Transformer结构解析及常见问题
Transformer结构解析及常见问题
关于Transformer的结构相关知识,有这二十个面试常见问题,大家可以用这20个问题看看自己有没有掌握Transformer(答案在文章最后)
1.Transformer为何使用多头注意力机制?(为什么不使用一个头)
2.Transformer为什么Q和K使用不同的权重矩阵生成,为何不能使用同一个值进行自身的点乘? (注意和第一个问题的区别)
3.Transformer计算attention的时候为何选择点乘而不是加法?两者计算复杂度和效果上有什么区别?
4.为什么在进行softmax之前需要对attention进行scaled(为什么除以dk的平方根),并使用公式推导进行讲解
5.在计算attention score的时候如何对padding做mask操作?
6.为什么在进行多头注意力的时候需要对每个head进行降维?(可以参考上面一个问题)
7.大概讲一下Transformer的Encoder模块?
8.为何在获取输入词向量之后需要对矩阵乘以embedding size的开方?意义是什么?
9.简单介绍一下Transformer的位置编码?有什么意义和优缺点?
10.你还了解哪些关于位置编码的技术,各自的优缺点是什么?
11.简单讲一下Transformer中的残差结构以及意义。
12.为什么transformer块使用LayerNorm而不是BatchNorm?LayerNorm 在Transformer的位置是哪里?
13.简答讲一下BatchNorm技术,以及它的优缺点。
14.简单描述一下Transformer中的前馈神经网络?使用了什么激活函数?相关优缺点?
15.Encoder端和Decoder端是如何进行交互的?(在这里可以问一下关于seq2seq的attention知识)
16.Decoder阶段的多头自注意力和encoder的多头自注意力有什么区别?(为什么需要decoder自注意力需要进行 sequence mask)
17.Transformer的并行化提现在哪个地方?Decoder端可以做并行化吗?
19.Transformer训练的时候学习率是如何设定的?Dropout是如何设定的,位置在哪里?Dropout 在测试的需要有什么需要注意的吗?
20.解码端的残差结构有没有把后续未被看见的mask信息添加进来,造成信息的泄露。
Transformer结构
Transformer是深度学习的一个经典架构,主要由一个Encoder和一个Decoder构成,其结构总体框架如图一所示。本文分别从Encoder和Decoder模块讲解Transformer架构。如果对Self-Attention不太了解的可以先看这篇文章:Self-Attention讲解
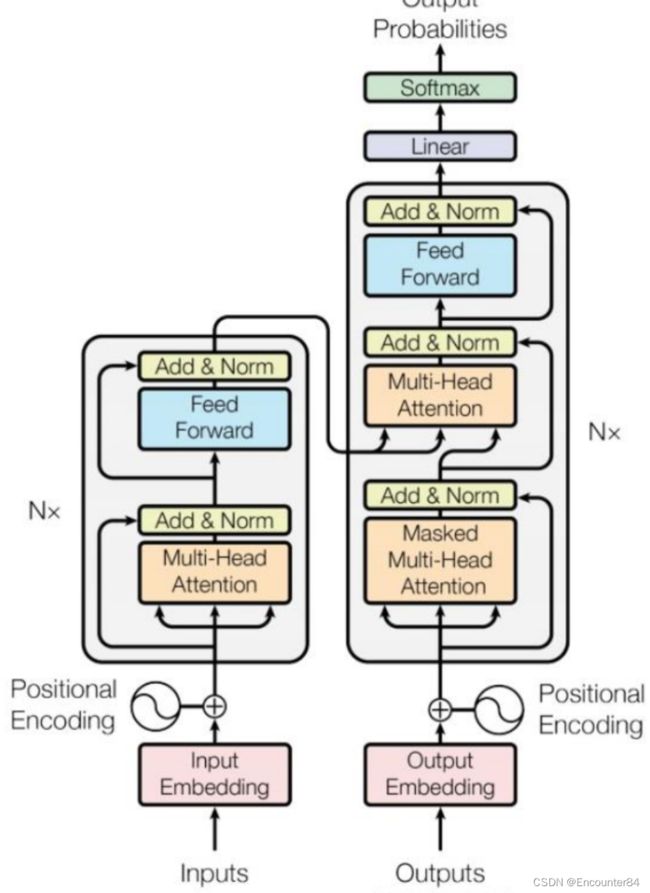
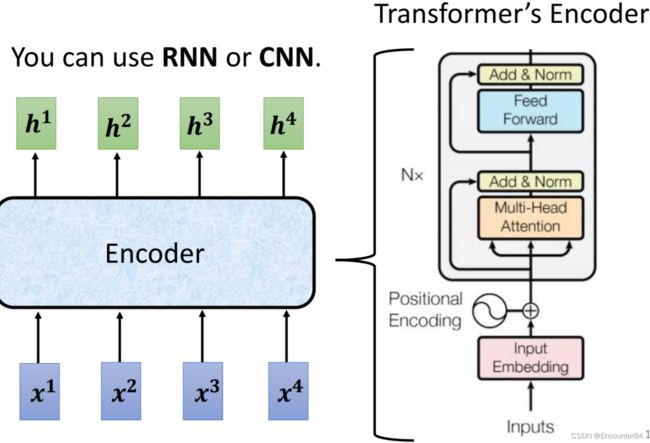
首先从Encoder部分开始,Transformer结构中的Encoder部分如下图所示,其虽然內部结构如下图右半部分,看起来比较复杂,但是将其內部结构看成一个黑箱的话,其实就是输入 x 1 x 2 x 3 x 4 x^1x^2x^3x^4 x1x2x3x4这样一个sequence序列,然后输出 h 1 h 2 h 3 h 4 h^1h^2h^3h^4 h1h2h3h4的sequence序列。这种输入输出方式,使用RNN或者CNN也可以做到。
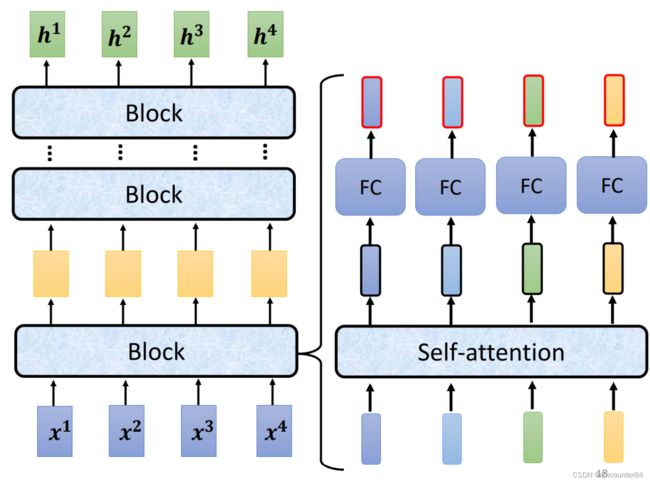
如果再把这个黑箱拆开一点,就会发现里面有许多个Block连接而成。每个Block拆开看的话,细节如下图右半部分所示,输入的四个向量经过一个Self-attention层,输出的四个向量再经过一个Fully-Connect全连接层,之后生成的向量再作为下一个模块的输入。
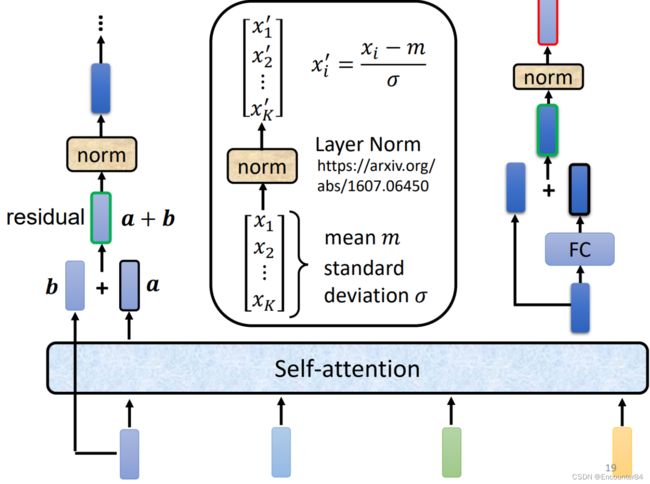
Transformer论文中的Block比上图所示要稍微复杂一些,具体实现如下图所示。假设下图中最左边输入的向量为b,其经过Self-attention层后的输出为a,a向量和最开始的b向量进行一个残差连接(即两个向量直接相加),然后经过一个Layer Norm归一化层。需要注意的是,Layer Normalization和Batch Normlization不一样。Batch Norm是在相同的维度对数据不同的feature进行归一化,Layer Norm是在同一个feature或者同一个example对不同的维度进行归一化。具体可参考这篇博客:(106条消息) BatchNorm、LayerNorm详细过程及示例_Pytorch_PuJiang-的博客-CSDN博客_layernorm在向量经过Layer Norm之后,再经过一个FC层,并与原向量相加,进行一个residual操作,最后再进行一个Layer Norm操作,最终得到的输出才是Encoder模块中一个block的输出。
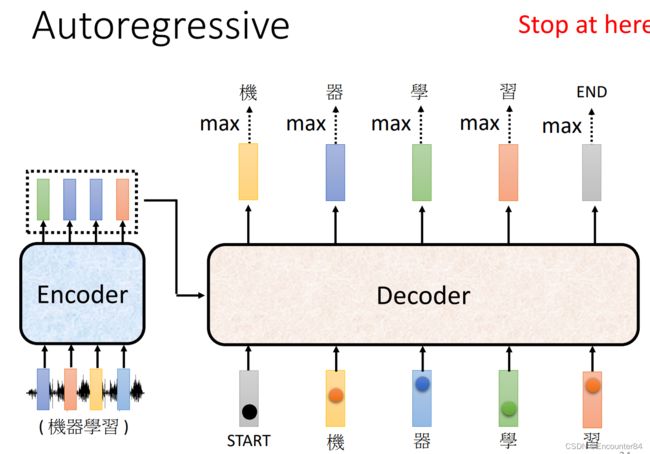
接下来就到了Decoder部分,这个模块用来产生输出。Decoder首先需要读入Encoder的输出,然后自己也要产生一个sequence的输出。那么Decoder怎么产生输出呢?首先,我们需要给Decoder部分一个特殊的表示输入开始的符号BOS(Begin of Sentence),接着Doceder产生一个输出,如下图所示,该输出向量的大小就是词表大小(就是Decoder有可能输出的字的数量,比如机器翻译中,Decoder又可能会输出3000个汉字的话,Decoder的输出Size V的大小就是3000),该向量因为经过了一次SoftMax操作,其中的每个值的内容都是它出现的概率,最终选择概率最大的的值作为Decoder的输出,在下图中的例子就是“机”这个字。
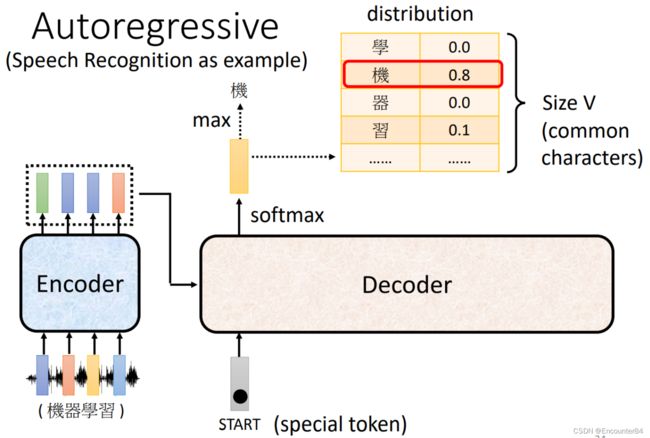
接下来,我们把刚刚输出的“机”这个字当成Decoder的另外一个输入,其和BOS一样使用one hot向量来表示,Decoder根据BOS和“机”的one hot输入输出第二个向量的最大值“器”,同理可得“学”“习”二字的输出方式。
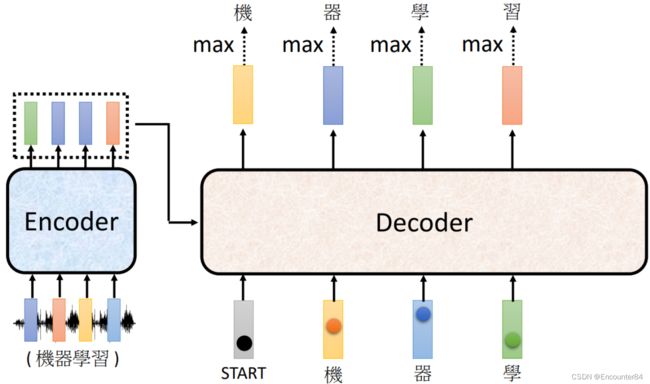
如果我们把Decoder模块也拆开看,它的內部结构由下图右半部分所示,该部分会在后文详细介绍。
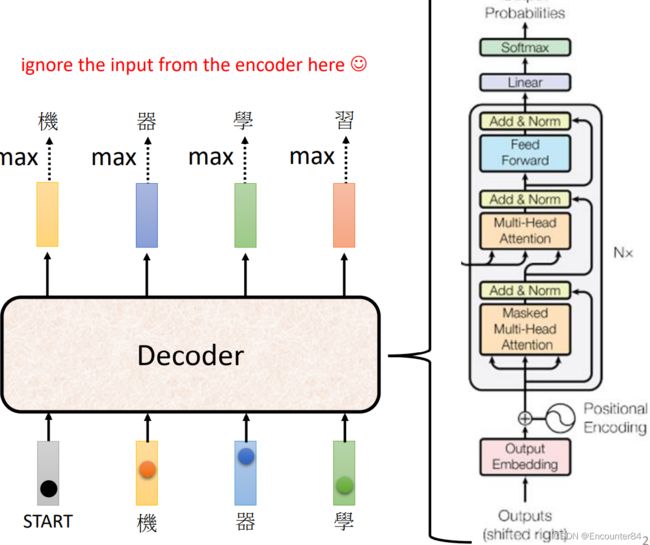
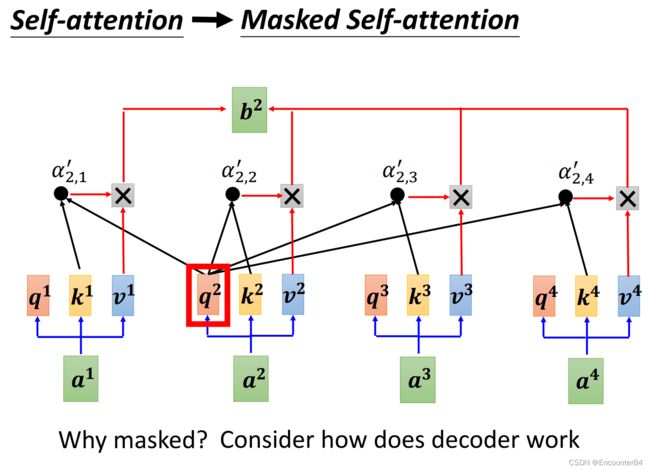
接着我们把Encoder和Decoder放在一起来观察一下,我们发现,如果把Decoder的中间部分遮住的话,其实Decoder的结构和Encoder的结构十分相似。如下图所示。唯一的区别在于Decoder中的多头注意力部分是使用了Masked多头注意力。
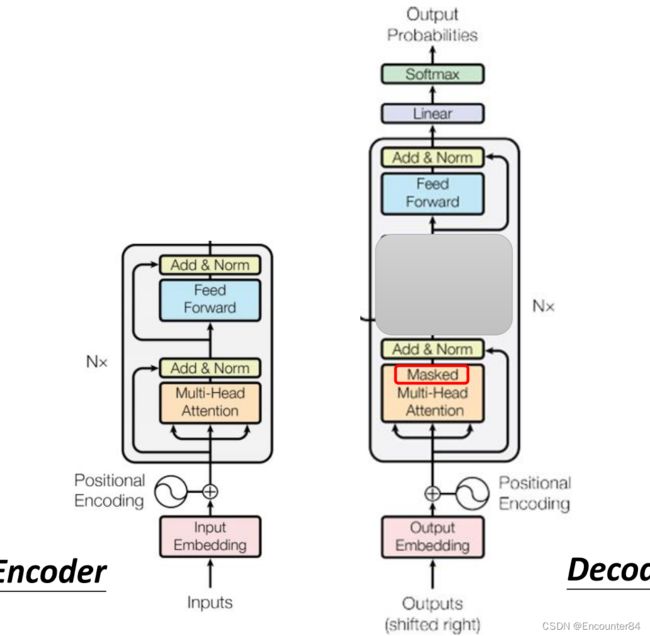
为什么我们要使用Masked多头注意力机制呢?回忆一下Self-attention的计算过程,我们可以发现在计算 b 2 b^2 b2的时候,要用 q 2 q^2 q2和 k 1 k 2 k 3 k 4 k^1k^2k^3k^4 k1k2k3k4分别计算相似度来得到权重矩阵,最后和v相乘。但是在Decoder部分中,使用的是类似于RNN一样的过程,前面的值输出了,再作为下一个值的输入,这样的话,我们没办法同时知道Self-Attention模块的所有输入的KQV矩阵。所以只能使用Masked Self-Attention,在进行 b 2 b^2 b2的输出时,只用 q 2 q^2 q2和 k 1 k 2 k^1k^2 k1k2计算相似度,作为权重计算 a 2 a^2 a2的输出。
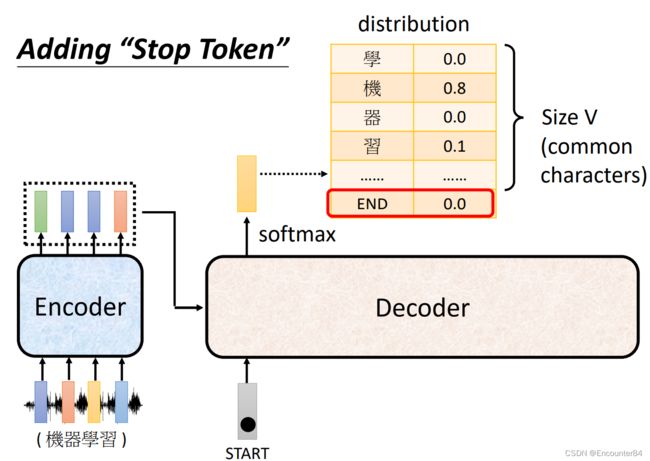
虽然现在我们的Deocder可以输出sequence了,但是还存在一个问题就是,Decoder不知道这个输出的Sequence该在什么时候停下来。理论上来说,如果没有暂停机制的话,Decoder可以一直不停地进行输出。为了解决这个问题,我们建立了一个暂停符号END,他和BOS一起存在于词表中(当然这两个词可以用同一个符号表示,因为BOS只会在Decoder输入的最开始处出现,而END出现在Decoder的输出中)
有了暂停机制,理想情况下,在Decoder的输入部分输入了“习”之后,Decoder输出END,那么这个翻译过程到这里就结束了。
接下来我们介绍一下Encoder和Decoder之间如何传递信息。也就是刚刚的图中被遮起来的部分,从图片中可以看出,这个部分有三个输入,其中两个输入来自于Encoder的输出,另外一个输入是Decoder中第一个多头注意力的输出。接下来我们详细讲解一下该部分的结构。
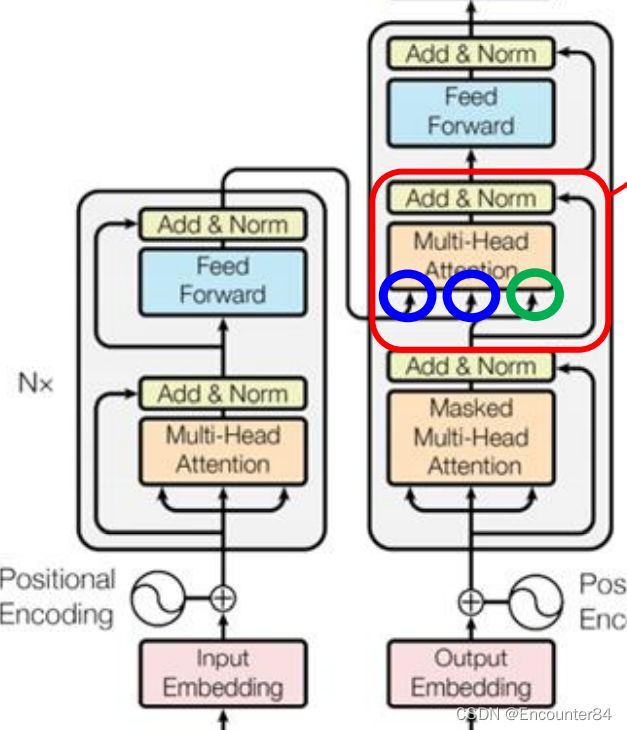
如下图所示,该部分两个来自Encoder部分的输入是Encoder输出矩阵产生的K矩阵和V矩阵,来自Decoder部分的输入是Self-Attention输出矩阵产生的Q矩阵。其中,Q与K矩阵计算相似度产生权重矩阵,然后与V矩阵相乘得到Attention的结果,作为下一个FC层的输入。这个步骤也叫做Cross attention。
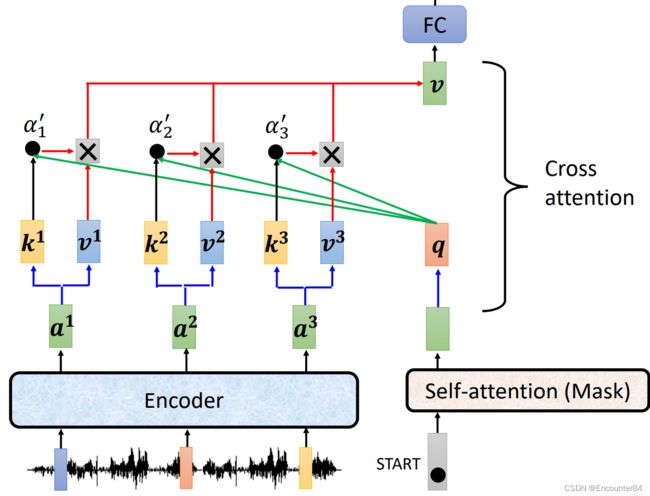
以上,Transformer的结构基本上就清晰了。后续Training时要注意的点在于,损失函数是Decoder输出与Ground Truth之间交叉熵的和。在训练的过程中,要给Decoder的输入提供正确的内容,这个机制被称为Teacher forcing。只有在测试的时候,才让Decoder的输入是上一次的输出。
Transformer代码
关于Transformer的代码,可以参考以下两个链接:Transformer源码1,Transformer源码2,这两个源代码都是根据Transformer的论文顺序实现的,可以在阅读论文的时候理解论文的实现。
Transformer面试常见问题
文章开头部分的问题答案如下:
1.Transformer为何使用多头注意力机制?(为什么不使用一个头)
多头保证了transformer可以注意到不同子空间的信息,捕捉到更加丰富的特征信息。可以类比CNN中同时使用多个卷积核的作用,直观上讲,多头的注意力有助于网络捕捉到更丰富的特征/信息。
在self-attention中,Q=K=V,序列中的每个单词(token)和该序列中其余单词(token)进行attention计算。self-attention的特点在于无视词(token)之间的距离直接计算依赖关系,从而能够学习到序列的内部结构,实现起来也比较简单。
2.Transformer为什么Q和K使用不同的权重矩阵生成,为何不能使用同一个值进行自身的点乘? (注意和第一个问题的区别)
使用Q/K/V不相同可以保证在不同空间进行投影,增强了表达能力,提高了泛化能力。
同时,由softmax函数的性质决定,实质做的是一个soft版本的arg max操作,得到的向量接近一个one-hot向量(接近程度根据这组数的数量级有所不同)。如果令Q=K,那么得到的模型大概率会得到一个类似单位矩阵的attention矩阵,这样self-attention就退化成一个point-wise线性映射。这样至少是违反了设计的初衷。
请求和键值初始为不同的权重是为了解决可能输入句长与输出句长不一致的问题。并且假如QK维度一致,如果不用Q,直接拿K和K点乘的话,你会发现attention score 矩阵是一个对称矩阵。因为是同样一个矩阵,都投影到了同样一个空间,所以泛化能力很差。
3.Transformer计算attention的时候为何选择点乘而不是加法?两者计算复杂度和效果上有什么区别?
K和Q的点乘是为了得到一个attention score 矩阵,用来对V进行提纯。K和Q使用了不同的W_k, W_Q来计算,可以理解为是在不同空间上的投影。正因为有了这种不同空间的投影,增加了表达能力,这样计算得到的attention score矩阵的泛化能力更高。
为了计算更快。矩阵加法在加法这一块的计算量确实简单,但是作为一个整体计算attention的时候相当于一个隐层,整体计算量和点积相似。在效果上来说,从实验分析,两者的效果和dk相关,dk越大,加法的效果越显著。
4.为什么在进行softmax之前需要对attention进行scaled(为什么除以dk的平方根),并使用公式推导进行讲解
这取决于softmax函数的特性,如果softmax内计算的数数量级太大,会输出近似one-hot编码的形式,导致梯度消失的问题,所以需要scale
那么至于为什么需要用维度开根号,假设向量q,k满足各分量独立同分布,均值为0,方差为1,那么qk点积均值为0,方差为dk,从统计学计算,若果让qk点积的方差控制在1,需要将其除以dk的平方根,是的softmax更加平滑
5.在计算attention score的时候如何对padding做mask操作?
padding位置置为负无穷(一般来说-1000就可以),再对attention score进行相加。
6.为什么在进行多头注意力的时候需要对每个head进行降维?(可以参考上面一个问题)
将原有的高维空间转化为多个低维空间并再最后进行拼接,形成同样维度的输出,借此丰富特性信息
基本结构:Embedding + Position Embedding,Self-Attention,Add + LN,FN,Add + LN
7.为何在获取输入词向量之后需要对矩阵乘以embedding size的开方?意义是什么?
embedding matrix的初始化方式是xavier init,这种方式的方差是1/embedding size,因此乘以embedding size的开方使得embedding matrix的方差是1,在这个scale下可能更有利于embedding matrix的收敛。
8.简单介绍一下Transformer的位置编码?有什么意义和优缺点?
因为self-attention是位置无关的,无论句子的顺序是什么样的,通过self-attention计算的token的hidden embedding都是一样的,这显然不符合人类的思维。因此要有一个办法能够在模型中表达出一个token的位置信息,transformer使用了固定的positional encoding来表示token在句子中的绝对位置信息。
9.你还了解哪些关于位置编码的技术,各自的优缺点是什么?(参考上一题)
相对位置编码(RPE)1.在计算attention score和weighted value时各加入一个可训练的表示相对位置的参数。2.在生成多头注意力时,把对key来说将绝对位置转换为相对query的位置3.复数域函数,已知一个词在某个位置的词向量表示,可以计算出它在任何位置的词向量表示。前两个方法是词向量+位置编码,属于亡羊补牢,复数域是生成词向量的时候即生成对应的位置信息。
10.简单讲一下Transformer中的残差结构以及意义。
就是ResNet的优点,解决梯度消失
11.为什么transformer块使用LayerNorm而不是BatchNorm?LayerNorm 在Transformer的位置是哪里?
LN:针对每个样本序列进行Norm,没有样本间的依赖。对一个序列的不同特征维度进行Norm
CV使用BN是认为channel维度的信息对cv方面有重要意义,如果对channel维度也归一化会造成不同通道信息一定的损失。而同理nlp领域认为句子长度不一致,并且各个batch的信息没什么关系,因此只考虑句子内信息的归一化,也就是LN。
12.简答讲一下BatchNorm技术,以及它的优缺点。
优点:
第一个就是可以解决内部协变量偏移,简单来说训练过程中,各层分布不同,增大了学习难度,BN缓解了这个问题。当然后来也有论文证明BN有作用和这个没关系,而是可以使损失平面更加的平滑,从而加快的收敛速度。
第二个优点就是缓解了梯度饱和问题(如果使用sigmoid激活函数的话),加快收敛。
缺点:
第一个,batch_size较小的时候,效果差。这一点很容易理解。BN的过程,使用 整个batch中样本的均值和方差来模拟全部数据的均值和方差,在batch_size 较小的时候,效果肯定不好。
第二个缺点就是 BN 在RNN中效果比较差。
13.简单描述一下Transformer中的前馈神经网络?使用了什么激活函数?相关优缺点?
ReLU
14.Encoder端和Decoder端是如何进行交互的?(在这里可以问一下关于seq2seq的attention知识)
Cross Self-Attention,Decoder提供Q,Encoder提供K,V
15.Decoder阶段的多头自注意力和encoder的多头自注意力有什么区别?(为什么需要decoder自注意力需要进行 sequence mask)
让输入序列只看到过去的信息,不能让他看到未来的信息
16.Transformer的并行化提现在哪个地方?Decoder端可以做并行化吗?
Encoder侧:模块之间是串行的,一个模块计算的结果做为下一个模块的输入,互相之前有依赖关系。从每个模块的角度来说,注意力层和前馈神经层这两个子模块单独来看都是可以并行的,不同单词之间是没有依赖关系的。
Decode引入sequence mask就是为了并行化训练,Decoder推理过程没有并行,只能一个一个的解码,很类似于RNN,这个时刻的输入依赖于上一个时刻的输出。
17.简单描述一下wordpiece model 和 byte pair encoding,有实际应用过吗?
传统词表示方法无法很好的处理未知或罕见的词汇(OOV问题),传统词tokenization方法不利于模型学习词缀之间的关系”
BPE(字节对编码)或二元编码是一种简单的数据压缩形式,其中最常见的一对连续字节数据被替换为该数据中不存在的字节。后期使用时需要一个替换表来重建原始数据。
优点:可以有效地平衡词汇表大小和步数(编码句子所需的token次数)。
缺点:基于贪婪和确定的符号替换,不能提供带概率的多个分片结果。
18.Transformer训练的时候学习率是如何设定的?Dropout是如何设定的,位置在哪里?Dropout 1在测试的需要有什么需要注意的吗?
Dropout测试的时候记得对输入整体呈上dropout的比率
19.引申一个关于bert问题,bert的mask为何不学习transformer在attention处进行屏蔽score的技巧?
BERT和transformer的目标不一致,bert是语言的预训练模型,需要充分考虑上下文的关系,而transformer主要考虑句子中第i个元素与前i-1个元素的关系。