利用R语言Tidymodel包,对随机森林R语言实现
本人也是才学习tidymodel包,运用其中的随机森林引擎,完成随机森林算法的R语言实现。
数据简介
本文利用的数据是随机数据,只是为了实现运行的“工具人数据罢了”,如果想进一步印证代码,可以在下方下载我的数据,不过没必要其实~
不多废话,直接上代码,我也是在学习,代码仅供参考,肯定不够完善,可以提出宝贵的建议,感谢。
随机森林R语言实现
再重申一下,完全可以用R自带的randomForest包实现,但是本文只用tidymodel实现。除此之外,建议读者自行了解下tibble数据科学类型。
###
rm(list = ls())
warnings('off')
###
install.packages("tidymodel")
install.packages("tidyverse")
tidymodels_prefer()导入数据集并划分训练集和测试集
#数据集
setwd("C:/Users/Administrator/Desktop/R语言学习")
data1<-read.csv("例子.csv",header=T)
lizi<- data1 %>%
drop_na()%>%
transform(V12 = factor(V12))%>%
as_tibble()
lizi
#划分训练集和测试集
set.seed(1234)
data_split <- initial_split(lizi, prop = 7/10, strata = V12)
data_train <- training(data_split)
data_test <- testing(data_split)
这里我要着重强调
transform(V12 = factor(V12))%>%
#注意类别那一栏的数据一定是factor类型,并且不能只用as_tibble来转换,因为as_tibble只能转单个数据,但是不能直接转整列,很关键,否则后面的函数有报错。
创建食谱
#创建食谱
lizi_recipe<-
recipe(V12 ~ ., data = data_train)
lizi_recipe
建立模型
#建模
rand_forest_randomForest_spec <-
rand_forest(mtry=tune(), trees=tune()) %>%
set_engine('randomForest') %>%
set_mode('classification')
rand_forest_randomForest_spec 这里顺便教一下,怎么查看tidymodel支持的算法,并且直接使用包里的标准代码
1.addins -选择Generate parship model specifications

2.选择需要的算法模型

比如我选的随机森林后,点击下方绿色按钮就会生成
rand_forest_randomForest_spec <-
rand_forest(mtry = tune(), min_n = tune()) %>%
set_engine('randomForest') %>%
set_mode('classification')
其中mtry = tune(), min_n = tune()两个参数需要后面经过调参确定,不过随机森林主要的参数我用的是mtry和trees
建立工作流
rand_forest_randomForest_workflow <-
workflow() %>%
add_recipe(lizi_recipe)%>%
add_model(rand_forest_randomForest_spec)
rand_forest_randomForest_workflow
交叉验证
#交叉验证
tree_folds<-vfold_cv(data_train,v=5)
tree_folds
交叉验证不是本文的主要内容,读者可以自行学习哈,这里我设置的五折
调参
#调参
tree_grid <- grid_regular(mtry(range=c(5L,10L)),trees(range=c(500L,1000L)), levels = c(mtry=5,trees=6))
tree_grid
tree_rs <-
tune_grid(
object=rand_forest_randomForest_workflow,
resamples = tree_folds,
grid = tree_grid
)
这里注意的是level的参数,这是为了让机器估计最优的mtry和trees的组合。

如图所示,依照这样的组合,总共会计算6*6=36次,估计最优的mtry和trees组合,tidymodel比较方便的是,程序会自己寻找最优的组合,不需要我们自己查看,不过也能自己查看。
autoplot(tree_rs)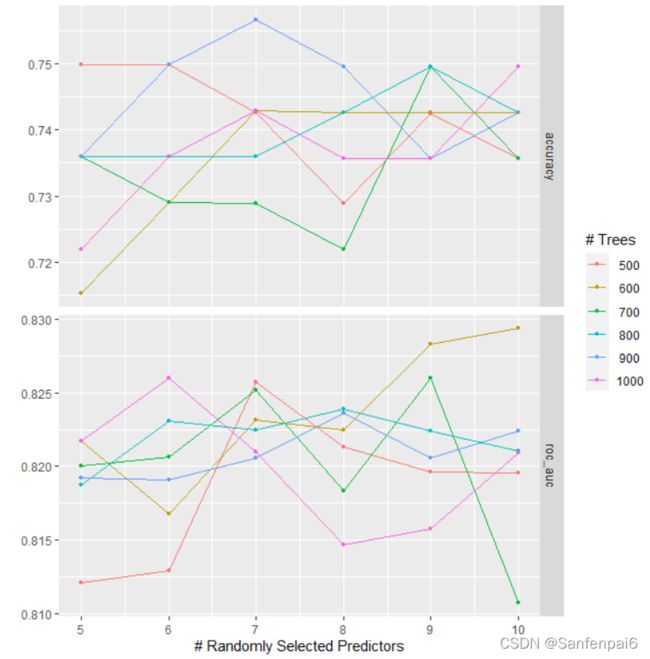
这是计算的每个组合的AUC值和accura值,画出的折线图,要是想自己查看准确数值,
collect_metrics(tree_rs)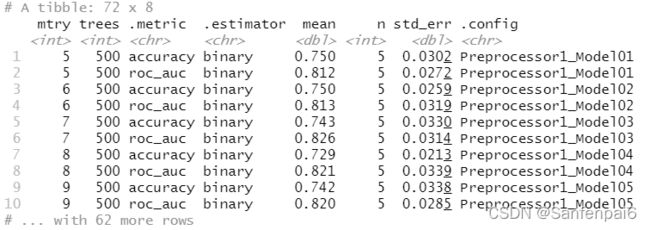
以下就是我说的程序识别最优的组合,
show_best(tree_rs)
best_param<-select_best(tree_rs,metric ="accuracy") #记录下最优的组合对应的参数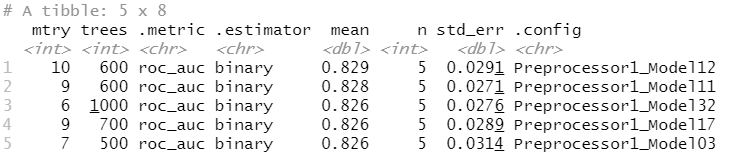
可以看到有五个组合都是相近的,利用best_param可以得到最好的那个。
拟合模型
#拟合模型
lizi_final<-
rand_forest_randomForest_workflow%>%
finalize_workflow(best_param)%>%
fit(data=data_train)没啥说的,引入工作流,然后再导入刚才选好的参数,对训练集进行分类。
预测并且评估模型
#预测
bind_cols(
predict(lizi_final, data_test),
predict(lizi_final, data_test, type = "prob")
)
#评估
lizi_final %>%
augment(new_data = data_test) %>%
accuracy(truth=V12, estimate = .pred_class)

评估模型可以看到,模型是由75%的准确率的,大概就是这样啦。
应用模型对需要分类的数据分类
#应用
data2<-read.csv("例子_分类.csv",header=T)
lizi_fenlei<- data2 %>%
transform(V12 = factor(V12))%>% #还是对V12转成factor类型
as_tibble()
lizi_fenlei
#对待分类的数据分类
fenlei<-
bind_cols(
predict(lizi_final, lizi_fenlei),
predict(lizi_final, lizi_fenlei, type = "prob")
)
data2$V12=fenlei$.pred_class #查看分类结果
#结果保存为excel
write.csv(data2, file = "fenlei_result.csv")
library(openxlsx)
sheets = list("result" = data2)
write.xlsx(sheets,"fenlei_result.xlsx") 
把结果保存到excel方便查看。
小结
大概就是这么个过程,有问题欢迎提问,不过我也刚接触,读者可以多查查,然后一起交流,感谢~数据和结果可以自己下载。
分享一个学习tidymodel的网站,好像是作者团队的。Tidymodels