(十)将PositionRank模型运行到给定数据集上(二)
2021SC@SDUSC
难点二:中文文本处理
文章目录
- 难点二:中文文本处理
-
- 任务分解
- 关于nltk
- 尝试使用jieba库进行中文处理
- 使用StanfordNLP
-
- 简介
- 安装
- 测试
- 小结
任务分解
在positionrank中对于输入text的处理主要包括分句、分词、词干还原、词性标注,在迁移到中文中时,需要去除词干还原模块同时将其他模块的使用迁移到中文。
关于nltk
在源码分析时注意到nltk的很多方法都开源指定语言,然而在指定语言为chinese后发现提示找不到相关文件。
![]()
阅读源码发现,nltk会将language参数生成文件路径名,然后在nltk_data中寻找该文件,然而nltk_data中并没有chinese.pickle。
在网络上寻找中文相关的语料库,**只发现了针对繁体中文进行处理的sinica_treebank。**于是问题进一步拓展,需要修改doc_candidate中的相关代码,使其可以针对中文进行处理。首先想到的是使用jieba库。
尝试使用jieba库进行中文处理
示例代码
import jieba.posseg
text = '我是一个粉刷匠,粉刷本领强。'
pr = jieba.posseg.lcut(text)
for word ,f in pr:
print("{}……词性:{}".format(word,f))
结果:

其中的中文词性标记和position中使用的POS_Tag(POS Tagging 标签类型查询表(Penn Treebank Project) - creatures-of-habit - 博客园 (cnblogs.com))**并不一致,**当然可以采取映射的方式进行处理,但是考虑到二者类与类之间的细微差别,为了防止对结果造成影响,我倾向使用具有相同标签的nlp库。
使用StanfordNLP
简介
StanfordCoreNLP提供了一系列用于自然语言的技术工具,可以用于中文。它可以给出不管是公司名还是人名亦或标准化日期、时间和数量等单词的基本形式,词性等。如下图所示它还可以根据短语和句法依存关系标记句子结构,指明哪些名词短语表示相同的实体,指明情感,提取实体及之间的特定或开放类关系,获取名人名言等等。
安装
1.pip install stanfordnlp
2.pip install stanfordcorenlp
3.下载https://stanfordnlp.github.io/CoreNLP/的CoreNLP以及模型jar包,这里下载了英文和中文模型jar包。
4.将jar包放到解压缩后的coreNLP的文件夹。
完成上述操作运行代,出现如下错误
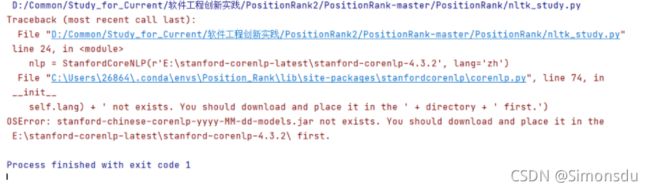
提示未找到相应的jar包。
对代码进行debug,报错位置如下:
# Check if the language specific model file exists
switcher = {
'en': 'stanford-corenlp-[0-9].[0-9].[0-9]-models.jar',
'zh': 'stanford-chinese-corenlp-[0-9][0-9][0-9][0-9]-[0-9][0-9]-[0-9][0-9]-models.jar',
'ar': 'stanford-arabic-corenlp-[0-9][0-9][0-9][0-9]-[0-9][0-9]-[0-9][0-9]-models.jar',
'fr': 'stanford-french-corenlp-[0-9][0-9][0-9][0-9]-[0-9][0-9]-[0-9][0-9]-models.jar',
'de': 'stanford-german-corenlp-[0-9][0-9][0-9][0-9]-[0-9][0-9]-[0-9][0-9]-models.jar',
'es': 'stanford-spanish-corenlp-[0-9][0-9][0-9][0-9]-[0-9][0-9]-[0-9][0-9]-models.jar'
}
jars = {
'en': 'stanford-corenlp-x.x.x-models.jar',
'zh': 'stanford-chinese-corenlp-yyyy-MM-dd-models.jar',
'ar': 'stanford-arabic-corenlp-yyyy-MM-dd-models.jar',
'fr': 'stanford-french-corenlp-yyyy-MM-dd-models.jar',
'de': 'stanford-german-corenlp-yyyy-MM-dd-models.jar',
'es': 'stanford-spanish-corenlp-yyyy-MM-dd-models.jar'
}
if len(glob.glob(directory + switcher.get(self.lang))) <= 0:
raise IOError(jars.get(
self.lang) + ' not exists. You should download and place it in the ' + directory + ' first.')
glob方法返回值小于长度等于0,引起该错误。于是我查找了glob方法的相关内容,glob.glob()返回与参数匹配的列表,列表内容是文件相应路径名。因此可以看出,glob方法没有检索到符合条件的文件。
再次回到代码,可以看到匹配的路径未为“‘zh’: ‘stanford-chinese-corenlp-[0-9][0-9][0-9][0-9]-[0-9][0-9]-[0-9][0-9]-models.jar’,”
然而下载的jar包名称为:
![]()
显然二者无法匹配,将该jar包重命名为:
![]()
再次运行,错误消失。关于这个错误,我花费了大量时间,因为所有操作都按照stanford官方文档操作,没有考虑过代码中对于jar包文件名的检索会和官网下载的jar包不一致(有点无语)。
测试
使用如下语句进行测试,再次出现错误。
from stanfordcorenlp import StanfordCoreNLP
nlp = StanfordCoreNLP(r'E:\stanford-corenlp-latest\stanford-corenlp-4.3.2', lang='en')
text = 'I am a srudent'
print(nlp.word_tokenize(text))
Traceback (most recent call last):
File "C:\Users\26864\.conda\envs\Position_Rank\lib\json\decoder.py", line 355, in raw_decode
raise JSONDecodeError("Expecting value", s, err.value) from None
json.decoder.JSONDecodeError: Expecting value: line 1 column 1 (char 0)
定位错误:
def _request(self, annotators=None, data=None, *args, **kwargs):
if sys.version_info.major >= 3:
data = data.encode('utf-8')
properties = {'annotators': annotators, 'outputFormat': 'json'}
params = {'properties': str(properties), 'pipelineLanguage': self.lang}
if 'pattern' in kwargs:
params = {"pattern": kwargs['pattern'], 'properties': str(properties), 'pipelineLanguage': self.lang}
logging.info(params)
r = requests.post(self.url, params=params, data=data, headers={'Connection': 'close'})
r_dict = json.loads(r.text)
r.text内容为空,检查post的结果,提示错误码为500。http请求返回500状态码,整体原因是:服务器内部错误。
也就意味着构建内部服务器出现问题,初始化服务器发生在
nlp = StanfordCoreNLP(r’E:\stanford-corenlp-latest\stanford-corenlp-4.3.2’, lang=‘en’)
然而在pycharm终端中无法看到进程的细节,于是在cmd中打开服务器:
java -mx4g -cp "*" edu.stanford.nlp.pipeline.StanfordCoreNLPServer -port 9000 -timeout 15000

通过网页访问,运行正常:

再次回到pycharm中直接连接已经启动的服务端口。
nlp = StanfordCoreNLP('http://localhost', port=9000)
运行正常:

因此可以明确,问题出现在通过python构造的端口启动语句中:nlp = StanfordCoreNLP(r’E:\stanford-corenlp-latest\stanford-corenlp-4.3.2’, lang=‘en’)。
再次测试针对中文的启动,首先在pycharm中运行,不出意外再次报错。随后按照上诉步骤在cmd中启动,
java -Xmx4g -cp "*" edu.stanford.nlp.pipeline.StanfordCoreNLPServer -serverProperties StanfordCoreNLP-chinese.properties -port 9000 -timeout 15000
打开‘localhost:9000’,运行正常。

问题小结:英文在浏览器直接访问和pycharm中调用相关库都可以正常运行。中文浏览器可以正常访问,但在Pycharm中调用库访问无效。
在服务器中定位错误信息如下:

由于没有服务器部分的源码,我使用Java Decompiler对jar包中的部分.class文件进行了反编译。首先对最直接引起异常的POSTaggerAnnotator.class反编译。定位到如下代码:
public void annotate(Annotation annotation) {
if (annotation.containsKey(CoreAnnotations.SentencesAnnotation.class)) {
if (this.nThreads == 1) {
for (CoreMap sentence : annotation.get(CoreAnnotations.SentencesAnnotation.class))
doOneSentence(sentence);
} else {
MulticoreWrapper<CoreMap, CoreMap> wrapper = new MulticoreWrapper(this.nThreads, new POSTaggerProcessor());
for (CoreMap sentence : annotation.get(CoreAnnotations.SentencesAnnotation.class)) {
wrapper.put(sentence);
while (wrapper.peek())
wrapper.poll();
}
wrapper.join();
while (wrapper.peek())
wrapper.poll();
}
} else {
throw new RuntimeException("unable to find words/tokens in: " + annotation);
}
}
出现问题的是关于annotation(继承自CoreMap)中值的判断。对该部分代码溯源,定位到StanfordNLPServer.class对其反编译,发现出现问题的代码如下:
if (!StanfordCoreNLPServer.this.quiet)
Redwood.Util.log(new Object[] { "[" + httpExchange.getRemoteAddress() + "] API call w/annotators " + props.getProperty("annotators", "" ) });
ann = StanfordCoreNLPServer.this.getDocument(props, httpExchange);
of = StanfordCoreNLP.OutputFormat.valueOf(props.getProperty("outputFormat", "json").toUpperCase(Locale.ROOT));
String text = ((String)ann.get(CoreAnnotations.TextAnnotation.class)).replace('\n', ' ');
if (!StanfordCoreNLPServer.this.quiet)
System.out.println(text);
if (StanfordCoreNLPServer.maxCharLength > 0 && text.length() > StanfordCoreNLPServer.maxCharLength) {
StanfordCoreNLPServer.respondBadInput("Request is too long to be handled by server: " + text.length() + " characters. Max length is " + StanfordCoreNLPServer.maxCharLength + " characters.", httpExchange);
return;
}
} catch (Exception e) {
Redwood.Util.warn(new Object[] { e });
StanfordCoreNLPServer.respondError("Could not handle incoming annotation", httpExchange);
return;
}
Future<Annotation> completedAnnotationFuture = null;
try {
StanfordCoreNLP pipeline = StanfordCoreNLPServer.this.mkStanfordCoreNLP(props);
completedAnnotationFuture = StanfordCoreNLPServer.this.corenlpExecutor.submit(() -> {
pipeline.annotate(ann);
return ann;
});
倒数第二行’pipeline.annotate(ann);‘引起该错误。然而在一系列的处理中并未涉及对于annotation中key的修改,因此annotation值的变化只能出现在对annotation的构造中。同时注意到StanfordNLPServer中有针对不同情况的handle方法,猜测在不同handle中对于annotation初始化了不同的key。之所以出现问题,是因为初始化的key和在进行处理时的key检验出现冲突,也就意味着对于某个annotation调用了错误的handle方法(通过构造不同的HttpContext和相应HttpHandler绑定实现)。
再次回到客户端的请求方法,针对不同的处理类型在客户端使用annotators字典区分,例如为了实现分词:‘annotators’: [‘ssplit,tokenize’]。然而在StanfordNLPServer中handle方法对于key值的检验遵循规定的顺序(事先构造了词典),
private static Map<String, BiFunction<Properties, AnnotatorImplementations, Annotator>> getNamedAnnotators() {
Map<String, BiFunction<Properties, AnnotatorImplementations, Annotator>> pool = new HashMap<>();
pool.put("cdc_tokenize", (props, impl) -> impl.cdcTokenizer(props));
pool.put("cleanxml", (props, impl) -> impl.cleanXML(props));
pool.put("ssplit", (props, impl) -> impl.wordToSentences(props));
pool.put("tokenize", (props, impl) -> impl.tokenizer(props));
pool.put("mwt", (props, impl) -> impl.multiWordToken(props));
pool.put("docdate", (props, impl) -> impl.docDate(props));
pool.put("pos", (props, impl) -> impl.posTagger(props));
pool.put("lemma", (props, impl) -> impl.morpha(props, false));
pool.put("ner", (props, impl) -> impl.ner(props));
pool.put("tokensregex", (props, impl) -> impl.tokensregex(props, "tokensregex"));
pool.put("regexner", (props, impl) -> impl.tokensRegexNER(props, "regexner"));
pool.put("entitymentions", (props, impl) -> impl.entityMentions(props, "entitymentions"));
pool.put("gender", (props, impl) -> impl.gender(props, "gender"));
pool.put("truecase", (props, impl) -> impl.trueCase(props));
pool.put("parse", (props, impl) -> impl.parse(props));
pool.put("coref.mention", (props, impl) -> impl.corefMention(props));
pool.put("dcoref", (props, impl) -> impl.dcoref(props));
pool.put("coref", (props, impl) -> impl.coref(props));
pool.put("relation", (props, impl) -> impl.relations(props));
pool.put("sentiment", (props, impl) -> impl.sentiment(props, "sentiment"));
pool.put("cdc", (props, impl) -> impl.columnData(props));
pool.put("depparse", (props, impl) -> impl.dependencies(props));
pool.put("natlog", (props, impl) -> impl.natlog(props));
pool.put("openie", (props, impl) -> impl.openie(props));
pool.put("quote", (props, impl) -> impl.quote(props));
pool.put("quote.attribution", (props, impl) -> impl.quoteattribution(props));
pool.put("udfeats", (props, impl) -> impl.udfeats(props));
pool.put("entitylink", (props, impl) -> impl.link(props));
pool.put("kbp", (props, impl) -> impl.kbp(props));
return pool;
}
然而进行检验时将Map中的key转为有序数组,当annotators中标识的顺序和数组中关于标识符的顺序不一致时也会引起异常。
尝试将’annotators’: [‘ssplit,tokenize’]替换为’annotators’: [‘tokenize,ssplit’],错误消失。

(以后少用最新版的依赖库,可能存在bug并且网上缺少解决方案。这个很小的问题我从早上十点一直搞到晚上十点才解决。)
小结
至此我已经克服了该问题的两个主要难点。下一步将对源码中的nltk进行替换,从而实现在给定数据集上运行PositionRank的目的。