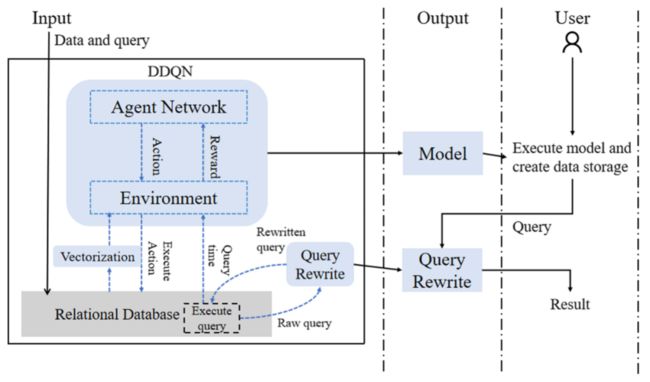
下图显示了GSBRL的结构概况。图中的虚线表示输入、输出和用户加载训练好的模型之间的过程边界。GSBRL将数据集和工作负载作为关系数据库的输入。而训练好的模型将被输出给用户使用。实线所包含的部分是GSBRL的核心,其中代理不断进行交互,以获得最佳的存储结构,目的是使查询时间最小化。
系统的架构如下:
(1)输入模块:为了获取数据集和查询工作负荷。数据集以三元组的形式存储在一张表中。查询工作负载的输入是一组由SPARQL语句改写的SQL语句。
(2)矢量化模块:提取并将数据存储特征转换为矢量。这个模块将在第4.3节介绍
(3)DDQN模块:通过RL做出存储决策。它为数据库选择要执行的动作。数据库返回工作量的查询时间以计算奖励。在这个过程中,需要对查询进行重写。DDQN不断与数据库环境互动,以更新Q值。DDQN的输出是一个固定长度的向量,它包含了当前状态下不同行动的Q值。这个模块将在第4.4节中介绍。
(4)查询重写模块:负责重写查询,以便在当前存储结构下尽量减少查询执行时间。当存储结构发生变化时,查询重写策略通过调整查询执行策略以适应变化后的存储,确保高性能。这个模块将在第5节介绍。
(5)在模型训练完成后,用户可以执行该模型来建立数据存储结构。
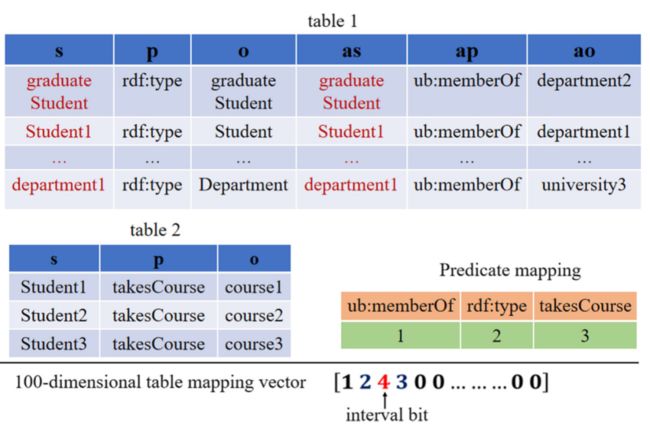
存储特征矢量化
由于图数据的规模可能非常大,不可能将所有的数据作为神经网络的输入。因此,有必要提取图数据的有用特征并将其映射为固定长度的矢量。
RDF图中的一个重要特征是其边上的谓词。因此,本文将图中的谓词矢量化,以代表当前表的存储状态,并将该矢量作为神经网络的输入。映射方法如下:
首先,按照表的顺序得到各表(除初始表t0外)的所有谓词,进行向量映射。在表中,有3个谓词,分别编码为1、2、3。在对表的谓词进行映射后,在不同的表之间增加一个间隔位,形成的向量为< 1, 2, 4, 3 >。如果该向量没有达到输入向量的维度,则用零填充,直到达到最终向量显示的固定输入维度。
DDQN模块
本文采用 Deep Q-Network(DDQN)来训练模型。模型训练算法如下所示:

给定一个特定的数据集D和工作量N。一开始,环境Env被初始化为一个三元组表t0,并设置了空行动列表L。接下来,深度强化学习神经网络RL被建立。RL在第3-14行中执行迭代多个episode。在训练过程中,RL的参数被不断调整,以适应环境,从而达到更好的性能。最后,我们可以得到一个可以加载的训练模型。
强化学习模型的训练完成后,可以得到训练好的模型,其中包含每个动作对应的值。本文最终的需要获取RDF最佳存储结构。存储结构的生成过程如下。
算法2描述了基于RL模型的存储结构生成过程。给定一个特定的数据集D和工作负载N,一开始,将环境Env初始化为一个三元组表t0,并设置一个初始结构G。接下来,载入深度强化学习神经网络RL。最优存储结构及其相应的最大累积奖励在第3行被初始化。模型在第4-17行中迭代多个episode。最后,可以得到一个最佳存储结构Goptimal。

实验
作者采用了3个公开数据集进行实验,分别是:LUBM、WatDiv、DBpedia。前两个为合成数据集,后一个为真实数据集。与Jena、DB2RDF、RDF-3x、Virtuoso四个模型进行比较。评价指标为查询执行时间。
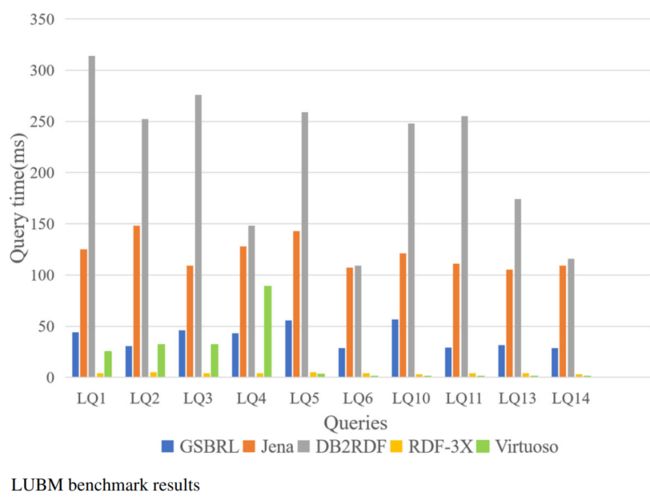
如图显示,对于LUBM。GSBRL在所有10个查询中都明显快于Jena和DB2RDF。
在最坏的情况下,GSBRL比Jena快50%,在最好的情况下是Jena的四分之一。GSBRL在最差情况下是DB2RDF的三分之一,在最好情况下是DB2RDF的八分之一。然而,在LUBM基准上,RDF-3X的性能要比GSBRL好。这可能是得益于六元组的索引。当GSBRL和Virtuoso在10个查询中进行比较时,GSBRL在两个查询中比Virtuoso快,即LQ2和LQ4。由于数据规模小,查询时间短,Virtuoso在大多数工作负载上比GSBRL表现更好。
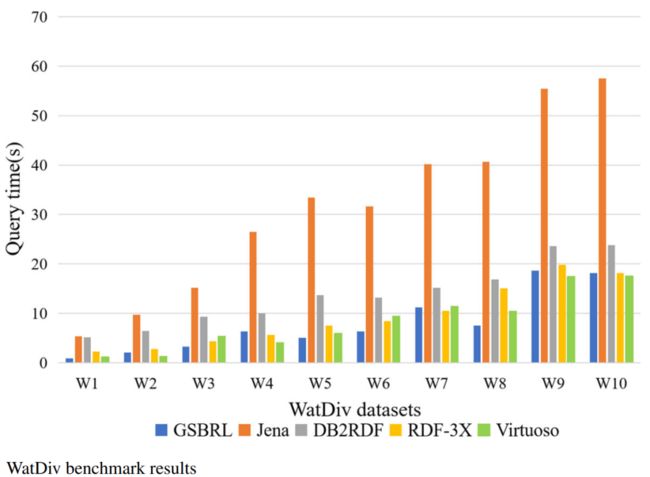
图中显示了GSBRL和其他四个系统在不同规模的数据集上对所有20个WatDiv查询的运行时间。GSBRL在大多数情况下都优于其他系统。随着数据规模的增加,GSBRL查询时间没有明显增加,但DB2RDF和Jena的表现很差。除了W4和W7,GSBRL的运行速度比RDF-3X快。除了W2、W4、W9和W10之外,GSBRL在大多数数据集上的运行速度也比Virtuoso快。对于四个子数据集,这两个系统的性能几乎相同,Virtuoso比GSBRL快大约0.5秒。
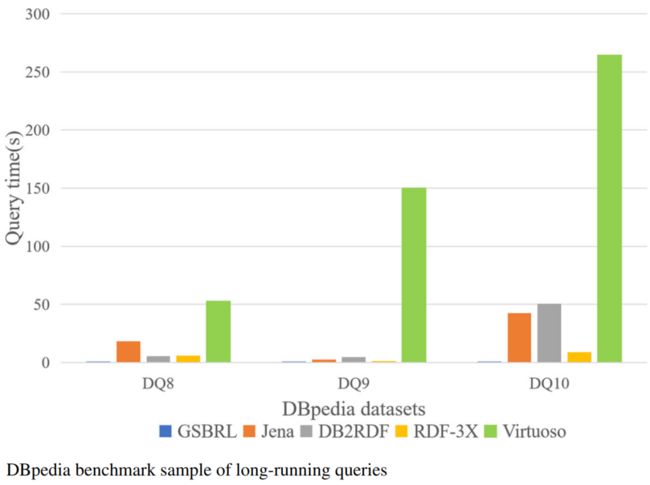
在DBpedia数据集上。无论是long-running query, 还是 medium-running query,GSBRL查询时间均少于对比模型。

总结
为了解决图数据的自动关系存储结构设计问题,本文提出了基于强化学习的GSBRL。该方法综合利用了数据和工作负载的特点。并具有较强的普适性,即对不同的图数据集都有一个有效的存储方案。高普适性可以极大地提高大数据集下的数据存储效率。实验结果表明,GSBRL的性能优于现有的最好的模型。
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。